标签:apach 之一 数据库 计算机 optimize mysql java oss 离线
一、Hadoop的应用业务分析大数据是不能用传统的计算技术处理的大型数据集的集合。它不是一个单一的技术或工具,而是涉及的业务和技术的许多领域。
目前主流的三大分布式计算系统分别为:Hadoop、Spark和Strom:
Hadoop当前大数据管理标准之一,运用在当前很多商业应用系统。可以轻松地集成结构化、半结构化甚至非结构化数据集。
Spark采用了内存计算。从多迭代批处理出发,允许将数据载入内存作反复查询,此外还融合数据仓库,流处理和图形计算等多种计算范式。Spark构建在HDFS上,能与Hadoop很好的结合。它的RDD是一个很大的特点。
Storm用于处理高速、大型数据流的分布式实时计算系统。为Hadoop添加了可靠的实时数据处理功能
Hadoop是使用Java编写,允许分布在集群,使用简单的编程模型的计算机大型数据集处理的Apache的开源框架。 Hadoop框架应用工程提供跨计算机集群的分布式存储和计算的环境。 Hadoop是专为从单一服务器到上千台机器扩展,每个机器都可以提供本地计算和存储。
Hadoop适用于海量数据、离线数据和负责数据,应用场景如下:
场景1:数据分析,如京东海量日志分析,京东商品推荐,京东用户行为分析
场景2:离线计算,(异构计算+分布式计算)天文计算
场景3:海量数据存储,如京东的存储集群
基于京麦业务三个实用场景
京麦用户分析
京麦流量分析
京麦订单分析
都属于离线数据,决定采用Hadoop作为京麦数据类产品的数据计算引擎,后续会根据业务的发展,会增加Storm等流式计算的计算引擎,下图是京麦的北斗系统架构图:
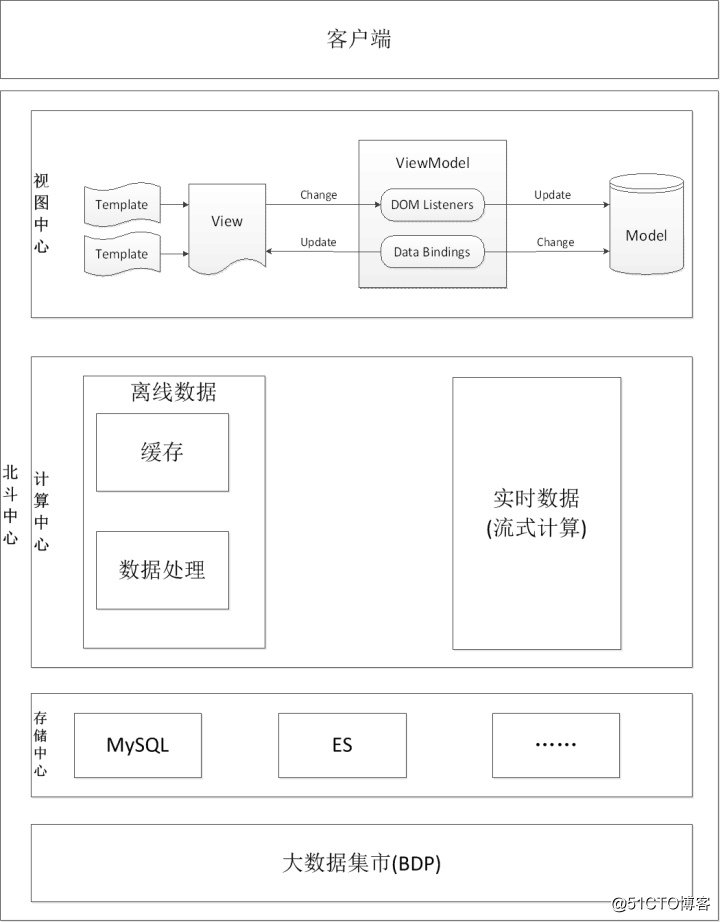
(图一)京东北斗系统
二、浅谈Hadoop的基本原理
Hadoop分布式处理框架核心设计
HDFS :(Hadoop Distributed File System)分布式文件系统
MapReduce: 是一种计算模型及软件架构
2.1 HDFS
HDFS(Hadoop File System),是Hadoop的分布式文件存储系统。
将大文件分解为多个Block,每个Block保存多个副本。提供容错机制,副本丢失或者宕机时自动恢复。默认每个Block保存3个副本,64M为1个Block。将Block按照key-value映射到内存当中。
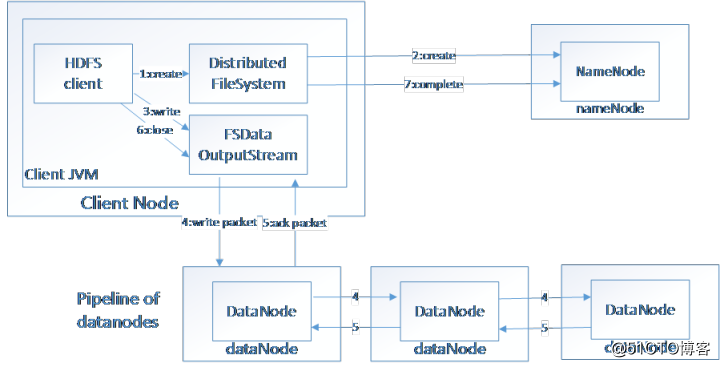
(图二)数据写入HDFS
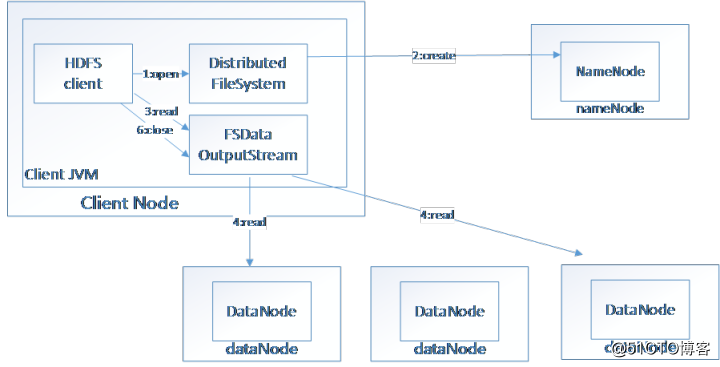
(图三)HDFS读取数据
2.2 MapReduce
MapReduce是一个编程模型,封装了并行计算、容错、数据分布、负载均衡等细节问题。MapReduce实现最开始是映射map,将操作映射到集合中的每个文档,然后按照产生的键进行分组,并将产生的键值组成列表放到对应的键中。化简(reduce)则是把列表中的值化简成一个单值,这个值被返回,然后再次进行键分组,直到每个键的列表只有一个值为止。这样做的好处是可以在任务被分解后,可以通过大量机器进行并行计算,减少整个操作的时间。但如果你要我再通俗点介绍,那么,说白了,Mapreduce的原理就是一个分治算法。
算法:
MapReduce计划分三个阶段执行,即映射阶段,shuffle阶段,并减少阶段。
映射阶段:映射或映射器的工作是处理输入数据。一般输入数据是在文件或目录的形式,并且被存储在Hadoop的文件系统(HDFS)。输入文件被传递到由线映射器功能线路。映射器处理该数据,并创建数据的若干小块。
减少阶段:这个阶段是:Shuffle阶段和Reduce阶段的组合。减速器的工作是处理该来自映射器中的数据。处理之后,它产生一组新的输出,这将被存储在HDFS。
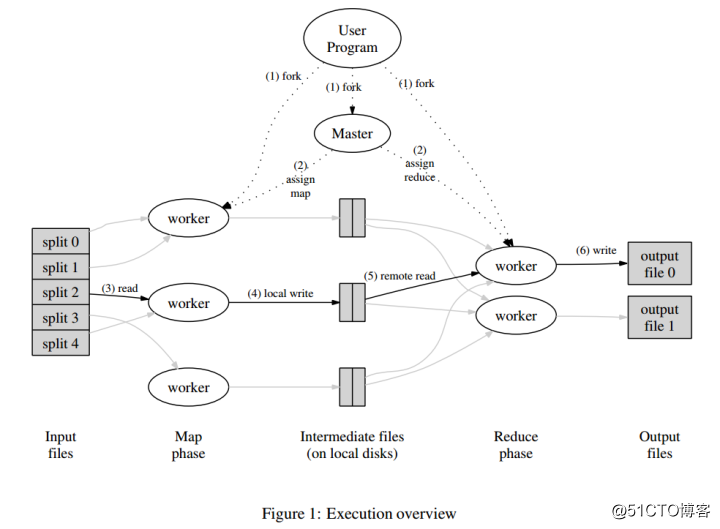
(图四)MapReduce
2.3 HIVE
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行,这套SQL 简称HQL。使不熟悉mapreduce 的用户很方便的利用SQL 语言查询,汇总,分析数据。而mapreduce开发人员可以把己写的mapper 和reducer 作为插件来支持Hive 做更复杂的数据分析。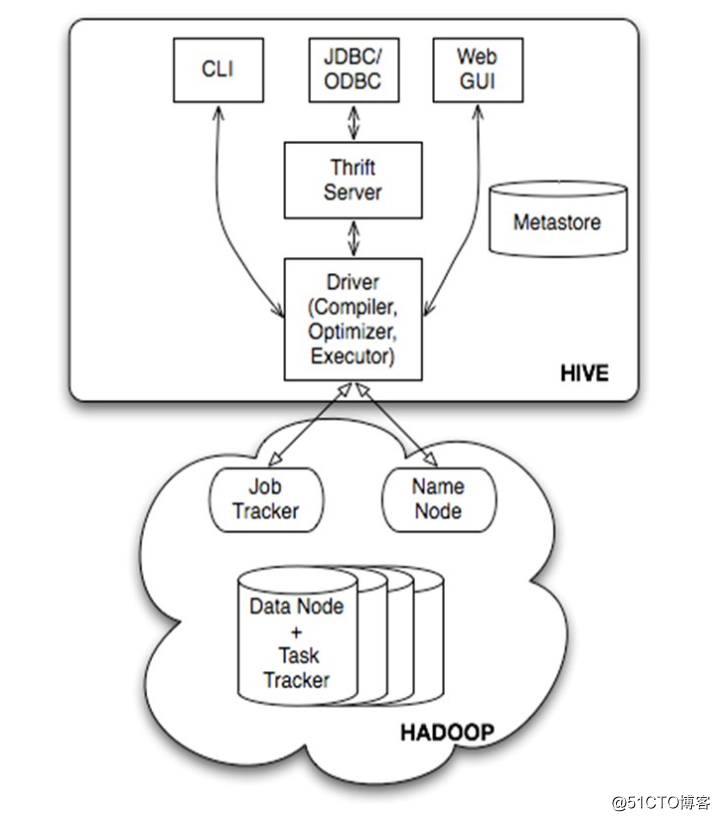
(图五)HIVE体系架构图
由上图可知,hadoop和mapreduce是hive架构的根基。Hive架构包括如下组件:CLI(command line interface)、JDBC/ODBC、Thrift Server、WEB GUI、metastore和Driver(Complier、Optimizer和Executor)。
三、Hadoop走过来的那些坑
进行HIVE操作的时候,HQL写的不当,容易造成数据倾斜,大致分为这么几类:空值数据倾斜、不同数据类型关联产生数据倾斜和Join的数据偏斜。只有理解了Hadoop的原理,熟练使用HQL,就会避免数据倾斜,提高查询效率。
欢迎工作一到五年的Java工程师朋友们加入Java架构开发: 855835163
群内提供免费的Java架构学习资料(里面有高可用、高并发、高性能及分布式、Jvm性能调优、Spring源码,MyBatis,Netty,Redis,Kafka,Mysql,Zookeeper,Tomcat,Docker,Dubbo,Nginx等多个知识点的架构资料)合理利用自己每一分每一秒的时间来学习提升自己,不要再用"没有时间“来掩饰自己思想上的懒惰!趁年轻,使劲拼,给未来的自己一个交代!
标签:apach 之一 数据库 计算机 optimize mysql java oss 离线
原文地址:http://blog.51cto.com/14028890/2337131