标签:cat nal 出现 因子 rect length 比较 失败 命中
注:实际使用时一般正文是不会进行存储的
创建索引:
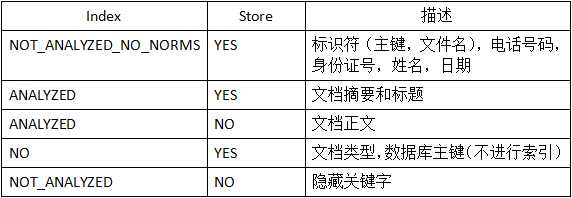
1 /** 2 * 创建索引 3 */ 4 @Test 5 public void testIndex(){ 6 //存储3篇文章的信息。包括:id、标题、作者、内容 7 int[] ids = {1,2,3}; 8 String[] titles = {"Hello","I love you","morning"}; 9 String[] authors = {"Mike","HanMeimei","Tom"}; 10 String[] contents= {"Hello,My Name Is Mike","Tome,I Love You","Good Moring,I‘m so sorry,"}; 11 12 IndexWriter writer = null; 13 14 try { 15 //1、创建Directory 16 Directory directory = FSDirectory.open(new File("E:\\lucene\\index2")); 17 18 //2、创建Writer 19 IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_35, 20 new StandardAnalyzer(Version.LUCENE_35)); 21 22 writer = new IndexWriter(directory, config); 23 24 //3、创建Document 25 Document doc = null; 26 27 //4、设置Field 28 //文档 :文件,相当于数据表中的一条记录 29 //域(Field) :数据中一列(字段)就称为域,在这里域就是文档的一个属性 30 for(int i = 0;i<ids.length;i++){ 31 doc = new Document(); 32 33 //域属性 34 //Store(配置域的存储方式) 35 //YES :在索引文件中存储域的内容,存储的内容可以方便文档恢复 36 //NO :不在索引文件中存储域内容,恢复时无法完整进行恢复(无法通过doc.get()进行获取) 37 //实际使用时一般正文是不会进行存储的 38 39 //Index(配置域的索引选项) 40 //ANALYZED :表示进行分词和索引,一般多用于标题和正文 41 //NOT_ANALYZED :表示不进行分词。但进行索引。一般用于Id、身份证号码、电话等精确查找的内容 42 //ANALYZED_NO_NORMS :表示进行分词并索引,但不存储Norms(包含了索引的权值信息)信息 43 //正常情况下,搜索列表是按照权值进行排序的。做的比较好的是Google 44 //NOT_ANALYZED_NO_NORMS :即不分词也不存储Norms信息 45 //No :不进行索引和分词 46 47 //为文档添加域(属性) 48 String id = Integer.toString(ids[i]); 49 doc.add(new Field("id",id,Field.Store.YES,Field.Index.NOT_ANALYZED_NO_NORMS)); 50 doc.add(new Field("title",titles[i],Field.Store.YES,Field.Index.NOT_ANALYZED)); 51 doc.add(new Field("author",authors[i],Field.Store.YES,Field.Index.NOT_ANALYZED)); 52 doc.add(new Field("content", contents[i],Field.Store.NO,Field.Index.ANALYZED)); 53 54 writer.addDocument(doc); 55 } 56 } catch (IOException e) { 57 e.printStackTrace(); 58 } 59 finally{ 60 if(writer != null) 61 try { 62 writer.close(); 63 } catch (CorruptIndexException e) { 64 // TODO Auto-generated catch block 65 e.printStackTrace(); 66 } catch (IOException e) { 67 // TODO Auto-generated catch block 68 e.printStackTrace(); 69 } 70 } 71 }
搜索;
1 /** 2 * 搜索 3 */ 4 @Test 5 public void testSearch(){ 6 IndexReader reader =null; 7 try { 8 //1、创建Directory 9 Directory directory = FSDirectory.open(new File("E:\\lucene\\index2")); 10 11 //2、创建IndexReader 12 reader = IndexReader.open(directory); 13 14 //应用较多 15 System.out.println("索引文件数:" + reader.numDocs()); 16 System.out.println("最大文件数:" + reader.maxDoc()); 17 18 19 20 } catch (IOException e) { 21 // TODO Auto-generated catch block 22 e.printStackTrace(); 23 } 24 finally{ 25 if (reader != null) { 26 try { 27 reader.close(); 28 } catch (IOException e) { 29 // TODO Auto-generated catch block 30 e.printStackTrace(); 31 } 32 } 33 } 34 }
1) segment
表示一个完整的索引文件。搜索时通过该文件进行搜索。他是索引的重要文件。
2) fnm
存储了索引中所有Field的信息。
3) fdx和fdt
.fdx和.fdt是综合使用的两类文件,其中.fdt类型文件用于存储具有Store.YES属性的Field数据。而.fdx类型文件则是一个索引,用于存储Document在下面代码就是创建索引的代码。
4) tii和tis
.tis文件用于存储分词后的分词(Term,相当于字典的页),而.tii就是它的所有文件(相当于字典的目录),它标明了每个.tis文件中分词的位置.
5) frq
存储了分词在文中出现的频率。
6) prx
存储了分词在每次出现的位置。
7) nrm
存储文档的标准引子。一般用该因子乘以命中次数。
8) del
存储删除之后的索引信息。
注:文件不能随意删除,否则可能造成搜索失败(出现错误)
标签:cat nal 出现 因子 rect length 比较 失败 命中
原文地址:https://www.cnblogs.com/zhzcode/p/9800809.html