标签:记忆 scrapy 文件 请求 .com 方法 通信 rap one
1. HTTP协议
2. Requests库的7个主要方法
3. Robot协议
4. 网页解析
BeautifulSoup的解析器- 类的基本元素- 遍历功能
5. 正则表达式
6. 爬虫框架Scrapy
框架结构- 数据流
7. 分布式爬虫
多线程爬虫
多进程爬虫
8. 异步网站数据擦剂
9.爬虫的存储
媒体文件-把数据存储到CSV-MySql
10. 爬虫的常见技巧
11.防爬虫
超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的www文件都必须遵守这个标准。HTTP协议主要有几个特点:
支持客户/服务器模式
简单快捷:客服向服务器发出请求,只需要传送请求方法和路径。请求方法常用的有GET, HEAD, POST。每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度快。
灵活:HTTP允许传输任意类型的数据对象。
无连接:无连接的含义是限制每次连接请求只处理一个请求。服务器处理完客户的请求,收到客户的应答后即断开连接,这种方式可以节省传输时间。
无状态:HTTP协议是无状态协议。无状态是指协议对于事物处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大,另一方面,在服务器不需要先前信息时它的应答就较快。
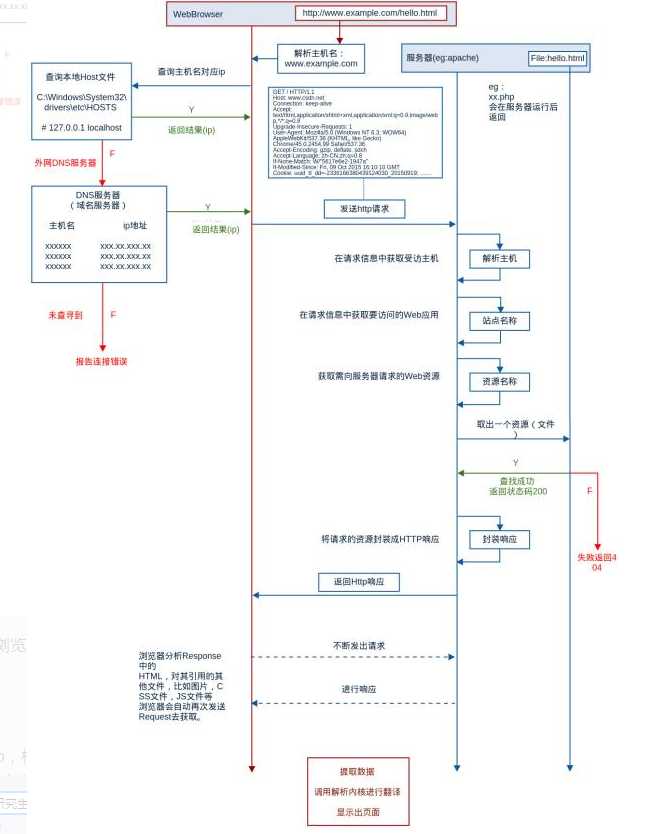
下面通过一张图我们来了解一下访问网页的过程都发生了什么:
--------------------- 本文来自 meichuanyi 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/meichuanyi/article/details/79293094?utm_source=copy
标签:记忆 scrapy 文件 请求 .com 方法 通信 rap one
原文地址:https://www.cnblogs.com/jliu520222/p/9729121.html