标签:tca 应用 查询 temp exception rtu efault 任务 生产环境
No.1 静态文件处理项目中CSS、JS、图片都属于静态文件,一般会将静态文件存到一个单独目录中,便于管理,在HTML页面调用时,需要指定静态文件的路径,Django提供了一种解析静态文件的机制,文件可以放在项目目录下,也可以放在应用目录下
在mysite/setting.py设置文件的物理路径
STATIC_URL = ‘/static/‘
STATICFILES_DIRS = [
os.path.join(BASE_DIR, ‘static‘),
]在static目录下创建css、js、img目录
Django的中间件是一个轻量级的插件系统,可以介入请求和响应的过程,修改输入与输出,中间件的设计为开发者提供了一种无侵入式的开发方式,增加了框架的健壮性,Django在中间价中内置了5个方法,区别在于不同的阶段执行,用来干预请求和响应
初始化,不需要参数,服务器响应第一个请求的时候调用一次,用于确定是否启用中间件
def __init__(self):
pass处理请求前 每个请求上,生成request对象后,配置url前调用,返回None或HttpResponse对象
def process_request(self, request):
pass处理视图前 在每个请求上,url匹配后,视图函数调用之前调用,返回None或HttpResponse对象
def process_view(self, request, view_func, *view_args, **view_kwargs):
pass处理响应后 视图函数调用之后,所有响应返回浏览器之前调用,返回一个HttpResponse对象
def process_response(self, request, response):
pass异常处理:当视图抛出异常时调用,在每个请求上调用,返回一个HttpResponse对象
def process_exception(self, request,exception):
pass栗子
# app01/middware.py
class my_mid:
def __init__(self):
print(‘--------------init‘)
def process_request(self,request):
print(‘--------------request‘)
def process_view(self,request, view_func, *view_args, **view_kwargs):
print(‘--------------view‘)
def process_response(self,request, response):
print(‘--------------response‘)
return response
class exp1:
def process_exception(self,request,exception):
print(‘--------------exp1‘)
class exp2:
def process_exception(self,request,exception):
print(‘--------------exp2‘)
# mysite/setting.py
MIDDLEWARE_CLASSES = [
‘django.middleware.security.SecurityMiddleware‘,
‘django.contrib.sessions.middleware.SessionMiddleware‘,
‘django.middleware.common.CommonMiddleware‘,
‘django.middleware.csrf.CsrfViewMiddleware‘,
‘django.contrib.auth.middleware.AuthenticationMiddleware‘,
‘django.contrib.messages.middleware.MessageMiddleware‘,
‘django.middleware.clickjacking.XFrameOptionsMiddleware‘,
‘app01.middleware.my_mid‘,
]Django提供了数据分页的类,这些类被定义在django/core/paginator.py中, 类Paginator用于对列进行一页n条数据的分页运算,类Page用于表示第m页的数据
Paginator类实例对象
Page类实例对象
栗子
from django.core.paginator import Paginator
from app01.models import AreaInfo
# 参数pIndex表示:当前要显示的页码
def page_test(request,pIndex=1):
#查询所有的地区信息
list_address = AreaInfo.objects.filter(aParent__isnull=True)
#将地区信息按一页10条进行分页
p = Paginator(list_address, 10)
# 通过url匹配的参数都是字符串类型,转换成int类型
pIndex = int(pIndex)
# 获取第pIndex页的数据
page_list = p.page(pIndex)
#获取所有的页码信息
plist = p.page_range
#将当前页码、当前页的数据、页码信息传递到模板中
return render(request, ‘app01/page_test.html‘, {‘list‘: list2, ‘plist‘: plist, ‘pIndex‘: pIndex})
# app01/urls.py
url(r‘^page(?P<pIndex>[0-9]*)/$‘, views.page_test),
# app01/views.py
<html>
<head>
<title>分页</title>
</head>
<body>
显示当前页的地区信息:<br>
<ul>
{%for area in list%}
<li>{{area.id}}--{{area.atitle}}</li>
{%endfor%}
</ul>
<hr>
显示页码信息:当前页码没有链接,其它页码有链接<br>
{%for pindex in plist%}
{%if pIndex == pindex%}
{{pindex}}??
{%else%}
<a href="/page{{pindex}}/">{{pindex}}</a>??
{%endif%}
{%endfor%}
</body>
</html>借助富文本编辑器,网站的编辑人员能够像使用offfice一样编写出漂亮的、所见即所得的页面
安装
pip3 install django-tinymce栗子
在mysite/setting.py添加应用
INSTALLED_APPS = (
...
‘tinymce‘,
)
在mysite/setting.py配置编辑器
TINYMCE_DEFAULT_CONFIG = {
‘theme‘: ‘advanced‘,
‘width‘: 600,
‘height‘: 400,
}
在app01/urls.py配置url
urlpatterns = [
...
url(r‘^tinymce/‘, include(‘tinymce.urls‘)),
]在app01/models.py中定义模型类
from django.db import models
from tinymce.models import HTMLField
class GoodsInfo(models.Model):
gcontent=HTMLField()执行迁移
在admin中进行注册
在app01/views.py中定义视图
def editor(request):
return render(request, ‘app01/editor.html‘)
在app01/urls.py定义url
url(r‘^editor/‘,views.editor),在项目目录下创建cs、js、img目录
打开py_django目录,找到tinymce是的目录
/home/python/.virtualenvs/py_django/lib/python3.5/site-packages/tinymce/static/tiny_mce拷贝tiny_mce_src.js文件、langs文件夹以及themes文件夹拷贝到项目目录下的static/js/目录下
配置静态文件查找路径
创建editor.html模板
<html>
<head>
<title>自定义使用tinymce</title>
<script type="text/javascript" src=‘/static/js/tiny_mce.js‘></script>
<script type="text/javascript">
tinyMCE.init({
‘mode‘:‘textareas‘,
‘theme‘:‘advanced‘,
‘width‘:400,
‘height‘:100
});
</script>
</head>
<body>
<form method="post" action="#">
<textarea name=‘gcontent‘>哈哈,这是啥呀</textarea>
</form>
</body>
</html>全文检索不同于特定字段的模糊查询,使用全文检索的效率更高,并且能够对于中文进行分词处理
安装包
pip install django-haystack
pip install whoosh
pip install jieba修改app01/settings.py文件,安装应用haystack
INSTALLED_APPS = (
...
‘haystack‘,
)在app01/settings.py文件中配置搜索引擎
HAYSTACK_CONNECTIONS = {
‘default‘: {
#使用whoosh引擎
‘ENGINE‘: ‘haystack.backends.whoosh_cn_backend.WhooshEngine‘,
#索引文件路径
‘PATH‘: os.path.join(BASE_DIR, ‘whoosh_index‘),
}
}
#当添加、修改、删除数据时,自动生成索引
HAYSTACK_SIGNAL_PROCESSOR = ‘haystack.signals.RealtimeSignalProcessor‘在app01/urls.py中添加搜索的配置
url(r‘^search/‘, include(‘haystack.urls‘)),在app01下创建search_indexs.py文件
from haystack import indexes
from app01.models import GoodsInfo
#指定对于某个类的某些数据建立索引
class GoodsInfoIndex(indexes.SearchIndex, indexes.Indexable):
text = indexes.CharField(document=True, use_template=True)
def get_model(self):
return GoodsInfo
def index_queryset(self, using=None):
return self.get_model().objects.all()在templates目录下创建search/indexes/app01/目录
在上面的目录中创建"goodsinfo_text.txt"文件
{{object.gcontent}}找到虚拟环境py_django下的haystack目录
/home/python/.virtualenvs/py_django/lib/python3.5/site-packages/haystack/backends/在上面的目录中创建ChineseAnalyzer.py文件
import jieba
from whoosh.analysis import Tokenizer, Token
class ChineseTokenizer(Tokenizer):
def __call__(self, value, positions=False, chars=False,
keeporiginal=False, removestops=True,
start_pos=0, start_char=0, mode=‘‘, **kwargs):
t = Token(positions, chars, removestops=removestops, mode=mode,
**kwargs)
seglist = jieba.cut(value, cut_all=True)
for w in seglist:
t.original = t.text = w
t.boost = 1.0
if positions:
t.pos = start_pos + value.find(w)
if chars:
t.startchar = start_char + value.find(w)
t.endchar = start_char + value.find(w) + len(w)
yield t
def ChineseAnalyzer():
return ChineseTokenizer()复制whoosh_backend.py文件,改为如下名称
whoosh_cn_backend.py打开复制出来的新文件,引入中文分析类,内部采用jieba分词
from .ChineseAnalyzer import ChineseAnalyzer更改词语分析类
查找
analyzer=StemmingAnalyzer()
改为
analyzer=ChineseAnalyzer()初始化索引数据
python manage.py rebuild_index按提示输入y后回车,生成索引
按照配置,在admin管理中添加数据后,会自动为数据创建索引,可以直接进行搜索,可以先创建一些测试数据
在app01/views.py中定义视图query
def query(request):
return render(request,‘app01/query.html‘)在app01/urls.py中配置
url(r‘^query/‘, views.query),在templates/app01/目录中创建模板query.html
<html>
<head>
<title>全文检索</title>
</head>
<body>
<form method=‘get‘ action="/search/" target="_blank">
<input type="text" name="q">
<br>
<input type="submit" value="查询">
</form>
</body>
</html>自定义搜索结果模板:在templates/search/目录下创建search.html
搜索结果进行分页,视图向模板中传递的上下文如下:
视图接收的参数如下:
<html>
<head>
<title>全文检索--结果页</title>
</head>
<body>
<h1>搜索?<b>{{query}}</b>?结果如下:</h1>
<ul>
{%for item in page%}
<li>{{item.object.id}}--{{item.object.gcontent|safe}}</li>
{%empty%}
<li>啥也没找到</li>
{%endfor%}
</ul>
<hr>
{%for pindex in page.paginator.page_range%}
{%if pindex == page.number%}
{{pindex}}??
{%else%}
<a href="?q={{query}}&page={{pindex}}">{{pindex}}</a>??
{%endif%}
{%endfor%}
</body>
</html>Django中内置了邮件发送功能,被定义在django.core.mail模块中。发送邮件需要使用SMTP服务器,常用的免费服务器有:163、126、QQ,下面以163邮件为例
注册163邮箱itcast88,登录后设置->POP3/SMTP/IMAP->客户端授权密码->开启->填写授权码->确定
打开mysite/settings.py文件,点击下图配置。
EMAIL_BACKEND = ‘django.core.mail.backends.smtp.EmailBackend‘
EMAIL_HOST = ‘smtp.163.com‘
EMAIL_PORT = 25
#发送邮件的邮箱
EMAIL_HOST_USER = ‘dingzefeng2017@163.com‘
#在邮箱中设置的客户端授权密码
EMAIL_HOST_PASSWORD = ‘******‘
#收件人看到的发件人
EMAIL_FROM = ‘python<dingzefeng2017@163.com>‘在app01/views.py文件中新建视图send
from django.conf import settings
from django.core.mail import send_mail
from django.http import HttpResponse
...
def send(request):
msg=‘<a href="http://www.dingzefeng2017.cn/subject/pythonzly/index.shtml" target="_blank">点击激活</a>‘
send_mail(‘注册激活‘,‘‘,settings.EMAIL_FROM,
[‘dingzefeng2017@163.com‘],
html_message=msg)
return HttpResponse(‘ok‘)在app01/urls.py文件中配置
url(r‘^send/$‘,views.send),用户发起request,并等待response返回,可能需要执行一段耗时的程序,那么用户就会等待很长时间,造成不好的用户体验,比如发送邮件、手机验证码等,使用celery后,情况就不一样了。解决:将耗时的程序放到celery中执行
celery名词:
安装包:
celery==3.1.25
django-celery==3.1.17栗子
在app01/views.py文件中创建视图sayhello
import time
...
def sayhello(request):
print(‘hello ...‘)
time.sleep(2)
print(‘world ...‘)
return HttpResponse("hello world")在app01/urls.py中配置
url(r‘^sayhello$‘,views.sayhello),在app01/settings.py中安装
INSTALLED_APPS = (
...
‘djcelery‘,
}在app01/settings.py文件中配置代理和任务模块
import djcelery
djcelery.setup_loader()
BROKER_URL = ‘redis://127.0.0.1:6379/2‘在app01/目录下创建tasks.py文件
import time
from celery import task
@task
def sayhello():
print(‘hello ...‘)
time.sleep(2)
print(‘world ...‘)打开app01/views.py文件,修改sayhello视图如下:
from app01 import tasks
...
def sayhello(request):
# print(‘hello ...‘)
# time.sleep(2)
# print(‘world ...‘)
tasks.sayhello.delay()
return HttpResponse("hello world")执行迁移生成celery需要的数据表
启动Redis,如果已经启动则不需要启动
sudo service redis start启动worker
python manage.py celery worker --loglevel=info打开app01/task.py文件,修改为发送邮件的代码,就可以实现无阻塞发送邮件
from django.conf import settings
from django.core.mail import send_mail
from celery import task
@task
def sayhello():
msg=‘<a href="http://www.dingzefeng2017.cn/subject/pythonzly/index.shtml" target="_blank">点击激活</a>‘
send_mail(‘注册激活‘,‘‘,settings.EMAIL_FROM,
[‘dingzefeng2017@163.com‘],
html_message=msg)当项目开发完成后,需要将项目代码放到服务器上,这个服务器拥有固定的IP,再通过域名绑定,就可以供其它人浏览,对于python web开发,可以使用wsgi、apache服务器,此处以wsgi为例进行布署。
服务器首先是物理上的一台性能高、线路全、运行稳定的机器,分为私有服务器、公有服务器。
常用的公有服务器,如阿里云、青云等,可按流量收费或按时间收费。服务器还需要安装服务器软件,此处需要uWSGI、Nginx。
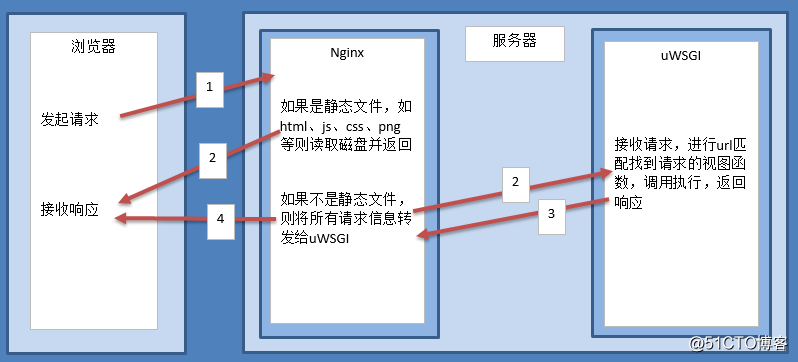
服务器架构如下图:
布署前需要关闭调试、允许任何机器访问,打开app01/settings.py文件
DEBUG = False
ALLOW_HOSTS=[‘*‘,]在生产环境中使用WSGI作为python web的服务器。WSGI:全拼为Python Web Server Gateway Interface,Python Web服务器网关接口,是Python应用程序或框架和Web服务器之间的一种接口,被广泛接受。WSGI没有官方的实现, 因为WSGI更像一个协议,只要遵照这些协议,WSGI应用(Application)都可以在任何服务器(Server)上运行。
项目默认会生成一个wsgi.py文件,确定了settings模块、application对象。
uWSGI实现了WSGI的所有接口,是一个快速、自我修复、开发人员和系统管理员友好的服务器,uWSGI代码完全用C编写,效率高、性能稳定
安装uWSGI
pip install uwsgi配置uWSGI,在项目目录下创建uwsgi.ini文件,配置如下:
[uwsgi]
#使用nginx连接时使用
#socket=127.0.0.1:8080
#直接做web服务器使用
http=127.0.0.1:8080
#项目目录
chdir=/home/python/Desktop/pytest/mysite
#项目中wsgi.py文件的目录,相对于项目目录
wsgi-file=app01/wsgi.py
processes=4
threads=2
master=True
pidfile=uwsgi.pid
daemonize=uwsgi.log启动
uwsgi --ini uwsgi.ini查看
ps ajx|grep uwsgi停止
uwsgi --stop uwsgi.pid测试没问题,将配置中启用socket,禁用http
[uwsgi]
#使用nginx连接时使用
socket=127.0.0.1:8080
#直接做web服务器使用
#http=127.0.0.1:8080
#项目目录
chdir=/home/python/Desktop/pytest/mysite
#项目中wsgi.py文件的目录,相对于项目目录
wsgi-file=app01/wsgi.py
processes=4
threads=2
master=True
pidfile=uwsgi.pid
daemonize=uwsgi.log停止uwsgi服务,然后再启动uwsgi
标签:tca 应用 查询 temp exception rtu efault 任务 生产环境
原文地址:http://blog.51cto.com/13559120/2294156