标签:结构化 img 分支 空间 输入 缺点 text justify 支持
支持向量机
支持向量机是一种二分类机器学习模型,适用于小样本数据集。
下面通过建模,优化方法求解,支持向量机在多分类问题的应用以及支持向量机优缺点四个方面讲:
第一部分:建模
一.线性可分支持向量机:若数据样本线性可分,通过极大化所有样本点的几何间隔最小值,将极大化问题转变成极小化问题之后,得到线性可分支持向量机学习的最优化问题:

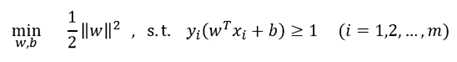
原始问题为凸二次规划问题,求解可以根据现成优化工具求解。由于模型的特殊结构,往往采用对偶的方式求解。使用对偶的优点有三:①对偶问题求解更为高效;②对偶问题方便了核函数的引进,用于对非线性可分问题进行分类;③对偶问题可求得支持向量。
对偶问题格式为:
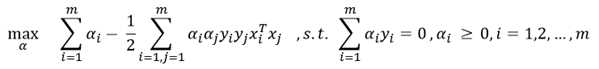
二.软间隔线性支持向量机
由于噪声等等原因,现实中数据往往不是那么完美的线性可分。
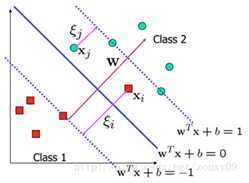
但如果除去离群点(outlier)后数据仍然近似线性可分,可对离群点采取松弛变量的方法进行处理,即利用罚函数的方法对错误点进行惩罚,这样就有了软间隔线性支持向量机模型:
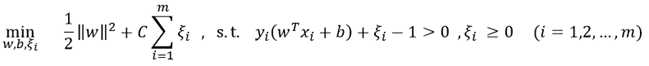
这种形式的模型实际上是基于合页损失函数的软间隔支持向量机:
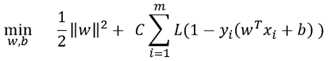
其中L取合页损失函数.
合页损失函数支持向量机优点在于惩罚具有稀疏性,缺点在于会对于离群比较严重的点赋予很大的权重,可能会对分隔超平面产生巨大的影响。对于函数L的不同取法已有很多研究,这里不再深入。
由于同样的原因,也写出其对偶问题进行求解:
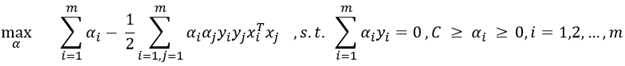
三.非线性支持向量机
当数据是非线性可分的时候,可以采用加入核函数的方法,用一个非线性映射将所有样本点投影到另一个特征空间,使得在新的空间数据是线性可分的。
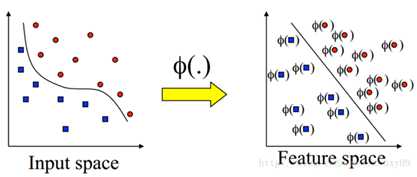
由于支持向量机模型的对偶问题在训练和使用时都使用到了样本特征的内积,希望可以找到一种方法来计算两个样本映射到高维空间后的内积的值,这种方法就是核函数:
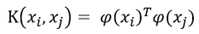
原始模型为:
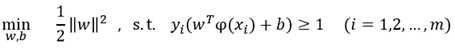
对偶问题:
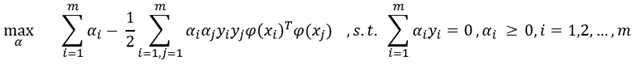
常用的核函数有线性核函数:
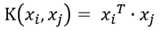
线性核函数主要用于线性可分的情况,我们可以看到特征空间到输入空间的维度是一样的,其参数少速度快,对于线性可分数据,其分类效果很理想,因此我们通常首先尝试用线性核函数来做分类,看看效果如何,如果不行再换别的;
高斯核函数(径向基核函数RBF):
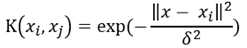
高斯径向基函数是一种局部性强的核函数,其可以将一个样本映射到一个更高维的空间内,该核函数是应用最广的一个,无论大样本还是小样本都有比较好的性能,而且其相对于多项式核函数参数要少,因此大多数情况下在不知道用什么核函数的时候,优先使用高斯核函数。
以及多项式核函数,sigmoid核函数等。
至于怎么选择核函数,吴恩达的课曾提出过核函数选择方法:如果特征的数量大到和样本数量差不多,则选用LR或者线性核的SVM,如果特征的数量小,样本的数量正常,则选用SVM+高斯核函数。
第二部分:优化
求解支持向量机模型,即求解一个典型的凸二次规划问题,由于求解该二次规划问题涉及到m阶矩阵的计算(m为样本个数),当m数量较大时难以储存和计算。针对该问题的改进算法有很多,典型的就是序列最小最优化算法SMO。SMO算法采取一种类似于坐标下降的方法,每次固定α中n-2个变量,只更新其余两个,这样把对全部的α优化问题变成了一对对的参数的优化问题,再通过解析解的方法确定这一对α。因为最优解α一定满足kkt条件,当把所有的α的分量都优化到满足kkt条件时,便可以得到最优的α值。
第三部分:多分类问题
原始支持向量机模型只能解决二分类问题,而现实中常有多分类的需求,解决方法大致有三种:
第四部分:优缺点
优点:
缺点:
标签:结构化 img 分支 空间 输入 缺点 text justify 支持
原文地址:https://www.cnblogs.com/yuanzhengpeng/p/9672253.html