标签:个数 keep 字符串 服务器 views 一半 角度 etc 调度
1 为什么需要kafka2 kafka概念
Broker
Kafka集群包含一个或多个服务器,这种服务器被称为broker [5]
Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
Partition
Partition是物理上的概念,每个Topic包含一个或多个Partition.
Producer
负责发布消息到Kafka broker
Consumer
消息消费者,向Kafka broker读取消息的客户端。
Consumer Group
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。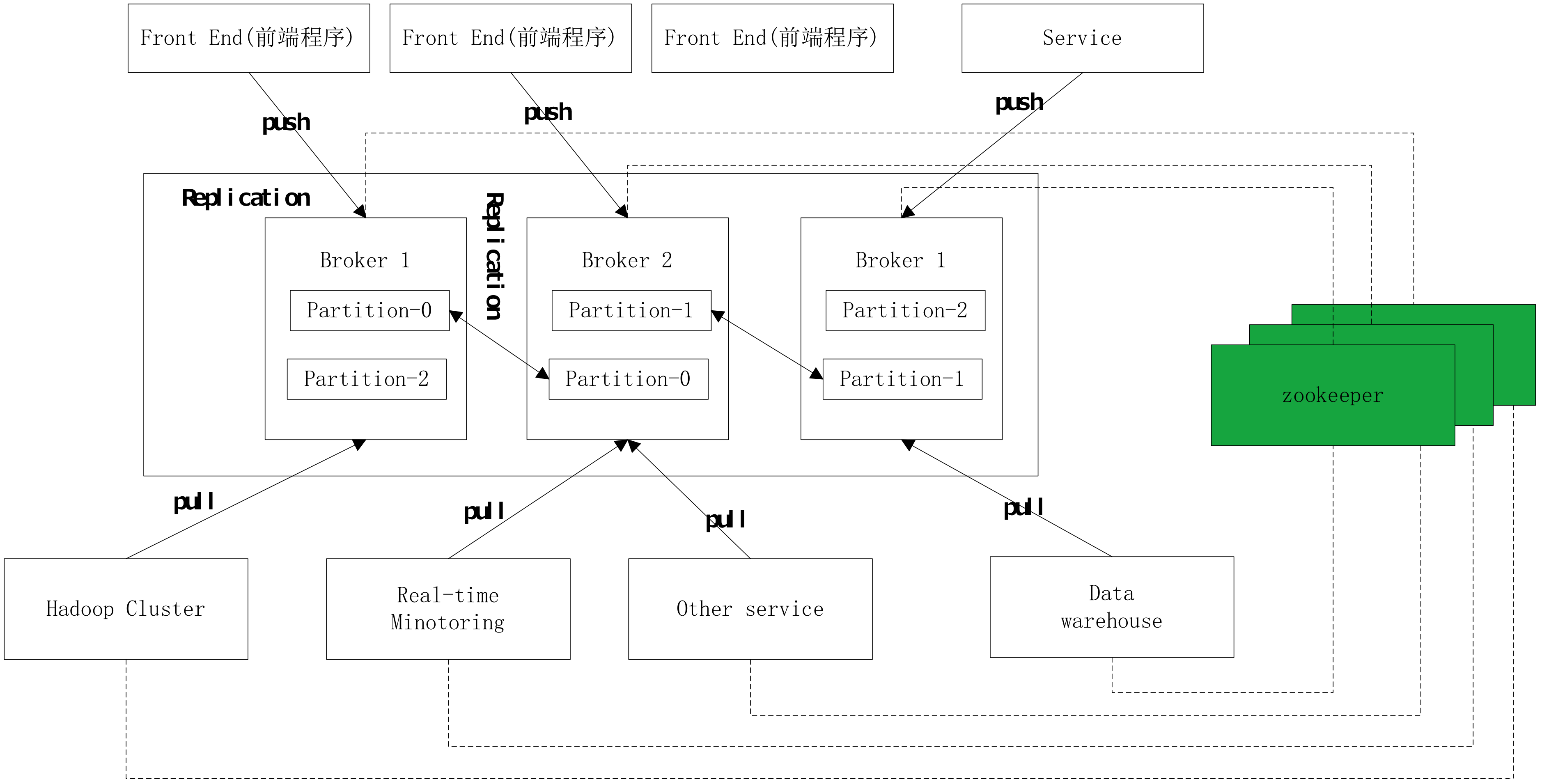
3 kafka为什么需要zk
1)Kafka把它的meta数据都存储在ZK上,所以说ZK是必要存在的,没有ZK没法运行Kafka;在老版本(0.8.1以前)里面消费段(consumer)也是依赖ZK的,在新版本中移除了客户端对ZK的依赖,但是broker依然依赖于ZK。
2)kafka是消息队列,zookeeper是服务的控制中心;消费者要访问服务,需要知道现在哪些生产者(对于消费者而言,kafka就是生产者)是可用的,就需要zk的调度。
4zk 和kafka常用命令
Kafka:
1 查看所有topic的状态
./kafka-topics.sh --describe --zookeeper 10.47.42.233:2181,10.47.42.179:2181,10.47.42.112:2181
2 查看所有的topic
./kafka-topics.sh --list --zookeeper 10.47.42.233:2181,10.47.42.179:2181,10.47.42.112:2181
3 查看某个topic状态
./kafka-topics.sh --describe --zookeeper 10.47.42.233:2181,10.47.42.179:2181,10.47.42.112:2181 --topic FF-ESB-JK0001
4 jvm配置路径
/wls/apache/servers/ka_ff-esbc-007SF16863/bin/kafka-server-start.sh
Zookeeper
(启动ZK服务: bin/zkServer.sh start
查看ZK服务状态: bin/zkServer.sh status
停止ZK服务: bin/zkServer.sh stop
重启ZK服务: bin/zkServer.sh restart
创建 testnode节点,关联字符串"zz" create /zk/testnode "zz"
查看节点内容 get /zk/testnode
设置节点内容 set /zk/testnode abc
删除节点 delete /zk/testnode )
公司的都用如:deployadmin -s zk_ff-esbc-007 -a list 这种方式操作
连接zk服务:
zkCli.sh -server 10.47.42.112:2181
java目录:
/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.79.x86_64/jre
jvm配置路径:
zkServer.sh
默认jvm没有配置Xmx、Xms等信息,可以在conf目录下创建java.env文件
export JVMFLAGS="-Xms512m -Xmx512m $JVMFLAGS"
5 集群节点状态查看
[root@Basic kafka_2.11-1.1.0]# bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
Topic:test PartitionCount:3 ReplicationFactor:3 Configs:
Topic: test Partition: 0 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1
Topic: test Partition: 1 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
Topic: test Partition: 2 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
PartitionCount: 3 表示有3个分区
ReplicationFactor: 3 表示复制因子为3
Topic: test Partition: 0 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1
分区下标是从0开始的,也就是第一个分区P0
leader: 2 表示P0的Leader是在broker.id=2的集群节点上
Replicas: 2,0,1 列出了所有的副本节点,不管节点是否在服务中
Isr: 2,0,1 是正在服务中的节点,如果其中一个节点挂掉了,那么这里就会减少哪个挂掉节点的broker.id
上面描述的是,Topic test有三个分区,其中分区P0的Leader在broker.id=2的节点上,P0备份在broker.id=0,1,2 上面都有,然后分区P1的Leader在broker.id=0的节点上,P2的Leader在broker.id=1的节点上,另外两个节点上都有备份。
注:
ISR,也即In-sync Replica。每个Partition的Leader都会维护这样一个列表,该列表中,包含了所有与之同步的Replica(包含Leader自己)。每次数据写入时,只有ISR中的所有Replica都复制完,Leader才会将其置为Commit,它才能被Consumer所消费。
这种方案,与同步复制非常接近。但不同的是,这个ISR是由Leader动态维护的。如果Follower不能紧“跟上”Leader,它将被Leader从ISR中移除,待它又重新“跟上”Leader后,会被Leader再次加加ISR中。每次改变ISR后,Leader都会将最新的ISR持久化到Zookeeper中。
使用ISR方案的原因
由于Leader可移除不能及时与之同步的Follower,故与同步复制相比可避免最慢的Follower拖慢整体速度,也即ISR提高了系统可用性。
ISR中的所有Follower都包含了所有Commit过的消息,而只有Commit过的消息才会被Consumer消费,故从Consumer的角度而言,ISR中的所有Replica都始终处于同步状态,从而与异步复制方案相比提高了数据一致性。
ISR可动态调整,极限情况下,可以只包含Leader,极大提高了可容忍的宕机的Follower的数量。与Majority Quorum方案相比,容忍相同个数的节点失败,所要求的总节点数少了近一半。
6 kafka配置文件
broker.id=0 #当前机器在集群中的唯一标识,和zookeeper的myid性质一样
port=19092 #当前kafka对外提供服务的端口默认是9092
host.name=192.168.7.100 #这个参数默认是关闭的,在0.8.1有个bug,DNS解析问题,失败率的问题。
num.network.threads=3 #这个是borker进行网络处理的线程数
num.io.threads=8 #这个是borker进行I/O处理的线程数
log.dirs=/opt/kafka/kafkalogs/ #消息存放的目录,这个目录可以配置为“,”逗号分割的表达式,上面的num.io.threads要大于这个目录的个数这个目录,如果配置多个目录,新创建的topic他把消息持久化的地方是,当前以逗号分割的目录中,那个分区数最少就放那一个
socket.send.buffer.bytes=102400 #发送缓冲区buffer大小,数据不是一下子就发送的,先回存储到缓冲区了到达一定的大小后在发送,能提高性能
socket.receive.buffer.bytes=102400 #kafka接收缓冲区大小,当数据到达一定大小后在序列化到磁盘
socket.request.max.bytes=104857600 #这个参数是向kafka请求消息或者向kafka发送消息的请请求的最大数,这个值不能超过java的堆栈大小
num.partitions=1 #默认的分区数,一个topic默认1个分区数
log.retention.hours=168 #默认消息的最大持久化时间,168小时,7天
message.max.byte=5242880 #消息保存的最大值5M
default.replication.factor=2 #kafka保存消息的副本数,如果一个副本失效了,另一个还可以继续提供服务
replica.fetch.max.bytes=5242880 #取消息的最大直接数
log.segment.bytes=1073741824 #这个参数是:因为kafka的消息是以追加的形式落地到文件,当超过这个值的时候,kafka会新起一个文件
log.retention.check.interval.ms=300000 #每隔300000毫秒去检查上面配置的log失效时间(log.retention.hours=168 ),到目录查看是否有过期的消息如果有,删除
log.cleaner.enable=false #是否启用log压缩,一般不用启用,启用的话可以提高性能
6 问题分析
如果出现现故障如何定位是否是kafka的问题
1) kafka本身日志查看,查看连接是否正常(本身日志信息较少)
more kafka.log
2018-09-15 12:51:20,862 INFO network.Processor: Closing socket connection to /10.47.42.64.
2018-09-15 12:51:21,603 INFO network.Processor: Closing socket connection to /10.47.42.253.
2018-09-15 12:51:21,859 INFO network.Processor: Closing socket connection to /10.47.42.34.
2018-09-15 12:51:25,109 INFO network.Processor: Closing socket connection to /10.47.42.64.
2018-09-15 12:51:28,853 INFO network.Processor: Closing socket connection to /10.47.42.83.
2018-09-15 12:51:33,131 INFO network.Processor: Closing socket connection to /10.47.156.77.
2) 查看前后日志,查看api和kafka的日志,是否查到调用kafka异常何超时等情况
3 )查看kafka的topic的状态是否正常
./kafka-topics.sh --describe --zookeeper 10.47.42.233:2181,10.47.42.179:2181,10.47.42.112:2181
4)查看服务cpu、内存、io等状态
标签:个数 keep 字符串 服务器 views 一半 角度 etc 调度
原文地址:http://blog.51cto.com/10676568/2300302