标签:架构 strong 1.5 board 默认 quick rdate 根据 水平
Algorithm:每周至少做一个leetcode的算法题;
Review:阅读并点评至少一篇英文技术文章;
Tip/Techni:学习至少一个技术技巧;
Share:分享一篇有观点和思考的技术文章。
本题是链表相关的一道题,题目给出一个链表,问我们这个链表中是否有环。题目中给出了三个例子来帮助我们分析是否有环,我们可以简单理解为,判断链表中是否有节点被超过两个节点的next指针指向,如果有就存在环,如果没有就无环。
?
第一种方法
我们一次遍历链表中的各个节点,并把遍历过节点存到一个set中,每次遍历下一个节点的时候先判断是否它是否存在于set中,如果存在则表示此链表存在环,如果遍历完整个链表都没有发现重复节点,则表示此链表不存在环。
?
第二种方法
设置两个快慢指针,一个指向第一个节点取名为slow,另一个指向第二个节点,取名为fast,slow指针每次走一步,即slow = slow.next,fast指针每次走两步,即fast = fast.next.next,遍历过程中判断slow和fast的值是否相等,如果有环,fast指针会追上slow指针,如果没环,最终fast或fast.next的值会是null。
第一种方法
public boolean hasCycle(ListNode head) {
Set<ListNode> nodes = new HashSet<>();
if (head == null || head.next == null){
return false;
}
while (head.next != null){
if (nodes.contains(head)) {
return true;
}else{
nodes.add(head);
head = head.next;
}
}
return false;
}?
第二种方法
public boolean hasCycle(ListNode head) {
if (head == null || head.next == null){
return false;
}
ListNode quick = head.next;
ListNode slow = head;
while (quick != slow){
if (quick == null || quick.next == null){
return false;
}
quick = quick.next.next;
slow = slow.next;
}
return true;
}这周在medium上看了一篇文章How to work optimally with relational databases,意思就是“如何更好地使用关系型数据库”。下面我就对这篇文章中的主要内容进行翻译(如有错误,敬请指正),完整原文请点击前文链接前往阅读。
MySQL是一种关系型数据库,它的数据是由一行行tuple表示,所有tuple组成一个relation,每行tuple用它的属性来表示。关系如下图所示:
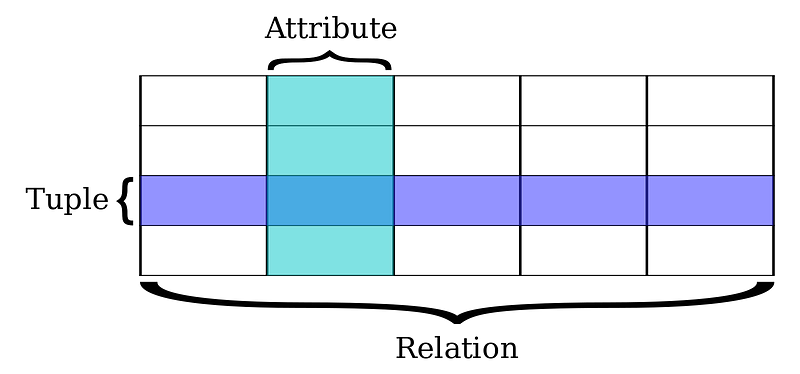
假设我们有一个借书的应用,我们需要存储所有图书的借阅记录,为了存储它们,我们用下面的sql语句创建一个简单的关系表:
> CREATE TABLE book_transactions ( id INTEGER NOT NULL AUTO_INCREMENT, book_id INTEGER, borrower_id INTEGER, lender_id INTEGER, return_date DATE, PRIMARY KEY (id));?
这个表看起来就像这样:
book_transactions
------------------------------------------------
id borrower_id lender_id book_id return_date?
这里的** id **是主键, borrower_id, lender_id, book_id都是外键,在我们使用我们的应用之后会生成几条记录:
book_transactions
------------------------------------------------
id borrower_id lender_id book_id return_date
------------------------------------------------
1 1 1 1 2018-01-13
2 2 3 2 2018-01-13
3 1 2 1 2018-01-13我们的应用有一个dashboard页允许用户去查看他们借阅图书的记录,那么让我们来获取某个用户的借阅记录:
> SELECT * FROM book_transactions WHERE borrower_id = 1;
book_transactions
------------------------------------------------
id borrower_id lender_id book_id return_date
------------------------------------------------
1 1 1 1 2018-01-13
2 1 2 1 2018-01-13?
这会顺序扫描关系表并把这个用户的数据返回给我们。这看起来很快,因为我们的关系表数据很少。为了能看到精确的查询时间,我们通过下面的命令把** set profiling **设置成true:
> set profiling=1;?
一旦设置了profiling参数,再此运行查询语句的时候,使用下面的命令就能看到执行时间:
> show profiles;?
这将返回我们执行的查询命所花费的时间。
Query_ID | Duration | Query
1 | 0.00254000 | SELECT * FROM book_transactions ... ?
执行速度似乎很快。
慢慢地,book_transactions表数据越来越多,因为会一直产生很多的记录。
这在我们的关系表中增加了tuples的数量,接着,用户获取借阅记录的时间开始变得更长。MySQL需要遍历所有的tuples去找到结果。
为了插入很多数据到这个表,我写了下面的存储过程:
DELIMITER //
CREATE PROCEDURE InsertALot()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE (i <= 100000) DO
INSERT INTO book_transactions (borrower_id, lender_id, book_id, return_date) VALUES ((FLOOR(1 + RAND() * 60)), (FLOOR(1 + RAND() * 60)), (FLOOR(1 + RAND() * 60)), CURDATE());
SET i = i+1;
END WHILE;
END //
DELIMITER ;
* It took around 7 minutes to insert 1.5 million data?
这个存储过程插入了100000条随机数据到我们的book_transactions表,在运行完这个存储过程以后,分析器显示运行时间有略微增长:
Query_ID | Duration | Query
1 | 0.07151000 | SELECT * FROM book_transactions ...?
让我们多加一点数据,运行上面的存储过程,然后看看会发生什么。随着加入越来越多的数据,查询时长也在随之增加。当有1.5百万数据插入到这张表的时候,查询的响应时间已经明显加长了。
Query_ID | Duration | Query
1 | 0.36795200 | SELECT * FROM book_transactions ...?
这只是一个简单的涉及整数字段的查询。
随着更多的复合查询,排序查询和计数查询,执行时间将变得更长。
对于单个查询,这似乎不是一个很长的时间,但当我们每分钟运行数千甚至上百万的查询的时候,就会有很大的不同。
将有更长的等待时间,这会降低整个应用的性能。同样的一个查询,执行时间会从2ms增加到370ms。
MySQL和其他数据库提供了索引,一种有助于更快获取数据的数据结构。
在MySQL中,有不同类型的索引:
索引存储的方式主要有两种:
Hash -- 这种方式主要用于精确匹配,不适用于比较。
B-Tree -- 这是存储上面提到的索引类型最常用的方式。
MySQL适用B-Tree作为它的默认索引格式,数据存储在一颗二叉树中,这样能快速检索数据。
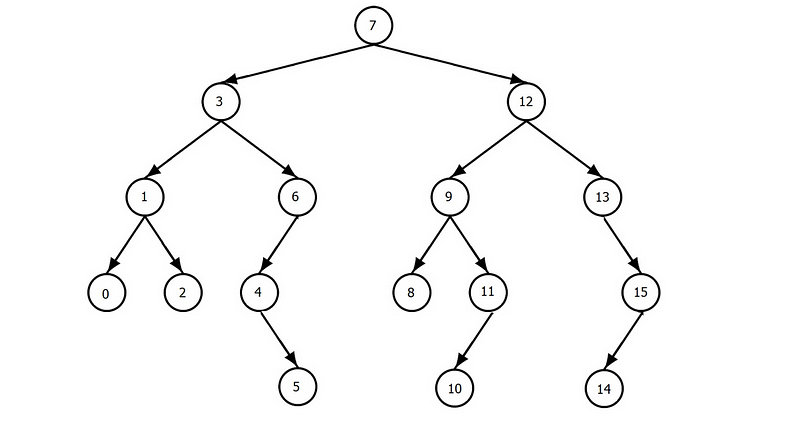
用B-Tree组织数据有助于跳过关系表中所有tuples的全表扫描。
上面图中的B-Tree一共有16个节点,假设我们需要找到数字6,我们总共只需要遍历3次就能找到这个数,这有助于提高搜索性能。
所以要提高book_transactions表的性能,让我们在lender_id字段上添加索引。
> CREATE INDEX lenderId ON book_transactions(lender_id)
----------------------------------------------------
* It took around 6.18sec Adding this index?
上面的命令在lender_id字段上添加了一个索引。重新运行之前的查询语句,让我们来看看它如何影响我们拥有的1.5百万数据的性能。
> SELECT * FROM book_transactions WHERE lender_id = 1;
Query_ID | Duration | Query
1 | 0.00787600 | SELECT * FROM book_transactions ...?
哇,又像之前那么快了!
现在和只有3条记录的时候一样快,通过正确的索引添加,我们能看到显著的性能提升。
刚才我们添加的是单一索引,索引也能加到复合字段上。
如果我们的查询包含多个字段,一个复合索引将帮助我们,我们可以使用下面的命令来添加一个复合索引:
> CREATE INDEX lenderReturnDate ON book_transactions(lender_id, return_date);查询不是索引唯一的用途,它们也能被用在ORDER BY条件上,让我们根据lender_id字段对所有记录排序。
> SELECT * FROM book_transactions ORDER BY lender_id;
1517185 rows in set (4.08 sec)?
4.08 秒,太长了!出了什么问题吗?我们明明加了索引。让我们借助EXPLAIN语句深入研究看看这个查询语句是怎么被执行的。
我们添加一个explain语句来看这个查询在我们当前的数据集中究竟是怎么执行的。
> EXPLAIN SELECT * FROM book_transactions ORDER BY lender_id;?
输出如下:

explain语句返回了几个字段,让我们看看上图中的表格来找到问题所在。
rows:被扫描的行数
filtered:获取数据时被扫描行所占的百分比
type:如果使用索引则给出,ALL表示没有使用索引
possible_keys, key, key_len 都是NULL,表示没有使用索引
那么为什么这个查询没有用索引?
这是因为我们在查询语句使用了select *,意味着我们会查询表中的所有字段。
索引只有那些加了索引的字段的信息,不包含其他字段,这意味着MySQL需要去主表再次获取数据。
那么我们应该如何写我们的查询语句?
要删除转到主表的查询,我们需要只查索引表中存在的值。让我们修改一下查询语句:
> SELECT lender_id FROM book_transactions ORDER BY lender_id;?
这将在0.46秒内返回结果,哪个更快?但还是有提高的余地。
当这个查询是在1.5百万条记录上完成的,它需要花费更多的时间去加载数据到内存。
我们或许不需要一次性获取1.5百万条数据。使用LIMIT批量获取数据代替获取全量数据是一种更好的方式。
> SELECT lender_id
FROM book_transactions
ORDER BY lender_id LIMIT 1000;?
有了LIMIT,响应时间大大提升,只需要0.0025秒。我们能使用OFFSET获取下一批数据。
> SELECT lender_id
FROM book_transactions
ORDER BY lender_id LIMIT 1000 OFFSET 1000;?
这会获取下一批1000条数据,用这种方式我们可以增加offset和limit获取所有数据。但是有一个陷阱,随着offset的增加,查询性能也会下降。
这是因为MySQL会扫描全表数据去到达offset点,因此最好不要使用很高的offset。
InnoDB引擎有并发写的能力。这使其具有高扩展性并提高了每秒的吞吐量。
但这是有代价的,InnoDB无法为任意表记录数添加缓存计数器。所以,计数器必须通过遍历所有过滤数据完成实时计数,这使得COUNT查询比较慢。
所以推荐在应用逻辑里为大数据量的数据计算总计数。
增加索引能提高性能,但它也有代价。应该有效地使用,给更多的字段增加索引会有下面的问题:
我们知道添加索引很有帮助,但我们不能在所有数据上都添加索引除非它能提升性能。
当我们构建索引的时候,我们只有索引字段的信息,没有索引中不存在的字段数据。
那么,就如前文说的,MySQL需要回表获取别的字段数据,这会减慢执行时间。
我们可以使用分区来解决这个问题。
分区是一种技术,MySQL将一张表的数据拆分成多张表,但还是当一张表来管理。
在表中执行任何类型的操作时,我们需要指定正在使用的分区。随着数据被分解,MySQL有一个较小的数据集可供查询,根据需要确定正确的分区是高性能的关键。
但如果我们一直用同一台机器,它能扩展吗?
当面对庞大的数据集,将所有数据存储在同一台机器上可能会很麻烦。
特定分区可能很重,需要更多查询,而其他分区则较少。所以一个会影响另一个。它们无法单独扩展。
假设最近三个月的数据是最常用的,而较旧的数据使用较少。也许最近的数据大多是更新/创建的,而旧的数据大多只是被读过。
要解决此问题,我们可以将最近三个月的分区移动到另一台计算机。
分片是一种将大数据集分成较小块的方式,然后转移到单独的RDBMS。换句话说,分片也可以称为“水平分区”。
关系数据库能够随着应用程序的增长而扩展。找出正确的索引并根据需要调整基础架构是必要的。
本周分享一个cpu占用100%问题的解决方法,主要用到两个命令top和perf,top用来确认引发 CPU 性能问题的来源;perf用来排查出引起性能问题的具体函数。
具体示例
使用top命令查看当前cpu使用率,按下数字1,切换到每个cpu的使用率:
$ top
...
%Cpu0 : 98.7 us, 1.3 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 99.3 us, 0.7 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
...
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
21514 daemon 20 0 336696 16384 8712 R 41.9 0.2 0:06.00 php-fpm
21513 daemon 20 0 336696 13244 5572 R 40.2 0.2 0:06.08 php-fpm
21515 daemon 20 0 336696 16384 8712 R 40.2 0.2 0:05.67 php-fpm
21512 daemon 20 0 336696 13244 5572 R 39.9 0.2 0:05.87 php-fpm
21516 daemon 20 0 336696 16384 8712 R 35.9 0.2 0:05.61 php-fpm?
这里有多个使用率在40%左右的进程,我们找其中一个使用 perf 分析下:
# -g 开启调用关系分析,-p 指定 php-fpm 的进程号 21515
$ perf top -g -p 21515?
按方向键切换到 php-fpm,再按下回车键展开 php-fpm 的调用关系,调用关系最终到了 sqrt 和 add_function。

然后我们需要去源码中寻找这两个方法的踪迹,问题就藏在使用到这两个方法的地方。
今天分享一则轻松一点的讯息Mozilla 抱怨谷歌偏心! 火狐/Edge 加载 YouTube 缓慢,看到这则新闻的时候我瞬间联想到了最近美国和中国的贸易战,两者何其相似,都是强者无理欺负弱者而弱者只能抱怨的案例,自古以来亘古不变的真理就是强者才有话语权,实力说话,不然就要“挨打”,不仅仅是商场、外交是这样,生活中处处都是这个道理的鲜活例子,作为个人也要努力变强,这样才有话语权,才能有更多的自由做你想做的事,过你想过的生活。
标签:架构 strong 1.5 board 默认 quick rdate 根据 水平
原文地址:https://www.cnblogs.com/muxuanchan/p/10163948.html