标签:mod tar red 框架 缓存 address end int 经典的
在基于流水线(pipeline)的微处理器中,分支预测单元(Branch Predictor Unit)是一个重要的功能部件,它负责收集和分析分支/跳转指令的参数和执行结果,当处理新的分支/跳转指令时,BPU将根据已有的统计结果和当前分支跳转指令的参数,预测其执行结果,为流水线取指提供决策依据,进而提高流水线效率。
下面讨论提出分支预测机制的主要原因和实际意义:
在流水线处理分支跳转指令时,目标地址往往需要推迟到指令的执行阶段才能运算得出,在此之前处理器无法及时得知下一条指令的取指地址,因此无法继续取指。一种解决方法是在识别分支指令后,令取指流水级及相关的流水级暂停(stall),等待分支目标地址计算完成后再继续取指。这将浪费若干流水线时钟周期,从而降低性能。采用这种方法的流水线暂停效果示意图如下:
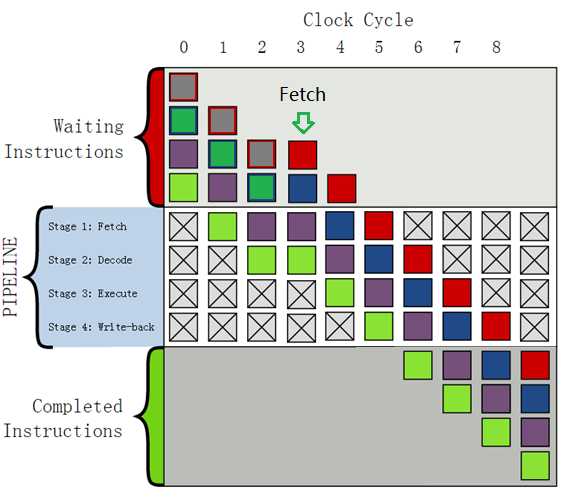
(附图:经典的四级流水线中分支指令引发的流水线暂停示意图,坐上紫色方块代表分支指令。由于采用简单的理想流水线,分支指令目标地址在执行阶段即可得出,这将浪费一个流水线时钟周期)
为改进以上方法, 我们考虑引进一种静态分支预测机制,即预测分支跳转指令一定不跳转(not taken),则上述情况将成为:默认分支跳转指令之后的指令也流入pipeline,在若干流水级后,分支指令的地址将被计算得出,此时才判断之前流入流水线的指令是否为实际目标地址所指向的指令,若真,流水线可以继续运行而不必暂停;但若假,则之前流入的指令都无效,相关流水级将被冲刷(flush),处理器只能重新从正确的地址开始取值,这将同样降低流水线的效率。
可以看到,采用静态预测后,在处理分支/跳转指令时,流水线在一定概率下将不会因分支而暂停,这就降低了出现流水线气泡周期的可能性。然而,在对性能要求较高的场合,此方法仍旧不能令人满意。
为进一步提高效率,我们考虑动态分支预测机制。动态预测基于对分支历史的记录统计,预测出分支跳转的“方向”和“目标地址”。若处理器按照预测结果取指,则一旦预测结果与实际跳转结果相同,之前流入流水线的指令将完全有效,流水线将维持运行。处理器按照预测出的“方向”和“目标地址”进行取值的行为称为预测取值(Speculative Fetch),执行按照预测结果取出的指令的行为称为预测执行(Speculative Execution)
随着预测算法的不断改进,当前分支预测的准确率不断向1逼近,分支预测技术有效提高了流水线的运行效率,被大量运用到主流微处理器中。
一、分支预测需要解决的问题
(1)、预测分支是否发生,即预测“方向”的问题;
(2)、预测分支指令设置的取值地址,即预测“目标地址”的问题。
二、分支预测单元的设计实现
常见的分支预测机制主要可分为一级结构和两级结构。对于两级预测器,常见的算法包括gshare和gselect算法,这种算法考虑到分支指令的上下文执行历史,精度相对较高,但实现相对复杂,本文不予讨论。对于一级预测器,其设计是将多个饱和计数器和BPU组织成一维向量表,利用分支/跳转指令PC值的hash映射值寻址一维向量表。这种预测器结构最为简单,本文将针对这种结构做详细的讨论。
2.1 分支方向的预测
本文采用2bit的饱和计数器,用于寄存4种状态。根据预测结果和实际执行结果,计数器的值将按照如下所示状态机转移图转移。
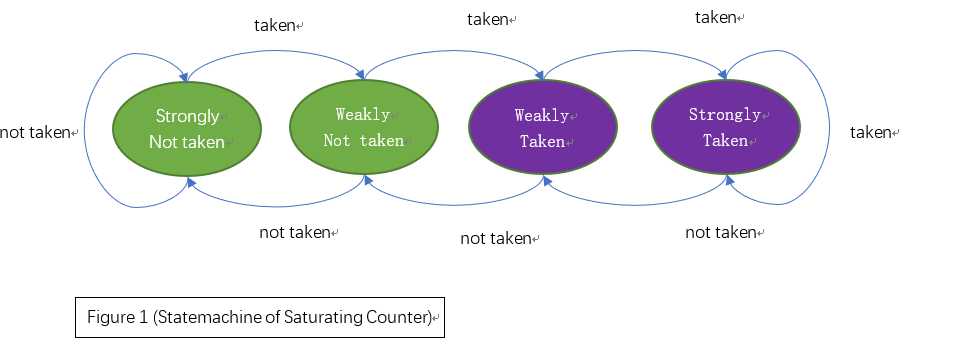
图中跳转(taken)和不跳转(not taken)两种状态分别被进一步细分为强(strong)和弱(weak)共四种状态,并规定strongly taken和weakly taken为“跳转”、strongly not taken和weakly not taken为“不跳转”,且每当预测出错后,计数器会以相反方向更改状态,这种做法的本质其实是一种“阻尼式”的切换。
2.2 分支目标地址的预测
为了简化设计,本文主要讨论基于分支目标缓存(Branch Target Buffer)技术的预测器。BTB使用容量有限的缓存寄存最近执行的分支指令的目标地址。对于后续分支指令,预测时直接取出对应表项中寄存的地址作为目标地址预测值。当分支指令被执行后,将实际的目标地址回写入BTB中,为下次预测提供依据。
本设计中,使用使用分支指令PC值的hash映射值寻址BTB表项,使得每条分支跳转指令都能与BTB表项建立起映射关系。
其中,我们定义PC值的hash映射规则如下:
∫ V(PC) → V(hash), f(p) , f(p) = p & 1111111111b (即取出PC值的低10位作为对应的hash映射值)
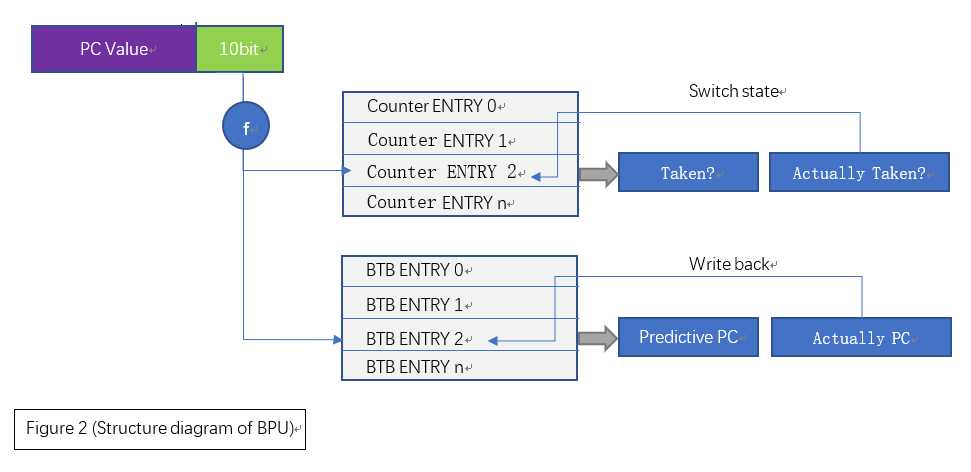
2.3 设计总体框架
综上所述,分支预测器的总体结构如下,可以看出,该预测器具有极其简单的结构:
三、硬件描述语言实现
通过以上讨论,容易使用Verilog HDL实现分支预测器。
值得注意的是,这里仅对饱和计数器进行非溢出的递增或递减,利用计数值的最高位判断是否发生跳转,1为taken,0为not taken。
1 module bpu 2 #( 3 parameter PCW = 30, // The width of valid PC 4 parameter BTBW = 10, // The width of btb address 5 ) 6 (/*AUTOARG*/ 7 // Outputs 8 pre_taken_o, pre_target_o, 9 // Inputs 10 clk, rst_n, pc_i, set_i, set_pc_i, set_taken_i, set_target_i 11 ); 12 13 // Ports 14 input clk; 15 input rst_n; 16 input [PCW-1:0] pc_i; // PC of current branch instruction 17 input set_i; 18 input [PCW-1:0] set_pc_i; 19 input set_taken_i; 20 input [PCW-1:0] set_target_i; 21 output reg pre_taken_o; 22 output reg [PCW-1:0] pre_target_o; 23 24 // Local Parameters 25 localparam SCS_STRONGLY_TAKEN = 2‘b11; 26 localparam SCS_WEAKLY_TAKEN = 2‘b10; 27 localparam SCS_WEAKLY_NOT_TAKEN = 2‘b01; 28 localparam SCS_STRONGLY_NOT_TAKEN = 2‘b00; 29 30 wire bypass; 31 wire [BTBW-1:0] tb_entry; 32 wire [BTBW-1:0] set_tb_entry; 33 34 // PC Address hash mapping 35 assign tb_entry = pc_i[BTBW-1:0]; 36 assign set_tb_entry = set_pc_i[BTBW-1:0]; 37 assign bypass = set_i && set_pc_i == pc_i; 38 39 // Saturating counters 40 reg [1:0] counter[(1<<BTBW)-1:0]; 41 generate begin :counter 42 integer entry; 43 always @(posedge clk or negedge rst_n) 44 if(!rst_n) 45 for(entry=0; entry < (1<<BTBW); entry=entry+1) // reset BTB entries 46 counter[entry] <= 2‘b00; 47 else if(set_i && set_taken_i && counter[set_tb_entry] != SCS_STRONGLY_TAKEN) begin 48 counter[set_tb_entry] <= counter[set_tb_entry] + 2‘b01; 49 else if(set_i && !set_taken_i && counter[set_tb_entry] != SCS_STRONGLY_NOT_TAKEN) begin 50 counter[set_tb_entry] <= counter[set_tb_entry] - 2‘b01; 51 end 52 endgenerate 53 54 always @(posedge clk) 55 pre_taken_o <= bypass ? set_taken_i : counter[tb_entry][1]; 56 57 // BTB vectors 58 reg [PCW-1:0] btb[(1<<BTBW)-1:0]; 59 60 generate begin :btb_rst 61 integer entry; 62 always @(posedge clk or negedge rst_n) 63 if(!rst_n) 64 for(entry=0; entry < (1<<BTBW); entry=entry+1) begin // reset BTB entries 65 btb[entry] <= {PCW{1‘b0}}; 66 end 67 endgenerate 68 69 always @(posedge clk) 70 pre_target_o <= bypass ? set_pc_i : btb[tb_entry]; 71 72 always @(posedge clk) 73 if( set_i ) 74 btb[set_tb_entry] <= set_target_i; 75 76 endmodule
对该实现需要做如下说明:
(1)、BPU在每个时钟周期内完成预测和更新。pc_i端口输入待预测的指令PC值,set_i端口指示是否在下一个时钟周期到来时更新预测器。
(2)、考虑到特殊的指令流情况,该实现添加了旁路(bypass)机制。对于具体的处理器实现,可能永远不会触发旁路,因此可以去掉这部分实现。
(3)、对于在BTB中没有记录的分支指令,BPU默认预测目标地址输出为0(BTB在此之前进行过置零复位)。对于具体的处理器实现,可考虑将分支指令的下一条指令的PC值作为目标地址的预测值。
四、总结
通过讨论,我们提出了基于饱和计数器和BTB的分支预测单元的设计思路,并最终利用Verilog实现了该分支预测器的原型。该实现在面积上具有一定优势,可运用于微处理器实验和验证等方面;同时,该设计也存在一些不足之处:
(1)、在求PC值的hash映射值时,仅简单地取PC低10bit的数据作为BTB的索引,这将导致PC值高位相同的分支指令的记录状态互相混淆,从而降低预测精度;
(2)、该设计仅考虑分支指令的全局状态,而没有跟踪分支指令具体的上下文环境;
(3)、对于带条件判断的分支指令、或寄存器直接/间接寻址的跳转指令,由于其操作数保存在寄存器中,而寄存器的值往往是不断变化的,这将导致对分支目标地址的预测精度降低。
===================================================
本博文仅供参考,难免有错误或疏漏之处,欢迎提出宝贵意见。
【CPU微架构设计】利用Verilog设计基于饱和计数器和BTB的分支预测器
标签:mod tar red 框架 缓存 address end int 经典的
原文地址:https://www.cnblogs.com/sci-dev/p/9817676.html