标签:时间 jpg blog strip() rap proc gprof get 主程
一、程序分析
1、读取文件到缓冲区
def process_file(dst): # 读文件到缓冲区
try: # 打开文件
f = open(dst,‘r‘)
except IOError,s:
print s
return None
try: # 读文件到缓冲区
bvffer = f.read()
except:
print "Read File Error!"
return None
f.close()
return bvffer
2、缓冲区字符串分割成带有词频的字典
def process_buffer(bvffer):
if bvffer:
word_freq = {}
# 下面添加处理缓冲区 bvffer代码,统计每个单词的频率,存放在字典word_freq
bvffer.lower()
char={"~@#$%^&*()_-+=<>?/,.:;{}[]|\‘“”"}
for ch in char :
bvffer=bvffer.replace(ch,‘ ‘)
words=bvffer.strip().split()
for word in words:
word_freq[word]=word_freq.get(word,0) + 1
return word_freq
3、将字典按词频排序并输出排名前十的键值对
def output_result(word_freq):
if word_freq:
sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True)
for item in sorted_word_freq[:10]: # 输出 Top 10 的单词
print item
4、主程序输出前十结果和分析结果
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser()
parser.add_argument(‘dst‘)
args = parser.parse_args()
dst = args.dst
bvffer = process_file(dst)
word_freq = process_buffer(bvffer)
output_result(word_freq)
二、代码风格说明
1.使用 4 个空格的缩进
2.使用空行分隔函数和类,以及函数内的大块代码
3.运算符周围和逗号后面使用空格,但是括号里侧不加空格
4.折行以确保其不会超过 79 个字符
三、程序运行结果截图
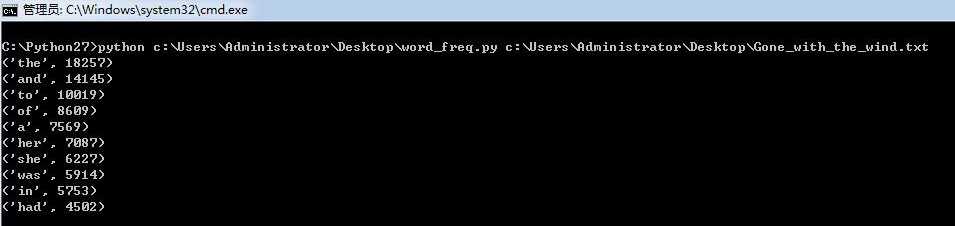

四、性能分析及改进
1、性能分析
1.1、模块耗用时间可视化操作
下载转换 dot 的 python 代码gprof2dot 官方下载,解压缩,将『gprof2dot.py』 copy 到当前分析文件的路径,或者你系统 PATH 环境变量设置过的路径。
转换图如下:
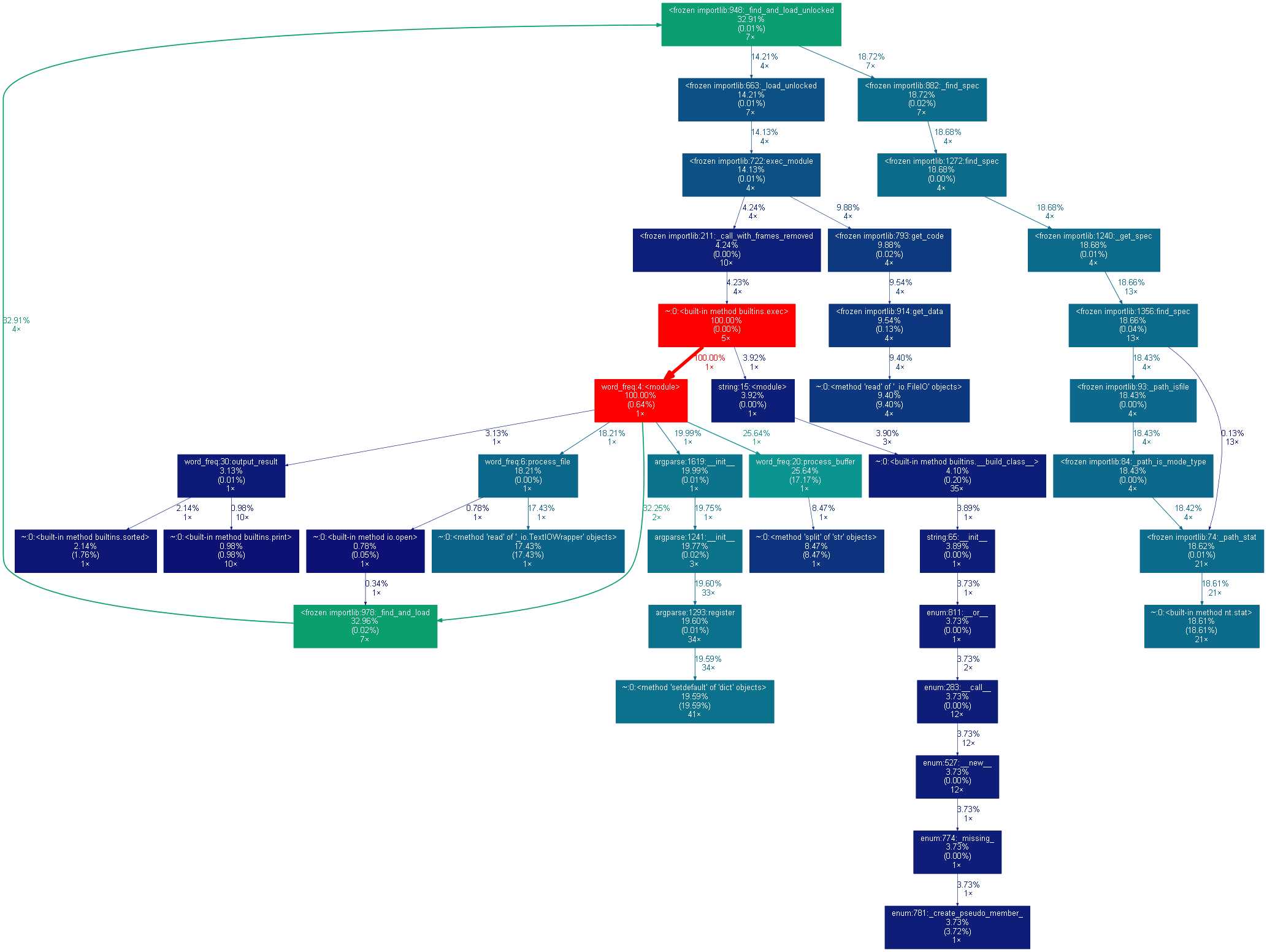
标签:时间 jpg blog strip() rap proc gprof get 主程
原文地址:https://www.cnblogs.com/zhuangzq/p/9763882.html