标签:lead osal 概率 进入 lock 结果 inf 本地 image
上篇文章paxos与一致性说到zab是在paxos的基础上做了重要的改造,解决了一系列的问题,这一篇我们就来说下这个zab。
zab协议的全称是ZooKeeper Atomic Broadcast即zookeeper“原子”“广播”协议。它规定了两种模式:崩溃恢复和消息广播
什么时候进入?
这三种情况ZAB都会进入恢复模式
干了什么?
选举产生新的Leader服务器,同时集群中已有的过半的机器会与该Leader完成状态同步,这些工作完成后,ZAB协议就会退出崩溃恢复模式
什么时候进入?
集群状态稳定,有了leader且过半机器状态同步完成,退出崩溃恢复模式后进入消息广播模式
干了什么?
正常的消息同步,把日常产生数据从leader同步到learner的过程
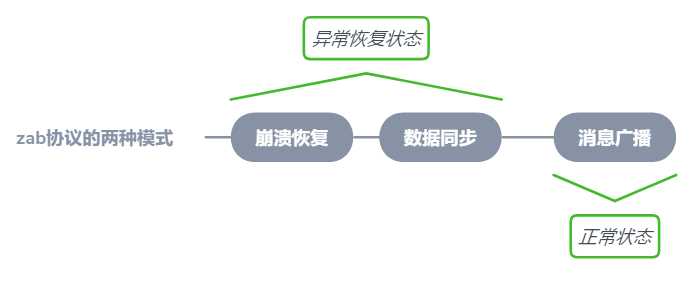
总结一下zab协议规定的两种模式在实际操作中经历了三个步骤,如上图,下面我再详细地说下这两个过程都干了些什么
进入崩溃恢复模式说明集群目前是存在问题的了,那么此时就需要开始一个选主的过程。
zookeeper使用的默认选主算法是FastLeaderElection,它是标准的Fast Paxos算法实现,可解决LeaderElection选举算法收敛速度慢的问题(上篇文章也有提到过)。
LOOKING 当前集群没有leader,准备选举
FOLLOWING 已经存在leader,当前服务器为跟随者
LEADING 唯一的领导,维护与Follower间的心跳
OBSERVING 观察者状态。表明当前服务器角色是Observer
投票流程
投票的依据就是下面的两个id,投票即是给所有服务器发送(myid,zxid)信息
myid:用户在配置文件中自己配置,每个节点都要配置的一个唯一值,从1开始往后累加。
zxid:zxid有64位,分成两部分:
高32位是Leader的epoch:选举时钟,每次选出新的Leader,epoch累加1
低32位是在这轮epoch内的事务id:对于用户的每一次更新操作集群都会累加1。
注意:zk把epoch和事务id合在一起,每次epoch变化,都将低32位的序号重置,这样做是为了方便对比出最新的数据,保证了zxid的全局递增性。(其实这样也会存在问题,虽然概率小,这里就先不说了后面的文章会详细讲)。
第一轮投给自己,之后每个服把上述所有信息发送给其他所有服,票箱中只会记录每一投票者的最后一票
服务器会尝试从其它服务器获取投票,并记入自己的投票箱内。如果无法获取任何外部投票,则会确认自己是否与集群中其它服务器保持着有效连接。如果是,则再次发送自己的投票;如果否,则马上与之建立连接。
由于所有有效的投票都必须在同一轮次中。每开始新一轮投票自身的logicClock自增1。
对比自身的和接收到的(myid,zxid)
关于选举结束
过半服务器选了同一个,则投票结束,根据投票结果更新自身状态为leader或者follower
上面说过zookeeper是一个原子广播协议,在这个崩溃恢复的过程就体现了它的原子性,zookeeper在选主过程保证了两个问题:
(myid,zxid)的选票设计刚好解决了这两个问题。
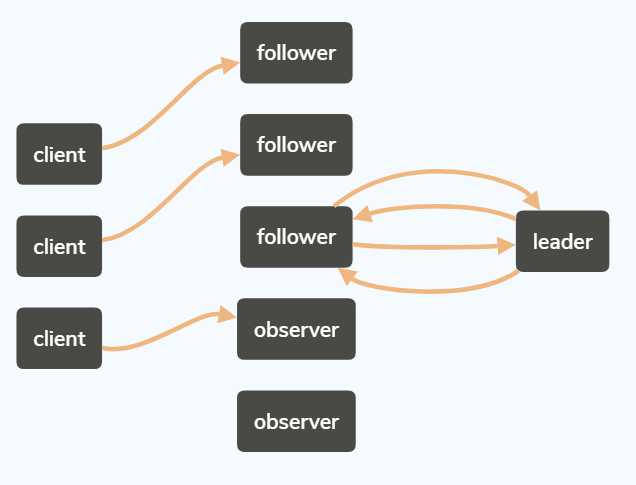
如上图,client端发起请求,读请求由follower和observer直接返回,写请求由它们转发给leader。
Leader 首先为这个事务分配一个全局单调递增的唯一事务ID (即 ZXID )。
然后发起proposal给follower,Leader 会为每一个 Follower 都各自分配一个单独的队列,然后将需要广播的事务 Proposal 依次放入这些队列中去,并且根据 FIFO策略进行消息发送。
每一个 Follower 在接收到这个事务 Proposal 之后,都会首先将其以事务日志的形式写入到本地磁盘中去,并且在成功写入后反馈给 Leader 服务器一个 Ack 响应。
当 Leader 服务器接收到超过半数 Follower 的 Ack 响应后,就会广播一个Commit 消息给所有的 Follower 服务器以通知其进行事务提交,同时
Leader 自身也会完成对事务的提交。
zookeeper-操作与应用场景-《每日五分钟搞定大数据》
zookeeper-架构设计与角色分工-《每日五分钟搞定大数据》
zookeeper-paxos与一致性-《每日五分钟搞定大数据》
最近这几篇理论性的东西太多,下一篇写点简单的代码,zookeeper分布式锁的实现。感谢阅读。
zookeeper-非常重要的zab协议-《每日五分钟搞定大数据》
标签:lead osal 概率 进入 lock 结果 inf 本地 image
原文地址:https://www.cnblogs.com/uncleData/p/9726566.html