标签:步骤 max http har 时间复杂度 include register string 一个
首先,在学树链剖分之前最好先把 LCA、树形DP、DFS序 这三个知识点学了还有必备的 链式前向星、线段树 也要先学了。如果这些个知识点没掌握好的话,树链剖分难以理解也是当然的
树链剖分 就是对一棵树分成几条链,把树形变为线性,减少处理难度
需要处理的问题:
首先我们要了解这些概念
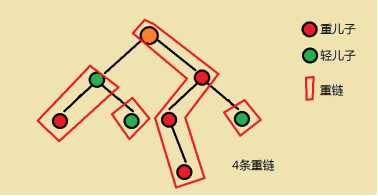
dfs1()
这个dfs要处理几件事情:
void dfs1(int u,int ff)
{
dep[u]=dep[ff]+1;fa[u]=ff;size[u]=1;
int maxn=0;
for(int i=head[u],v=e[i].to;i;i=e[i].nxt,v=e[i].to) if(v!=ff)
{
dfs1(v,u);
size[u]+=size[v];
if(size[v]>maxn) maxn=size[v],son[u]=v;
}
}
dfs2()
这个dfs2也要预处理几件事情
顺序:先处理重儿子再处理轻儿子,理由后面说
void dfs2(int u,int topf)
{
id[u]=++tim;wn[tim]=w[u];
top[u]=topf;
if(!son[u]) return;
dfs2(son[u],topf);
for(int i=head[u],v=e[i].to;i;i=e[i].nxt,v=e[i].to) if(v!=fa[u]&&v!=son[u])
dfs2(v,v);
}
处理问题
Attention 重要的来了!!!
前面说到dfs2的顺序是先处理重儿子再处理轻儿子 我们来模拟一下:
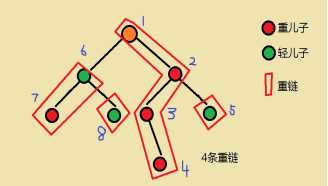
现在回顾一下我们要处理的问题
1、当我们要处理任意两点间路径时:
设所在链顶端的深度更深的那个点为x点
不停执行这两个步骤,直到两个点处于一条链上,这时再加上此时两个点的区间和即可
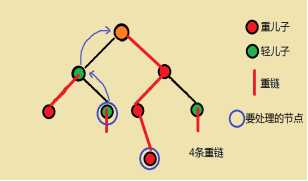
这时我们注意到,我们所要处理的所有区间均为连续编号(新编号),于是想到线段树,用线段树处理连续编号区间和每次查询时间复杂度为O(log2n)
void update_tree(int u,int v,int val) { while(top[u]!=top[v]) { if(dep[top[u]]<dep[top[v]]) swap(u,v); update(id[top[u]],id[u],val,1,n,1); u=fa[top[u]]; } if(dep[u]<dep[v]) swap(u,v); update(id[v],id[u],val,1,n,1); } int query_tree(int u,int v) { int ans=0; while(top[u]!=top[v]) { if(dep[top[u]]<dep[top[v]]) swap(u,v); ans=(ans+query(id[top[u]],id[u],1,n,1))%mod; u=fa[top[u]]; } if(dep[u]<dep[v]) swap(u,v); return (ans+query(id[v],id[u],1,n,1))%mod; }
总体代码如下:
#include <iostream> #include <cstdio> #include <cstring> #include <cmath> #include <map> #include <cstdlib> #include <algorithm> #include <queue> #include <stack> #define lson l,mid,o<<1 #define rson mid+1,r,o<<1|1 using namespace std; inline int read() { int a=0,q=0; char ch=getchar(); while((ch<‘0‘||ch>‘9‘)&&ch!=‘-‘) ch=getchar(); if(ch==‘-‘) q=1,ch=getchar(); while(ch>=‘0‘&&ch<=‘9‘) a=(a<<3)+(a<<1)+ch-48,ch=getchar(); return q?-a:a; } const int N=200100; int n,m,r,mod,u,v,w[N],wn[N],head[N],dep[N],fa[N],top[N],size[N],son[N],id[N],sum[N<<2],tag[N<<2],cnt=0,tim=0,op,x,y,z; struct EDGE{int to,nxt;}e[N<<1]; void add(int u,int v) { e[++cnt]=(EDGE){v,head[u]}; head[u]=cnt; } void pushdown(int lnum,int rnum,int o) { if(tag[o]) { tag[o<<1]+=tag[o]; tag[o<<1|1]+=tag[o]; (sum[o<<1]+=tag[o]*lnum)%=mod; (sum[o<<1|1]+=tag[o]*rnum)%=mod; tag[o]=0; } } void build(int l,int r,int o) { if(l==r){sum[o]=wn[l]%mod;return;} int mid=(l+r)>>1; build(lson); build(rson); sum[o]=(sum[o<<1]+sum[o<<1|1])%mod; } void update(int L,int R,int val,int l,int r,int o) { if(L<=l&&r<=R){tag[o]+=val,(sum[o]+=(r-l+1)*val)%=mod;return;} int mid=(l+r)>>1; pushdown(mid-l+1,r-mid,o); if(L<=mid) update(L,R,val,lson); if(R> mid) update(L,R,val,rson); sum[o]=(sum[o<<1]+sum[o<<1|1])%mod; } int query(int L,int R,int l,int r,int o) { if(L<=l&&r<=R) {return sum[o]%mod;} int mid=(l+r)>>1,ans=0; pushdown(mid-l+1,r-mid,o); if(L<=mid) (ans+=query(L,R,lson))%=mod; if(R> mid) (ans+=query(L,R,rson))%=mod; return ans; } void dfs1(int u,int ff) { dep[u]=dep[ff]+1;fa[u]=ff;size[u]=1; int maxn=0; for(int i=head[u],v=e[i].to;i;i=e[i].nxt,v=e[i].to) if(v!=ff) { dfs1(v,u); size[u]+=size[v]; if(size[v]>maxn) maxn=size[v],son[u]=v; } } void dfs2(int u,int topf) { id[u]=++tim;wn[tim]=w[u]; top[u]=topf; if(!son[u]) return; dfs2(son[u],topf); for(int i=head[u],v=e[i].to;i;i=e[i].nxt,v=e[i].to) if(v!=fa[u]&&v!=son[u]) dfs2(v,v); } void update_tree(int u,int v,int val) { while(top[u]!=top[v]) { if(dep[top[u]]<dep[top[v]]) swap(u,v); update(id[top[u]],id[u],val,1,n,1); u=fa[top[u]]; } if(dep[u]<dep[v]) swap(u,v); update(id[v],id[u],val,1,n,1); } int query_tree(int u,int v) { int ans=0; while(top[u]!=top[v]) { if(dep[top[u]]<dep[top[v]]) swap(u,v); ans=(ans+query(id[top[u]],id[u],1,n,1))%mod; u=fa[top[u]]; } if(dep[u]<dep[v]) swap(u,v); return (ans+query(id[v],id[u],1,n,1))%mod; } int main() { n=read(),m=read(),r=read(),mod=read(); for(register int i=1;i<=n;i++) scanf("%d",&w[i]); for(register int i=1;i<n;i++) { u=read(),v=read(); add(u,v);add(v,u); } dfs1(r,r);dfs2(r,r); build(1,n,1); while(m--) { op=read(); if(op==1) { x=read(),y=read(),z=read(); update_tree(x,y,z); } else if(op==2) { x=read(),y=read(); printf("%d\n",query_tree(x,y)%mod); } else if(op==3) { x=read(),y=read(); update(id[x],id[x]+size[x]-1,y,1,n,1); } else { x=read(); printf("%d\n",query(id[x],id[x]+size[x]-1,1,n,1)); } } return 0; }
标签:步骤 max http har 时间复杂度 include register string 一个
原文地址:https://www.cnblogs.com/cold-cold/p/9991779.html