标签:节点 ado http classpath src case lod oiv order
查看函数的介绍(必读):show functions ; #查看hive中的所有内置函数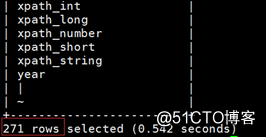
desc function extended 函数名; #查看某个函数的详细介绍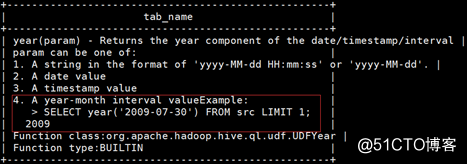
创建数组
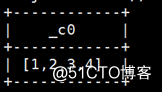
array(ele1,ele2,ele3)
例:select array(1,2,3,4);
判断值是否在数组中
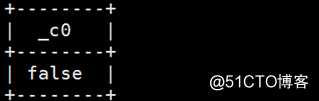
array_contains(arr,value)
例:select array_contains(array(1,2,3,4),5);
创建一个map(基数为key,偶数为value)
map(key0,value0,key1,value1…)
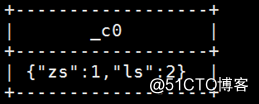
例:select map(‘zs‘,1,‘ls‘,2)
返回map中所有的key
map_keys(map)
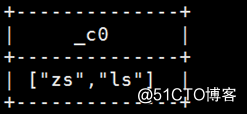
例:select map_keys(map(‘zs‘,1,‘ls‘,2)
返回map中所有的value
map_values(map)
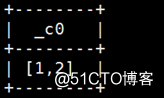
例:select map_values(map(‘zs‘,1,‘ls‘,2)
小数四舍五入:
round(x,[d]) 参数1:浮点数,参数二:保留的位数
例:select round(4.5,1) 返回5
例:select round(5.1) 返回5 默认保留整数位
向上取整:
celi(num)
例:ceil(5.1) #6
向下取整:
floor(num)
例:floor(5.1) #6
substr(str,pos,len) #截取字符串(下标从1开始)
例:select substr(‘abcd’,1) abcd
例:select substr(‘abcd’,1,1) a
ps:substr和substring用法相同
instr(str,substr) #返回子串开始的位置
例:instr(‘abcd’,’cd’) 3
例:instr(‘abcd’ ,’zy’) 0 #没有的默认返回0
split(str,regex) #字符串切分,返回一个数组
例:select split(‘hello world’,’ ’)
concat(str1,str2…) #字符串拼接
例:concat(‘ab’,’cd’,’ef’) ‘abcdef’
concat_ws(separarot,[string|array<string>]) #字符串拼接
例:select concat_ws(‘,’,’ab’,’cd’,’ef’) #’ab,cd,ef’
例:select concat_ws(‘,‘,‘a‘,array(‘b‘,‘c‘)); ‘a,b,c’
大小写转化
lcase /lower #字符串转化为小写
ucase /upper #字符串转化为大写
nvl #字符串判断
例:select nvl(value,‘delfaut‘) #如果前者为null,返回后者
if
语法:if(表达式,返回值1,,返回值2)
例: if(value is null ,‘default‘,value) ,表达式为true,返回返回值1,否则返回返回值2
unix_timestamp(data,format) #返回指定日期的时间戳
例:
例:select unix_timestamp(‘2018-9-1‘,‘yyyy-MM-dd‘); #返回给定日期的时间戳
from_unixtime(timestamp,format) #返回相应时间戳的时间
例:from_unixtime(1151561,’yyyy-MM-dd’)
year(data) #返回给定日期的年
例: year(‘2018-5-4‘) #返回2018
相应的函数还有:month、day、hour、minute、second
weekofyear(data) #返回相应日期,是一年中的第几周
例:select weekofyear(‘2018-5-5‘) ;
datediff(date1,date2) #两个日期相差的天数
例:select datediff(‘2018-5-9‘,‘2018-5-10‘);
语法:explode(a) a可以是一个array,或者map,将数组或者map炸裂为多行
例:select explode(array(1,2,3));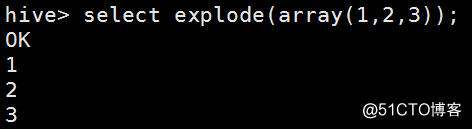
例:select explode(map(‘zs‘,1,‘ls‘,2));
实际应用:
#建表语句
create table user_info(name string,info map<string,string>) row format delimited fields terminated by ‘\t’ collection items terminated by ‘,’ map keys terminated by ‘:’#数据格式:zs age:28,salary:20000,address:beijing
#生成数据:
zs age:28
zs salary:20000
zs address:Beijing#使用表生成函数解决:
select name,t.* from user_info lateral view explode(info) t;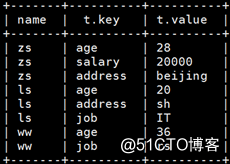
在hive中函数的分类:
这里我们自定义UDF,一路经一路出。
第一步:自定义Java类(导入hive依赖,编写类继承UDF)
注意:方法的名称一定要是evaluate!!!!
package com.zy.mr.hive;
import org.apache.hadoop.hive.ql.exec.UDF;
public class MyUDF extends UDF{
/**
* 参数:参数就是调用函数传入的参数
* 返回值就是,调用的函数的返回值
*
*
* 注意:
* 1.方法的修饰符必须为public
* 2.返回值不能为void
* 3.一般的参数也不能
*/
//三个数求和
public int evaluate(int num1,int num2,int num3) {
return num1+num2+num3;
}
//ip位数补齐 192.166.1.1 -----192.168.001.001
public String evaluate(String ip) {
String[] split = ip.split("\\.");
for(int i=0;i<split.length;i++) {
split[i]="000"+split[i];
split[i]=split[i].substring(split[i].length()-3);
}
return split[0]+"."+split[1]+"."+split[2]+"."+split[3];
}
}第二步:打jar包,上传到Linux
第三步:将jar包放入hive的classpath下:add jar ../xx..jar
第四步:验证是否添加成功:list jars;
第五步:创建临时函数,关联自定义函数:create temporary function func_my as ‘类的权限定名称‘
第六步:验证是否关联成功:show functions; 此时hive的内置函数库中会多一个函数
第七步:使用自定义函数
分析函数的介绍: 分析函数有三种:row_number(),rank(),dense_rank() 三种函数需要与聚合函数共同使用。也可以与over()一起使用。
语法:
row_number() over(partition by /distribute by order by /sort by )
rank () over(partition by /distribute by order by /sort by )
dense_rank() over(partition by /distribute by order by /sort by )
三种函数的区别:
实际应用:
数据:
95002 刘晨 女 19 IS
95017 王风娟 女 18 IS
95018 王一 女 19 IS
95013 冯伟 男 21 CS
95014 王小丽 女 19 CS
95019 邢小丽 女 19 IS
95020 赵钱 男 21 IS
95003 王敏 女 22 MA
95004 张立 男 19 IS
95012 孙花 女 20 CS
95010 孔小涛 男 19 CS
95005 刘刚 男 18 MA
95006 孙庆 男 23 CS
95007 易思玲 女 19 MA
95008 李娜 女 18 CS
95021 周二 男 17 MA
95022 郑明 男 20 MA
95001 李勇 男 20 CS
95011 包小柏 男 18 MA
95009 梦圆圆 女 18 MA
95015 王君 男 18 MA
需求:列出每个部门中年龄最小的三个
解决:
#step1:
create table stu_step1 as select * ,row_number over(partition by department order by age desc ) as top from student_manager ;
# step2:
selecet * from stu_step1 where top <=3 ;以一个案例为准:
数据:
[‘{"movie":"1193","rate":"5","timeStamp":"978300760","uid":"1"}‘,‘{"movie":"661","rate":"3","timeStamp":"978302109","uid":"1"}‘ ,‘{"movie":"914","rate":"3","timeStamp":"978301968","uid":"1"}‘ ,‘{"movie":"3408","rate":"4","timeStamp":"978300275","uid":"1"}‘ ,‘{"movie":"2355","rate":"5","timeStamp":"978824291","uid":"1"}‘ ,‘{"movie":"1197","rate":"3","timeStamp":"978302268","uid":"1"}‘ ,‘{"movie":"1287","rate":"5","timeStamp":"978302039","uid":"1"}‘ ,‘{"movie":"2804","rate":"5","timeStamp":"978300719","uid":"1"}‘ ,‘{"movie":"594","rate":"4","timeStamp":"978302268","uid":"1"}‘]
使用的函数:get_json_object(json,path) ,json是一个json字符串
path是解析的路径。
例:select get_json_object(‘{"movie":"914","rate":"3","timeStamp":"978301968","uid":"1"}‘,$.movie)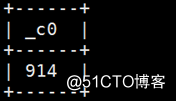
解释:在这个函数的path中
$:表示根目录 {}
.:表示子节点 moive rate timestamp
[]:表示数组的元素
*:表示数组中的所有
例:以上面的数据为例:
select get_json_object(json,$[*].movie) 取上面数据的所有的json中的movie的值。
Transform是一个hive的脚本解析方式(shell和python 脚本)
需求:统计周一到周日哪一天的观影人数最多?
数据:
{"movie":"1193","rate":"5","timeStamp":"978300760","uid":"1"} {"movie":"661","rate":"3","timeStamp":"978302109","uid":"1"} {"movie":"914","rate":"3","timeStamp":"978301968","uid":"1"} {"movie":"3408","rate":"4","timeStamp":"978300275","uid":"1"} {"movie":"2355","rate":"5","timeStamp":"978824291","uid":"1"} {"movie":"1197","rate":"3","timeStamp":"978302268","uid":"1"} {"movie":"1287","rate":"5","timeStamp":"978302039","uid":"1"} {"movie":"2804","rate":"5","timeStamp":"978300719","uid":"1"} {"movie":"594","rate":"4","timeStamp":"978302268","uid":"1"}
第一步 : 建表:
#建表:
create table movie_01(line string);
#加载数据
load data local inpath ‘/home/hadoop/movie‘ into table movie_01;
#Json解析原始表
create table movie_02 as
select
get_json_object(line,‘$.movie‘) as moive_id ,
get_json_object(line,‘$.rate‘) as rate ,
get_json_object(line,‘$.timeStamp‘) as `timeStamp`,
get_json_object(line,‘$.uid‘) as userid
from movie_01; 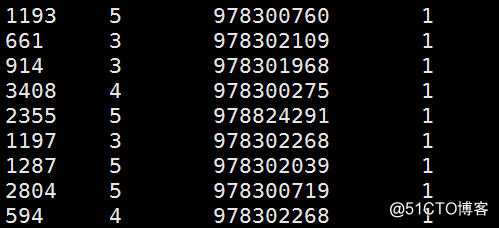
第二步 : 编写Python脚本:
#!/usr/bin/python
import sys
import datetime
for line in sys.stdin:
line = line.strip()
movie,rate,unixtime,userid = line.split(‘\t‘)
weekday = datetime.datetime.fromtimestamp(float(unixtime)).isoweekday()
print ‘\t‘.join([movie, rate, str(weekday),userid])第三步 : 在hive中调用脚本解析数据
将脚本文件加载到hive的classpath下:add file /home/hadoop/datas/my.py;
检验:list files;/ list file;
第四步 : 查询解析
##
select transform(moive_id,rate,timestamp,userid) using ‘python my.py‘ as (movieid,rate,week_day,userid) from movie_02;
#transform:向脚本中传入的参数
#using:调用脚本(shell 是 sh xxx.sh)
# as后面是别名标签:节点 ado http classpath src case lod oiv order
原文地址:http://blog.51cto.com/14048416/2342535