标签:网页 说明 hello 规模 存在 nbsp 传统 空间 根据
概述
监督学习指的是训练样本包含标记信息的学习任务,例如:常见的分类与回归算法;
无监督学习则是训练样本不包含标记信息的学习任务,例如:聚类算法。
在实际生活中,常常会出现一部分样本有标记和较多样本无标记的情形,例如:做网页推荐时需要让用户标记出感兴趣的网页,但是少有用户愿意花时间来提供标记。若直接丢弃掉无标记样本集,使用传统的监督学习方法,常常会由于训练样本的不充足,使得其刻画总体分布的能力减弱,从而影响了学习器泛化性能。那如何利用未标记的样本数据呢?
以下参考博客:https://blog.csdn.net/u011826404/article/details/74358913
未标记样本
1.基本假设(原文:https://blog.csdn.net/hellowuxia/article/details/66473252 )
要利用未标记样本,必然要做一些将未标记样本所揭示的数据分布信息与类别标记相联系的假设。
1)平滑假设(Smoothness Assumption):位于稠密数据区域的两个距离很近的样例的类标签相似,也就是说,当两个样例被稠密数据区域中的边连接时,它们在很大的概率下有相同的类标签;相反地,当两个样例被稀疏数据区域分开时,它们的类标签趋于不同。
2)聚类假设(Cluster Assumption):当两个样例位于同一聚类簇时,它们在很大的概率下有相同的类标签。这个假设的等价定义为低密度分离假设(Low Sensity Separation Assumption),即分类决策边界应该穿过稀疏数据区域,而避免将稠密数据区域的样例分到决策边界两侧。
聚类假设是指样本数据间的距离相互比较近时,则他们拥有相同的类别。根据该假设,分类边界就必须尽可能地通过数据较为稀疏的地方,以能够避免把密集的样本数据点分到分类边界的两侧。
例如,Joachims提出的转导支持向量机算法(TSVM),在训练过程中,算法不断修改分类超平面并交换超平面两侧某些未标记的样本数据的标记,使得分类边界在所有训练数据上最大化间隔,从而能够获得一个通过数据相对稀疏的区域,又尽可能正确划分所有有标记的样本数据的分类超平面。
3)流形假设(Manifold Assumption):将高维数据嵌入到低维流形中,当两个样例位于低维流形中的一个小局部邻域内时,它们具有相似的类标签。
流行假设,假设数据分布在一个流行结构上,临近的样本拥有相似的输出值,临近通常用相似度来刻画。流行假设可以看作聚类假设的推广。
流形假设的主要思想:同一个局部邻域内的样本数据具有相似的性质,因此其标记也应该是相似。这一假设体现了决策函数的局部平滑性。
和聚类假设的主要不同是,
1)聚类假设主要关注的是整体特性,流形假设主要考虑的是模型的局部特性。在该假设下,未标记的样本数据就能够让数据空间变得更加密集,从而有利于更加标准地分析局部区域的特征,也使得决策函数能够比较完满地进行数据拟合。流形假设有时候也可以直接应用于半监督学习算法中。
例如,Zhu 等人利用高斯随机场和谐波函数进行半监督学习,首先利用训练样本数据建立一个图,图中每个结点就是代表一个样本,然后根据流形假设定义的决策函数的求得最优值,获得未标记样本数据的最优标记;Zhou 等人利用样本数据间的相似性建立图,然后让样本数据的标记信息不断通过图中的边的邻近样本传播,直到图模型达到全局稳定状态为止。
2)流型假设对输出值没有限制,因此比聚类假设适用范围更广,可用于更多类型的学习任务。
从本质上说,这三类假设是一致的,“相似的样本拥有相似的输出”,只是相互关注的重点不同。其中流行假设更具有普遍性。
2.半监督学习细化
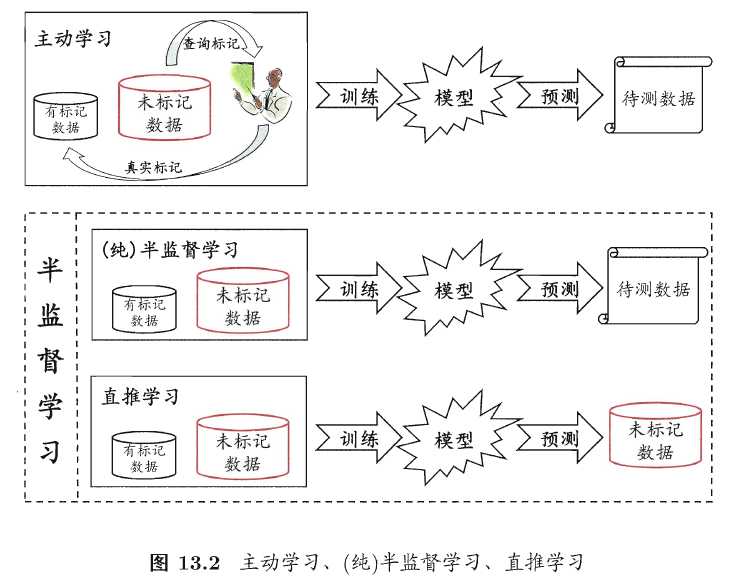
主动学习:若我们先使用有标记的样本数据集训练出一个学习器,再基于该学习器对未标记的样本进行预测,从中挑选出不确定性高或分类置信度低的样本来咨询专家并进行打标,最后使用扩充后的训练集重新训练学习器,这样便能大幅度降低标记成本,这便是主动学习(active learning),其目标是使用尽量少的/有价值的咨询来获得更好的性能。
半监督学习可进一步划分为纯半监督学习和直推学习,前者假定训练数据中未标记样本并非待预测数据,后者假设学习过程中所考虑未标记样本恰是待预测数据 ,学习目的是在这些未标记样本上获得最有泛化性能。纯半监督学习基于“开放世界”,希望学得模型能适用于训练过程中未观测到的数据;直推学习基于“封闭世界”假设,仅试图对学习过程中观察到的未标记数据进行预测。
显然,主动学习需要与外界进行交互/查询/打标,其本质上仍然属于一种监督学习。事实上,无标记样本虽未包含标记信息,但它们与有标记样本一样都是从总体中独立同分布采样得到,因此它们所包含的数据分布信息对学习器的训练大有裨益。如何让学习过程不依赖外界的咨询交互,自动利用未标记样本所包含的分布信息的方法便是半监督学习(semi-supervised learning),即训练集同时包含有标记样本数据和未标记样本数据。
生成式方法
1、说明
生成式方法(generative methods)是基于生成式模型的方法,即先对联合分布P(x,c)建模,从而进一步求解 P(c | x),此类方法假定样本数据服从一个潜在的分布,因此需要充分可靠的先验知识。例如:前面已经接触到的贝叶斯分类器与高斯混合聚类,都属于生成式模型。现假定总体是一个高斯混合分布,即由多个高斯分布组合形成,从而一个子高斯分布就代表一个类簇(类别)。
2、以高斯混合模型为例


求解方法参考EM算法。
3、总结
可以看出:基于生成式模型的方法十分依赖于对潜在数据分布的假设,即假设的分布要能和真实分布相吻合,否则利用未标记的样本数据反倒会在错误的道路上渐行渐远,从而降低学习器的泛化性能。因此,此类方法要求极强的领域知识和掐指观天的本领。
半监督SVM
监督学习中的SVM试图找到一个划分超平面,使得两侧支持向量之间的间隔最大,即“最大划分间隔”思想。对于半监督学习,半监督SVM(S3VM)则考虑超平面需穿过数据低密度的区域。
TSVM是半监督支持向量机中的最著名代表,其核心思想是:尝试为未标记样本找到合适的标记指派,使得超平面划分后的间隔最大化。
TSVM采用局部搜索的策略来进行迭代求解,即首先使用有标记样本集训练出一个初始SVM,接着使用该学习器对未标记样本进行打标,这样所有样本都有了标记,并基于这些有标记的样本重新训练SVM,之后再寻找易出错样本不断调整。整个算法流程如下所示:
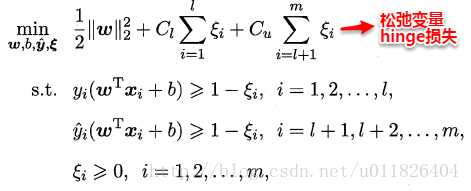

图半监督学习
给定一个数据集,我们可将其映射为一个图,数据集中每个样本对应于图中一个结点,若两个样本之间的相似度很高(或相关性很强),则对应的结点之间存在一条边,边的“强度”正比于样本之间的相似度(或相关性).我们可将有标记样本所对应的结点想象为染过色,而未标记样本所对应的结点尚未染色.于是,半监督学习就对应于“颜色”在图上扩散或传播的过程.由于一个图对应了一个矩阵,这就使得我们能基于矩阵运算来进行半监督学习算法的推导与分析.换句话说,就是用矩阵运算对未标记样本打上伪标签。
1、对于二分类:

其中W和D的定义如下:


推导见西瓜书。。。
2、对于多分类:


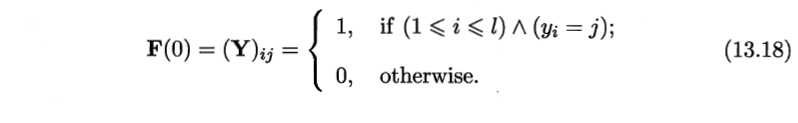
图半监督学习方法在概念上相当清晰,且易于通过对所涉矩阵运算的分析来探索算法性质.但此类算法的缺陷也相当明显.首先是在存储开销上,若样本数为O(m),则算法中所涉及的矩阵规模为O(m2),这使得此类算法很难直接处理大规模数据;另一方面,由于构图过程仅能考虑训练样本集,难以判知新样
本在图中的位置,因此,在接收到新样本时,或是将其加入原数据集对图进行重构并重新进行标记传播,或是需引入额外的预测机制,例如将DL和经标记传播后得到标记的D}合并作为训练集,另外训练一个学习器例如支持向量机来对新样本进行预测.
基于分歧的方法
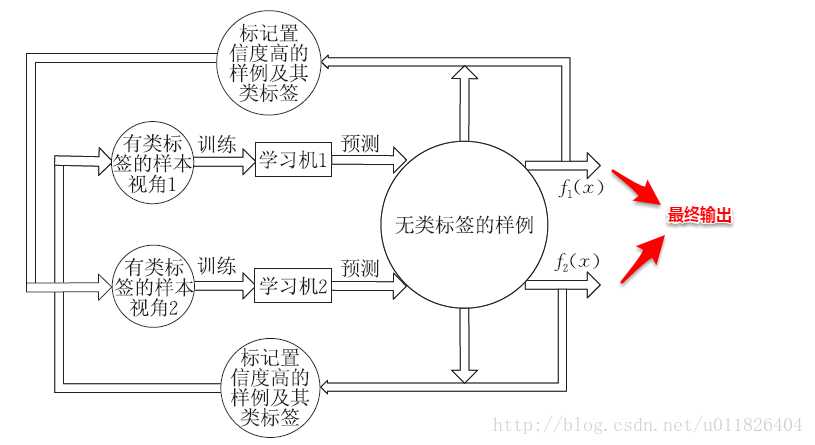
基于分歧的方法通过多个学习器之间的分歧(disagreement)/多样性(diversity)来利用未标记样本数据,协同训练就是其中的一种经典方法。协同训练最初是针对于多视图(multi-view)数据而设计的,多视图数据指的是样本对象具有多个属性集,每个属性集则对应一个视图。例如:电影数据中就包含画面类属性和声音类属性,这样画面类属性的集合就对应着一个视图。
首先引入两个关于视图的重要性质:
相容性:即使用单个视图数据训练出的学习器的输出空间是一致的。例如都是{好,坏}、{+1,-1}等。
互补性:即不同视图所提供的信息是互补/相辅相成的,实质上这里体现的就是集成学习的思想。
协同训练正是很好地利用了多视图数据的“相容互补性”,其基本的思想是:首先基于有标记样本数据在每个视图上都训练一个初始分类器,然后让每个分类器去挑选分类置信度最高的样本并赋予标记,并将带有伪标记的样本数据传给另一个分类器去学习,从而你依我侬/共同进步。


半监督聚类
半监督聚类则是借助已有的监督信息来辅助聚类的过程。一般而言,监督信息大致有两种类型:
必连与勿连约束:必连指的是两个样本必须在同一个类簇,勿连则是必不在同一个类簇。
标记信息:少量的样本带有真实的标记。
下面主要介绍两种基于半监督的K-Means聚类算法:第一种是数据集包含一些必连与勿连关系,另外一种则是包含少量带有标记的样本。两种算法的基本思想都十分的简单:对于带有约束关系的k-均值算法,在迭代过程中对每个样本划分类簇时,需要检测当前划分是否满足约束关系,若不满足则会将该样本划分到距离次小对应的类簇中,再继续检测是否满足约束关系,直到完成所有样本的划分。算法流程如下图所示:

对于带有少量标记样本的k-均值算法,则可以利用这些有标记样本进行类中心的指定,同时在对样本进行划分时,不需要改变这些有标记样本的簇隶属关系,直接将其划分到对应类簇即可。算法流程如下所示:

标签:网页 说明 hello 规模 存在 nbsp 传统 空间 根据
原文地址:https://www.cnblogs.com/CJT-blog/p/10276310.html