标签:svc 地址 source mozilla 形式 opp ESS .mm ali
打开微信随便选择一个公众号,查看公众号的所有历史文章列表

在 Fiddler 上已经能看到有请求进来了,说明公众号的文章走的都是HTTPS协议,这些请求就是微信客户端向微信服务器发送的HTTP请求。
模拟微信请求 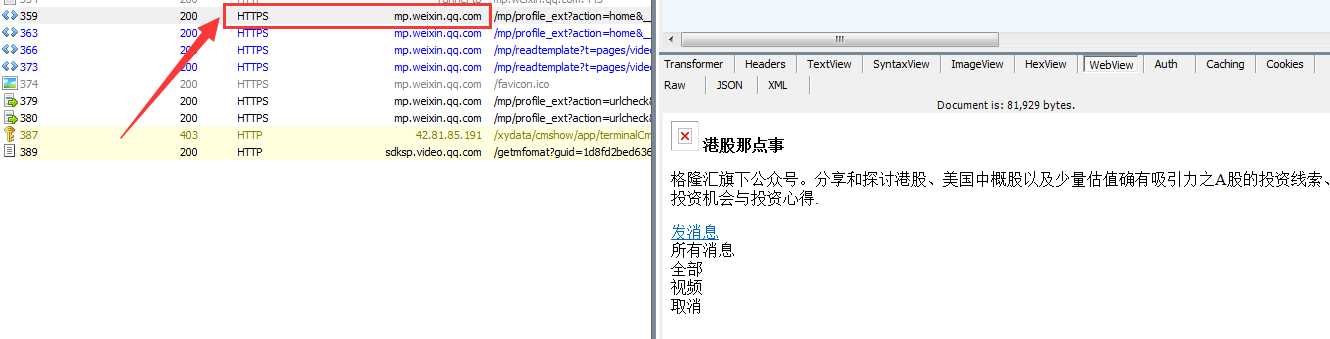
1、服务器的响应结果,200 表示服务器对该请求响应成功
2、请求协议,微信的请求协议都是基 于HTTPS 的,所以Fiddle一定要配置好,不然你看不到 HTTPS 的请求。
3、请求路径,包括了请求方法(GET),请求协议(HTTP/1.1),请求路径(/mp/profile_ext...后面还有很长一串参数)
4、包括Cookie信息在内的请求头。
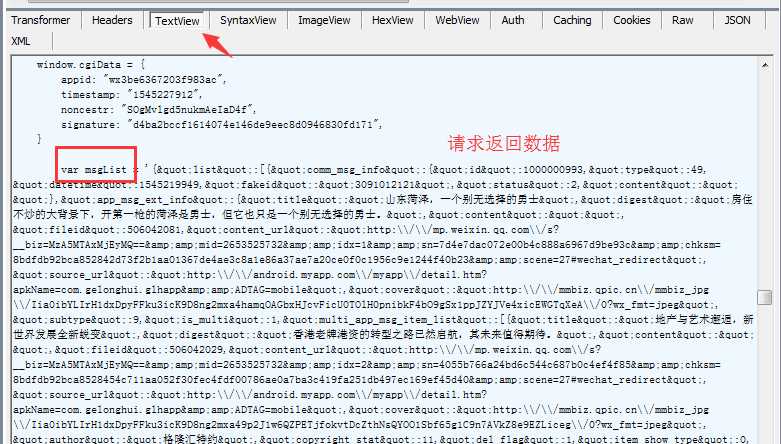
5、微信服务器返回的响应数据。
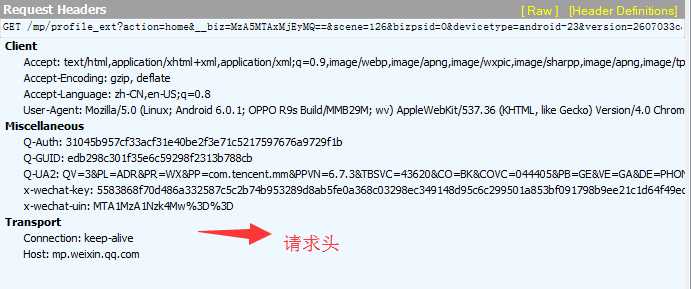
确定微信公众号的请求HOST是 mp.weixin.qq.com 之后,我们可以使用过滤器来过滤掉不相关的请求。
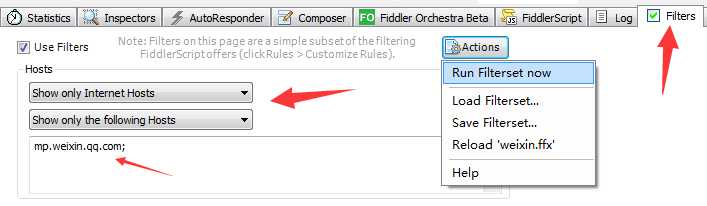
爬虫的基本原理就是模拟浏览器发送 HTTP 请求,然后从服务器得到响应结果,现在我们就用 Python 实现如何发送一个 HTTP 请求。这里我们使用 requests 库来发送请求。
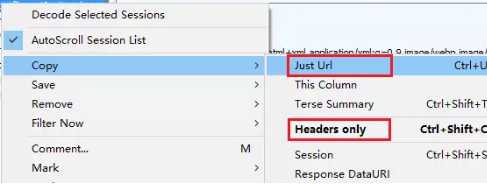
我们直接从 Fiddler 请求中拷贝 URL 和 Headers, 右键 -> Copy -> Just Url/Headers Only
url = ‘https://mp.weixin.qq.com/mp/profile_ext‘ ‘?action=home‘ ‘&__biz=MzA5MTAxMjEyMQ==‘ ‘&scene=126‘ ‘&bizpsid=0‘ ‘&devicetype=android-23‘ ‘&version=2607033c‘ ‘&lang=zh_CN‘ ‘&nettype=WIFI‘ ‘&a8scene=3‘ ‘&pass_ticket=LvcLsR1hhcMXdxkZjCN49DcQiOsCdoeZdyaQP3m5rwXkXVN7Os2r9sekOOQULUpL‘ ‘&wx_header=1‘
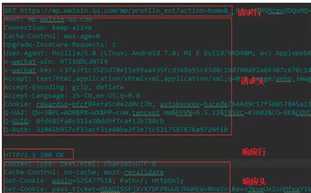
因为 requests.get 方法里面的 headers 参数必须是字典对象,所以,先要写个函数把刚刚拷贝的字符串转换成字典对象。
def headers_to_dict(headers): """ 将字符串 ‘‘‘ Host: mp.weixin.qq.com Connection: keep-alive Cache-Control: max-age= ‘‘‘ 转换成字典对象 { "Host": "mp.weixin.qq.com", "Connection": "keep-alive", "Cache-Control":"max-age=" } :param headers: str :return: dict """ headers = headers.split("\n") d_headers = dict() for h in headers: if h: k, v = h.split(":", 1) d_headers[k] = v.strip() return d_headers
公众号历史文章数据就在 response.text 中。如果返回的内容非常短,而且title标签是<title>验证</title>,
那么说明你的请求参数或者请求头有误,最有可能的一种请求就是 Headers 里面的 Cookie 字段过期,
从手机微信端重新发起一次请求获取最新的请求参数和请求头试试
response = requests.get(url, headers=headers_to_dict(headers), verify=False) print(response.text) if ‘<title>验证</title>‘ in response.text: raise Exception("获取微信公众号文章失败,可能是因为你的请求参数有误,请重新获取") # with open("weixin_history.html", "w", encoding="utf-8") as f: # f.write(response.text)
历史文章封装在叫 msgList 的数组中(实际上该数组包装在字典结构中),这是一个 Json 格式的数据,但是里面还有 html 转义字符需要处理

写一个方法提取出历史文章数据,分三个步骤,首先用正则提取数据内容,然后 html 转义处理,最终得到一个列表对象,返回最近发布的10篇文章
def extract_data(html_content): """ 从html页面中提取历史文章数据 :param html_content 页面源代码 :return: 历史文章列表 """ import re import html import json rex = "msgList = ‘({.*?})‘" # 正则表达 pattern = re.compile(pattern=rex, flags=re.S) match = pattern.search(html_content) if match: data = match.group(1) data = html.unescape(data) # 处理转义 # print(‘data: {}‘.format(data)) data = json.loads(data) articles = data.get("list") for item in articles: print(item) return articles
最终提取出来的数据总共有10条,就是最近发表的10条数据,我们看看每条数据返回有哪些字段。

发送时间对应comm_msg_info.datetime,app_msg_ext_info中的字段信息就是第一篇文章的字段信息,分别对应:
后面几篇文章以列表的形式保存在 multi_app_msg_item_list 字段中。

详细代码
import requests url = ‘https://mp.weixin.qq.com/mp/profile_ext‘ ‘?action=home‘ ‘&__biz=MzA5MTAxMjEyMQ==‘ ‘&scene=126‘ ‘&bizpsid=0‘ ‘&devicetype=android-23‘ ‘&version=2607033c‘ ‘&lang=zh_CN‘ ‘&nettype=WIFI‘ ‘&a8scene=3‘ ‘&pass_ticket=LvcLsR1hhcMXdxkZjCN49DcQiOsCdoeZdyaQP3m5rwXkXVN7Os2r9sekOOQULUpL‘ ‘&wx_header=1‘ headers =‘‘‘ Host: mp.weixin.qq.com Connection: keep-alive User-Agent: Mozilla/5.0 (Linux; Android 6.0.1; OPPO R9s Build/MMB29M; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.132 MQQBrowser/6.2 TBS/044405 Mobile Safari/537.36 MMWEBID/5576 MicroMessenger/6.7.3.1360(0x2607033C) NetType/WIFI Language/zh_CN Process/toolsmp x-wechat-key: d2bc6fe213fd0db717e11807caca969ba1d7537e57fc89f64500a774dba05a4f1a83ae58a3d039efc6403b3fa70ebafb52cfd737b350b58d0dca366b5daf92027aaefcb094932df5a18c8764e98703dc x-wechat-uin: MTA1MzA1Nzk4Mw%3D%3D Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,image/wxpic,image/sharpp,image/apng,image/tpg,/;q=0.8 Accept-Encoding: gzip, deflate Accept-Language: zh-CN,en-US;q=0.8 Q-UA2: QV=3&PL=ADR&PR=WX&PP=com.tencent.mm&PPVN=6.7.3&TBSVC=43620&CO=BK&COVC=044405&PB=GE&VE=GA&DE=PHONE&CHID=0&LCID=9422&MO= OPPOR9s &RL=1080*1920&OS=6.0.1&API=23 Q-GUID: edb298c301f35e6c59298f2313b788cb Q-Auth: 31045b957cf33acf31e40be2f3e71c5217597676a9729f1b ‘‘‘ def headers_to_dict(headers): """ 将字符串 ‘‘‘ Host: mp.weixin.qq.com Connection: keep-alive Cache-Control: max-age= ‘‘‘ 转换成字典对象 { "Host": "mp.weixin.qq.com", "Connection": "keep-alive", "Cache-Control":"max-age=" } :param headers: str :return: dict """ headers = headers.split("\n") d_headers = dict() for h in headers: if h: k, v = h.split(":", 1) d_headers[k] = v.strip() return d_headers # with open("weixin_history.html", "w", encoding="utf-8") as f: # f.write(response.text) def extract_data(html_content): """ 从html页面中提取历史文章数据 :param html_content 页面源代码 :return: 历史文章列表 """ import re import html import json rex = "msgList = ‘({.*?})‘" # 正则表达 pattern = re.compile(pattern=rex, flags=re.S) match = pattern.search(html_content) if match: data = match.group(1) data = html.unescape(data) # 处理转义 # print(‘data: {}‘.format(data)) data = json.loads(data) articles = data.get("list") return articles def crawl(): """ 爬取文章 :return: """ response = requests.get(url, headers=headers_to_dict(headers), verify=False) print(response.text) if ‘<title>验证</title>‘ in response.text: raise Exception("获取微信公众号文章失败,可能是因为你的请求参数有误,请重新获取") data = extract_data(response.text) for item in data: print(item[‘app_msg_ext_info‘]) if __name__ == ‘__main__‘: crawl()
标签:svc 地址 source mozilla 形式 opp ESS .mm ali
原文地址:https://www.cnblogs.com/xiao-apple36/p/10146824.html