标签:特点 复杂 技术 hash 介绍 服务 过滤器 部分 hdf
1. hbase的简介:??HBASE是bigTable,(源代码是Java编写)的开源版本,是Apache Hadoop的数据库,是建立在hdfs之上,被设计用来提供高可靠性,高性能、列存储、可伸缩、多版本,的Nosql的分布式数据存储系统,实现对大型数据的实时,随机的读写请求。更是弥补了hive不能低延迟、以及行级别的增删改的缺点。
?? HBASE依赖于hdfs做底层的数据存储
?? HBASE依赖于MapReduce做数据计算
?? HBASE依赖于zookeeper做服务协调
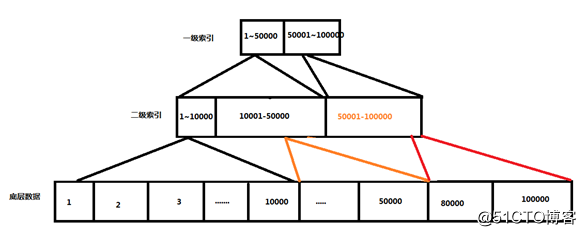
?- 面向列,可以实现一个近实时的查询的一个分布式的数据库。
?- 索引,hbase的rowkey都是按照字典排序的
?- 查询,查询机制是通过索引+布隆过滤器实现
?- 它介于nosql和RDBMS之间,仅能通过主键和主键的range(范围)来检索数据。
?- hbase查询数据功能很简单,依然是以key-value数据库,不支持join等复杂操作
?- 不支持复杂的事务,只支持行级事务(可通过 hive 支持来实现多表 join 等复杂操作)
?- 主要用来存储结构化和半结构化的松散数据。
?- 无模式,每行都有一个可排序的主键和多个任意的列,列可以根据需要动态的增加,同一张表中不同的行可以有截然不同的列。
?- 大,一个表可以是10亿行,上百万列
?- 面向列,面向列(族)的存储和权限控制,列(簇)独立检索。(提升查询的性能)
?- 稀疏,对于空(null)的列,并不占用空间,因此,表可以设计非常稀疏
?- 无严格模式,每行都有一个可排序的主键和任意多的列,列可以根据需要动态的增加,同一张表中不同的行可以有截然不同的列。(读写的时候,都会做格式校验)
??hbase以表结构的形式存储数据。表由行和列组成,列划分为若干个列簇。
??查询数据的流程:
?????????表---rowkey---列簇----列---时间戳
??Rowkey:按照字典排序
??列簇:包含一组列,列在插入数据时指定,列簇在建表的时候指定
??列:一个列簇中会有多个列,并且可以不同
??时间戳:每一个列的值可以存储多个版本的值,版本号就是时间戳,按照时间由近到远排序。
特点:
??- RDBMS完全可以抽象成为一张二维表,表由行和列组成,有行和列确定一个唯一的值
??- HBASE本质是key-value数据库,key是行键rowkey,value是所有的真实key-value的集合
??- HBASE也可以抽象成为一个四维表,四维分别由行健 RowKey,列簇 Column Family,列 Column 和时间戳 Timestamp 组成。
??- 一张HBASE的所有列划分为若干个列簇
??- 每一个region的每一个列簇又是一个store,在hdfs的表现就是一个文件夹。
行键(rowkey):
??与Nosql数据库一样,rowkey是用于检索记录的主键,rowkey 行键可以是任意字符串(最大长度是 64KB,实际应用中长度一般为 10-100bytes),最好是16。在 HBase 内部,rowkey 保存为字节数组,HBase 会对表中的数据按照 rowkey 排序 (字典顺序)
??访问HBASE table中的行。只有三种方式:
???- 通过单个rowkey访问
???- 通过rowkey的range(范围)
???- 全表扫描
列簇:
??HBASE表中的每一个列,都归属于某个列簇。列簇是表的Schema 的一部分(而列不是),必须 在使用表之前定义好,而且定义好了之后就不能更改。列名都是以列簇为前缀,访问控制、磁盘和内存的使用统计等都是在列簇层面进行的。
??注意:列簇越多,在取一行数据时所要参与 IO、搜寻的文件就越多,所以,如果没有必要,不要 设置太多的列簇(最好就一个列簇)。
时间戳:
??在HBASE中通过rowkey 和 columns 确定的为一个存储单元称为 cell。每一个cell都保存着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是 64 位整型。时间戳可以由 hbase(在数据写入时自动)赋值,此时时间戳是精确到毫秒的当前系统时间。每个 cell 中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
??为了避免数据存在过多版本造成的管理负担,HBASE提供了两种数据版本的回收方式:
???- 保存数据的最后n个版本(个数)
???-保存最近一段是时间内的版本(设置数据的生命周期 TTL)
单元格:
??在HBASE中通过rowkey 和 columns 确定的为一个存储单元称为 cell。由{rowkey,column(=<family>+< column>),version}组成一个cellCell中的数据是没有类型的,全是字节码形式存储。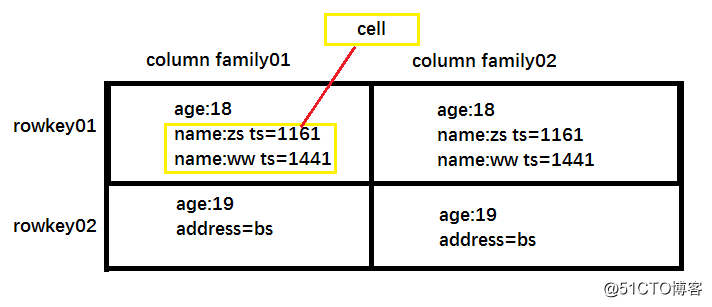
相同点:
??- HBASE和hive都是架构在hadoop之上,用hdfs做底层的数据存储。用MapReduce做数据计算。
不同点:
??- hive是建立在hadoop之上的,为了减低Mapreduce编程的复杂度,而hbase是为了弥补hadoop对实时操作的缺陷
??- Hive的表示纯逻辑表,因为hive本身并不能做数据存储和计算,而是完全依赖于hadoop,hbaseHBASE是物理表,提供了一张超大的内存 Hash 表来存储索引,方便查询。
??- Hive是数据仓库,需要全表扫描,就用hive,hive是文件存储,HBase 是数据库,需要索引访问,则用 HBase,因为 HBase 是面向列的 NoSQL 数据库
??- Hive 不支持单行记录操作,数据处理依靠 MapReduce,操作延时高;HBase 支持单行记录的 CRUD,并且是实时处理,效率比 Hive 高得多
标签:特点 复杂 技术 hash 介绍 服务 过滤器 部分 hdf
原文地址:http://blog.51cto.com/14048416/2342799