标签:完全 fail 安装包 ext 训练 执行 open ocr init
一、安装:
选择对应版本,https://digi.bib.uni-mannheim.de/tesseract/
1:下载安装包
根据https://github.com/tesseract-ocr/tesseract/wiki,我找到非官方的安装包,好像我只看到64位的安装包http://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-4.00.00dev.exe,下载后直接安装即可,但是要记得你的安装目录,我们等会配置环境变量要用。
如果不是做英文的图文识别,还需要下载其他语言的识别包https://github.com/tesseract-ocr/tesseract/wiki/Data-Files。
简体字识别包:https://raw.githubusercontent.com/tesseract-ocr/tessdata/4.00/chi_sim.traineddata
繁体字识别包:https://github.com/tesseract-ocr/tessdata/raw/4.0/chi_tra.traineddata
2:安装
直接执行下载好的tesseract-ocr-setup-4.00.00dev.exe,下一步、下一步安装。
3:配置环境变量
打开命令终端,输入:tesseract -v,可以看到版本信息
到这里,我们就算安装完成了,但是,我们的系统还是无法识别中文的,我们要去下载简体汉字、繁体汉字语言包(上文给了地址了),语言包是放在 tessdata文件下即可。
问题解决:
在windows下安装成功之后,进行tesseract的操作,碰到如下错误信息: E:\testdir>tesseract test.png test1 -l eng Error opening data file \Program Files (x86)\Tesseract-OCR\tessdata/eng.traineddata Please make sure the TESSDATA_PREFIX environment variable is set to the parent directory of your "tessdata" directory. Failed loading language ‘eng‘ Tesseract couldn‘t load any languages! Could not initialize tesseract. 错误信息的关键词是tesseract_prefix的环境变量设置。
解决办法: 找到testData所在的目录,默认情况下是在tesseract安装的目录,在环境变量中设置TESSDATA_PREFIX的环境变量为testdata所在的目录即可。
增加一个TESSDATA_PREFIX变量名,变量值还是我的安装路径C:\Program Files (x86)\Tesseract-OCR;
重新运行命令即可正常使用。
参考:https://blog.csdn.net/blueheart20/article/details/53207176?utm_source=copy
二、识别
1、进入cmd,进入到要识别的图片的路径下。
2、输入命令
tesseract 图片名称 生成的结果文件的名称 字库
例如:
tesseract test.jpg result -l chi_sim
识别完后会生成result.txt文件
当然啦效果不太理想。所以我们要训练自己的字库。
三、训练
1、将图片转换成tif格式,用于后面生成box文件。可以通过画图,然后另存为tif即可。
更改图片名字,这个是有要求的=。=
tif文面命名格式[lang].[fontname].exp[num].tif
lang是语言 fontname是字体
比如我们要训练自定义字库 mjorcen字体名normal
那么我们把图片文件重命名 mjorcen.normal.exp0.jpg在转tif。
2、生成box文件。
|
1
|
tesseract mjorcen.normal.exp0.jpg mjorcen.normal.exp0 -l chi_sim batch.nochop makebox |
box文件和对应的tif一定要在相同的目录下,不然后面打不开。
3、打开jTessBoxEditor矫正错误并训练
打开train.bat
找到tif图,打开,并校正。
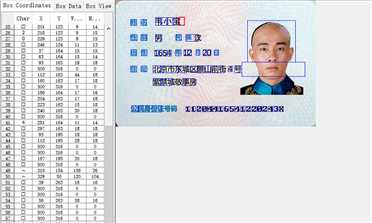
问题:
最初在jTessBoxEditor中,所有中文字体都显示乱码(方框),只需要的设置中,将字体修改成【宋体】就没问题了 。
4、训练。
只要在命令行输入命令即可。
|
1
|
tesseract mjorcen.normal.exp0.jpg mjorcen.normal.exp0 nobatch box.train |
|
1
|
unicharset_extractor mjorcen.normal.exp0.box |
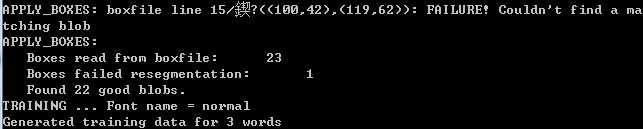
在这我明明已经矫正好了,但是还是有1个字符不能识别出来,报的错跟实际上完全没有相关性,不知道是不是bug,到后面的结果就是“园”字没有识别出来。
先不管,毕竟只有一个样本。
新建一个font_properties文件
里面内容写入 normal 0 0 0 0 0 表示默认普通字体
继续敲命令
|
1
2
3
4
5
6
7
8
9
|
shapeclustering -F font_properties -U unicharset mjorcen.normal.exp0.trmftraining -F font_properties -U unicharset -O unicharset mjorcen.normal.exp0.trcntraining mjorcen.normal.exp0.tr |
最后会生成五个文件,把目录下的unicharset、inttemp、pffmtable、shapetable、normproto这五个文件前面都加上normal.
如图:

命令行输入,合并五个文件:
|
1
|
combine_tessdata normal. |
得到训练好的字库。

四、测试
1、把 normal.traineddata 复制到Tesseract-OCR 安装目录下的tessdata文件夹中
2、识别命令:
|
1
|
tesseract mjorcen.normal.exp0.jpg mjorcen.normal.exp0 -l normal |
3、效果
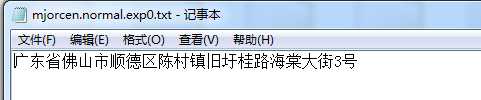
对比:
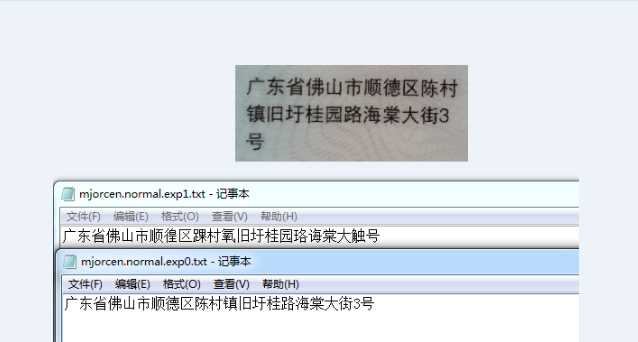
总结:
jTessBoxEditor 是正常可用的,单是在校正训练的时候,定位文本的框不好调整,只能进行插入、删除、合并操作
不能对位置进行改变。这样对于训练来说很难得到比较好的分割文字,会产生不好的影响。
参考:http://www.cnblogs.com/wzben/p/5930538.html
http://www.cnblogs.com/jianqingwang/p/6978724.html
Win10 环境安装tesseract-ocr 4.00并配置环境变量
标签:完全 fail 安装包 ext 训练 执行 open ocr init
原文地址:https://www.cnblogs.com/Allen-rg/p/9696024.html