标签:行数据 ima bubuko 流程 settings set info efi rap
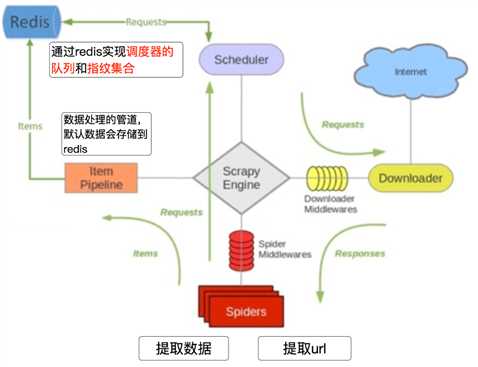
我们从settings.py中的三个配置来进行分析 分别是:
RedisPipeline中观察process_item,进行数据的保存,存入了redis中

RFPDupeFilter 实现了对request对象的加密

scrapy_redis调度器的实现了决定什么时候把request对象加入带抓取的队列,同时把请求过的request对象过滤掉

由此可以总结出request对象入队的条件
标签:行数据 ima bubuko 流程 settings set info efi rap
原文地址:https://www.cnblogs.com/caijunchao/p/9911745.html