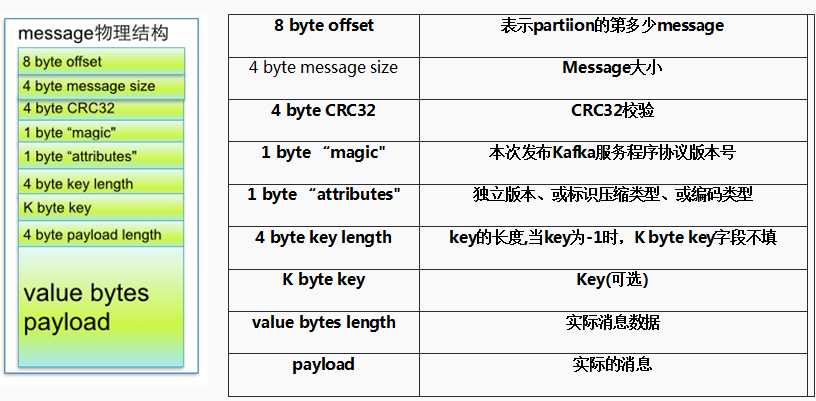
标签:end bubuko 分支 下载 mda snapshot sign and path变量
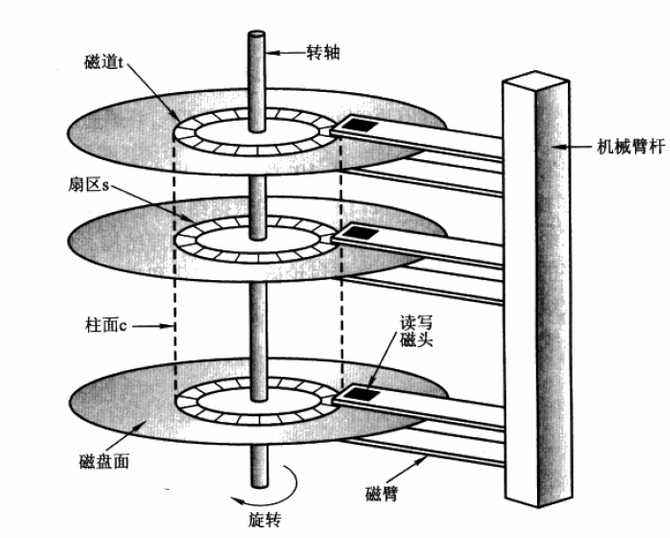
当需要从磁盘读取数据时,要确定读的数据在哪个磁道,哪个扇区:
首先必须找到柱面,即磁头需要移动对准相应磁道,这个过程叫做寻道,所耗费时间叫做寻道时间;
然后目标扇区旋转到磁头下,这个过程耗费的时间叫做旋转时间;
一次访盘请求(读/写)完成过程由三个动作组成
寻道(时间):磁头移动定位到指定磁道;
旋转延迟(时间):等待指定扇区从磁头下旋转经过;
数据传输(时间):数据在磁盘、内存与网络之间的实际传输
由于存储介质的特性,磁盘本身存取就比主存慢,再加上机械运动耗费,磁盘的存取速度往往是主存的几百分之一甚至几千分支一

根据数据的局部性原理 ,有以下两种方法
•预读或者提前读;
•合并写——多个逻辑上的写操作合并成一个大的物理写操作中;
即采用磁盘顺序读写(不需要寻道时间,只需很少的旋转时间)。实验结果:在一个6 7200rpm SATA RAID-5 的磁盘阵列上线性写的速度大概是300M/秒,但是随机写的速度只有50K/秒,两者相差将近10000倍。
一般的将数据从文件传到套接字的路径:
1.操作系统将数据从磁盘读到内核空间的页缓存中;
2.应用将数据从内核空间读到用户空间的缓存中;
3.应用将数据写回内存空间的套接字缓存中
4.操作系统将数据从套接字缓存写到网卡缓存中,以便将数据经网络发出;
这样做明显是低效的,这里有四次拷贝,两次系统调用。如果使用sendfile(Java 为: FileChannel.transferTo api),两次拷贝可以被避免:允许操作系统将数据直接从页缓存发送到网络上。优化后,只有最后一步将数据拷贝到网卡缓存中是需要的。
Kafka topic信息
从最久的日志段开始删除(按日志段为单位进行删除),然后逐步向前推进,直到某个日志段不满足条件为止,删除条件:
满足给定条件predicate(配置项log.retention.{ms,minutes,hours}和log.retention.bytes指定);
不能是当前激活日志段;
大小不能小于日志段的最小大小(配置项log.segment.bytes配置)
要删除的是否是所有日志段,如果是的话直接调用roll方法进行切分,因为Kafka至少要保留一个日志段;


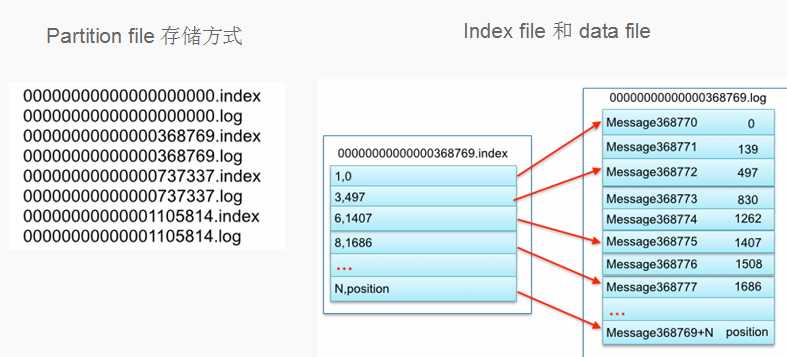
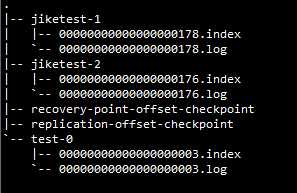
以读取offset=368776的message为例,需要通过下面2个步骤查找:
第一步查找segment file;
以上图为例,其中00000000000000000000.index表示最开始的文件,起始偏移量(offset)为0.第二个文件00000000000000368769.index的消息量起始偏移量为368770 = 368769 + 1。只要根据offset二分查找文件列表,就可以快速定位到具体文件。当offset=368776时定位到00000000000000368769.index|log
第二步通过segment file查找message;
算出368776-368770=6,取00000000000000368769.index文件第三项(6,1407),得出从00000000000000368769.log文件头偏移1407字节读取一条消息即可
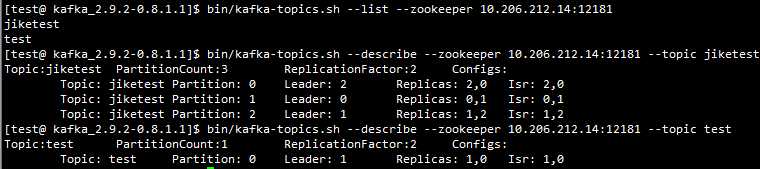
集群信息实时查看(topic工具):
列出集群当前所有可用的topic:
bin/kafka-topics.sh --list –zookeeper zookeeper_address

查看集群特定topic 信息:
bin/kafka-topics.sh --describe --zookeeper zookeeper_address
--topic topic_name

集群信息实时修改(topic工具):
创建topic:
bin/kafka-topics.sh --create --zookeeper zookeeper_address --replication-factor 1 --partitions 1 --topic topic_name
增加(不能减少) partition(最后的4是增加后的值):
bin/kafka-topics.sh --zookeeper zookeeper_address --alter –topic topic_name --partitions 4
Topic-level configuration 配置都能修改
每个partitiion的所有replicas叫做“assigned replicas”,“assigned replicas”中的第一个replicas叫“preferred replica”,刚创建的topic一般“preferred replica”是leader。下图中Partition 0的broker 2就是preferred replica”,默认会成为该分区的leader。

集群leader平衡:
bin/kafka-preferred-replica-election.sh –zookeeper zookeeper_address
auto.leader.rebalance.enable=true
迁移topic数据到其他broker,请遵循下面四步:
写json文件,文件格式如下:
cat topics-to-move.json
{"topics": [{"topic": "foo1"},
{"topic": "foo2"}],
"version":1
}
使用–generate生成迁移计划(下面的操作是将topic: foo1和foo2移动到broker 5,6):
bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --topics-to-move-json-file topics-to-move.json --broker-list "5,6" –generate
这一步只是生成计划,并没有执行数据迁移;
使用–execute执行计划:
bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file expand-cluster-reassignment.json –execute
执行前最好保存当前的分配情况,以防出错回滚
进行分区迁移时最好先保留一个分区在原来的磁盘,这样不会影响正常的消费和生产,如果目的是将分区5(brober1,5)迁移到borker2,3。可以先将5迁移到2,1,最后再迁移到2,3。而不是一次将1,5迁移到2,3。因为一次迁移所有的副本,无法正常消费和生产,部分迁移则可以正常消费和生产
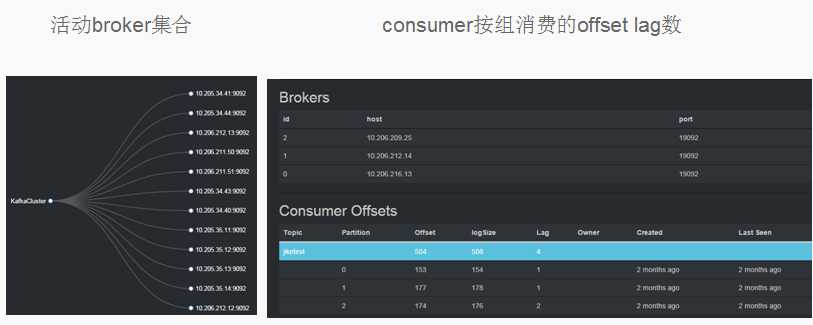
在生产环境需要集群高可用,所以需要对Kafka集群进行监控。Kafka Offset Monitor可以监控Kafka集群以下几项:
Kafka集群当前存活的broker集合;
Kafka集群当前活动topic集合;
消费者组列表
Kafka集群当前consumer按组消费的offset lag数(即当前topic当前分区目前有多少消息积压而没有及时消费)
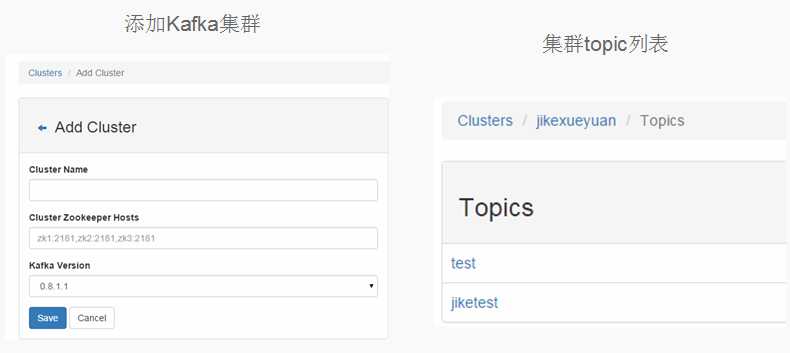
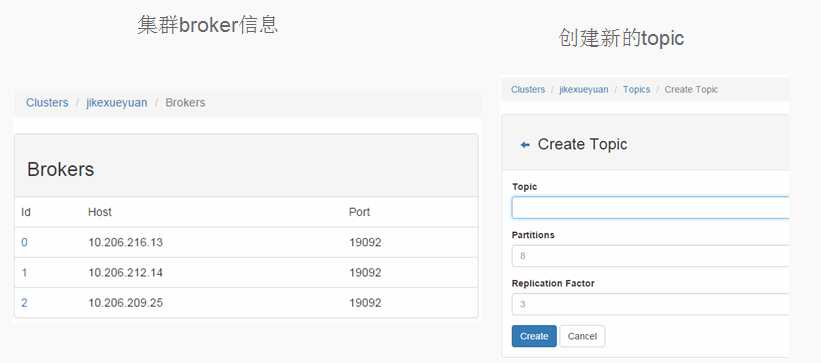
Kafka Manager由雅虎开源,提供以下功能:
管理几个不同的集群;
容易地检查集群的状态(topics, brokers, 副本的分布, 分区的分布) ;
选择副本
基于集群的当前状态产生分区分配
重新分配分区
Kafka Manager的安装,方法二:
下载打包好的Kafka manager(也可以在课程源代码处下载):
https://github.com/scootli/kafka-manager-1.0-SNAPSHOT/tree/master/kafka-manager-1.0-SNAPSHOT
下载后解压
修改conf/application.conf,把Kafka-manager.zkhosts改为自己的zookeeper服务器地址
bin/kafka-manager -Dconfig.file=conf/application.conf -Dhttp.port=8007 &
标签:end bubuko 分支 下载 mda snapshot sign and path变量
原文地址:https://www.cnblogs.com/pony1223/p/9769487.html