标签:inf 属性 图片 正态分布 code import and one null

## 拉格朗日插值代码(使用缺失值前后各5个未缺失的数据建模)
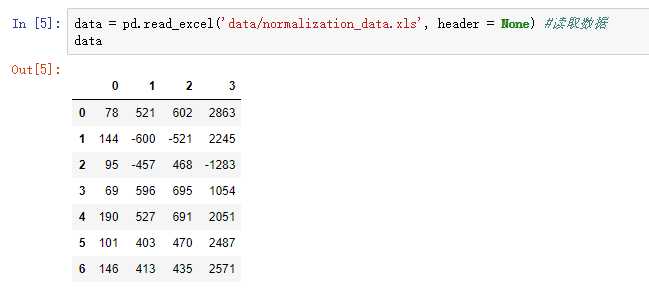
import pandas as pd #导入数据分析库Pandas from scipy.interpolate import lagrange #导入拉格朗日插值函数 inputfile = ‘../data/catering_sale.xls‘ #销量数据路径 outputfile = ‘../tmp/sales.xls‘ #输出数据路径 data = pd.read_excel(inputfile) #读入数据 data[u‘销量‘][(data[u‘销量‘] < 400) | (data[u‘销量‘] > 5000)] = None #过滤异常值,将其变为空值 #自定义列向量插值函数 #s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5 def ployinterp_column(s, n, k=5): y = s[list(range(n-k, n)) + list(range(n+1, n+1+k))] #取数 y = y[y.notnull()] #剔除空值 return lagrange(y.index, list(y))(n) #插值并返回插值结果 #逐个元素判断是否需要插值 for i in data.columns: for j in range(len(data)): if (data[i].isnull())[j]: #如果为空即插值。 data[i][j] = ployinterp_column(data[i], j) data.to_excel(outputfile) #输出结果,写入文件

1)函数变换:将不具有正态分布的数据变换成正态分布的数据
2)规范化/归一化:消除不同量纲的影响
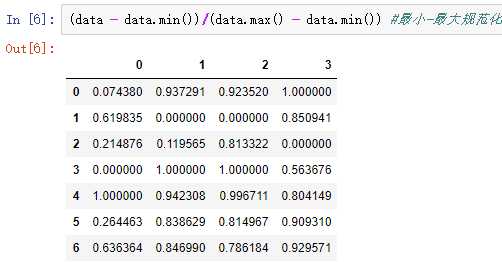
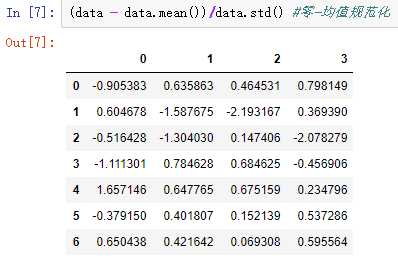
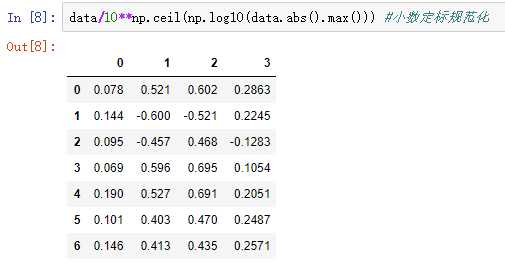
零-均值规范化使用最多
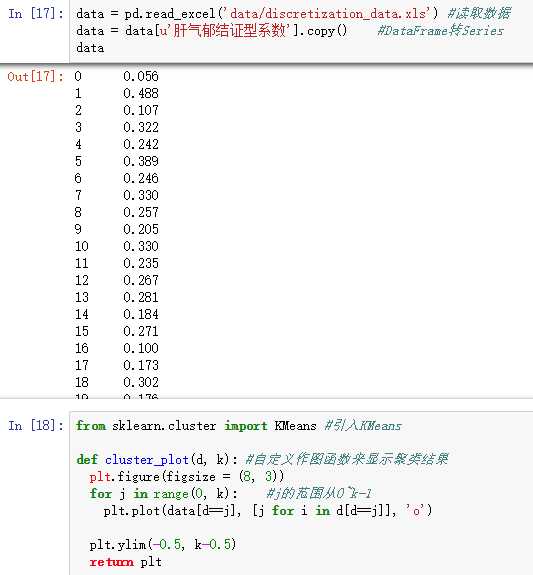
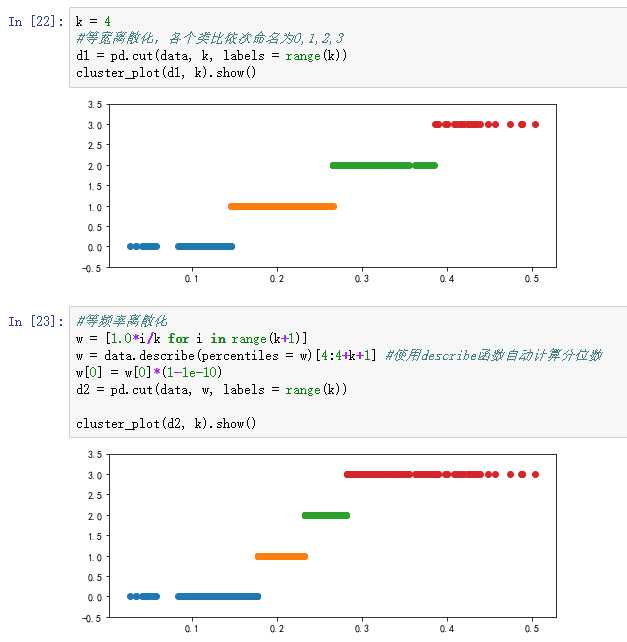
3)连续属性离散化:连续属性->分类属性
以“医学中中医证型的相关数据”为例
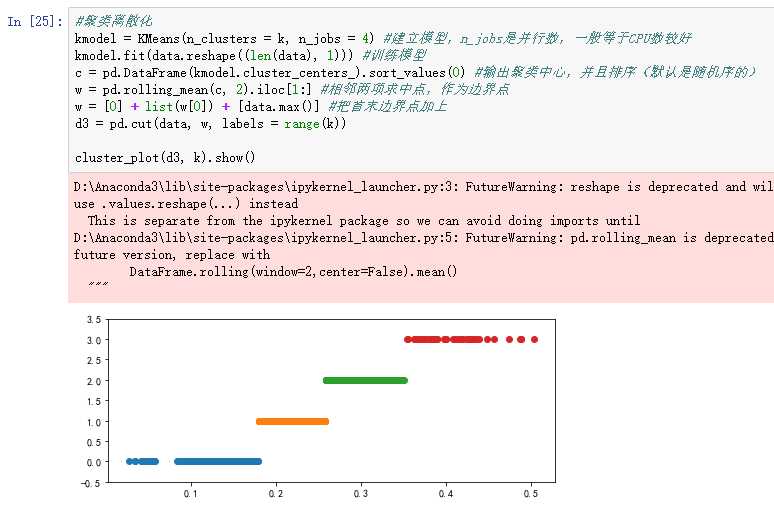
4)属性构造:利用已有属性构造新的属性
以线损率为例
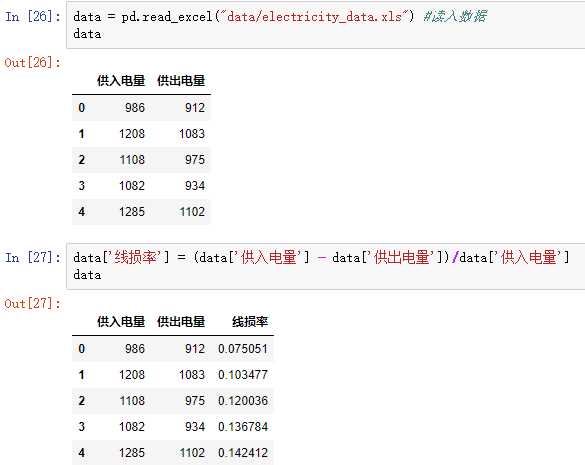
1)属性规约(纵向):属性合并、删除无关属性
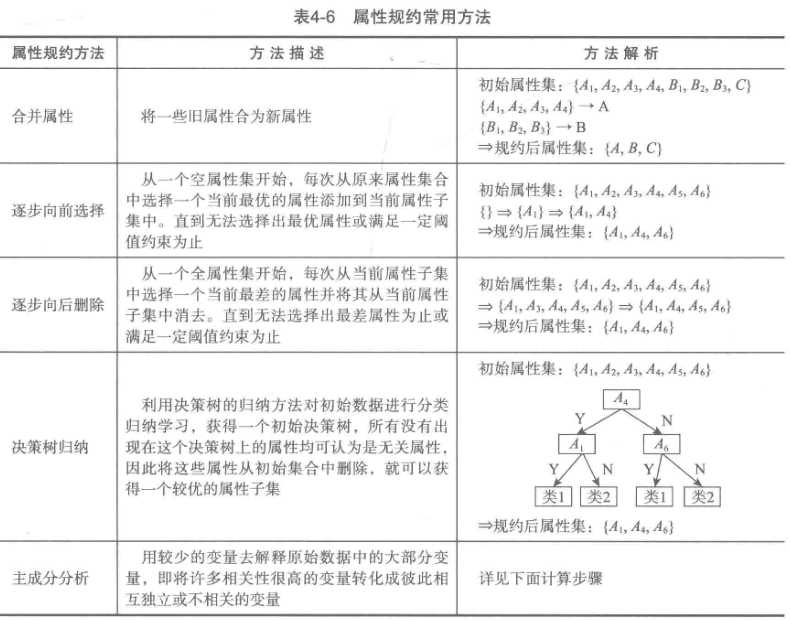
2)数值规约(横向):选择替代的、娇小的数据来减少数据量,包括有参方法和无参方法
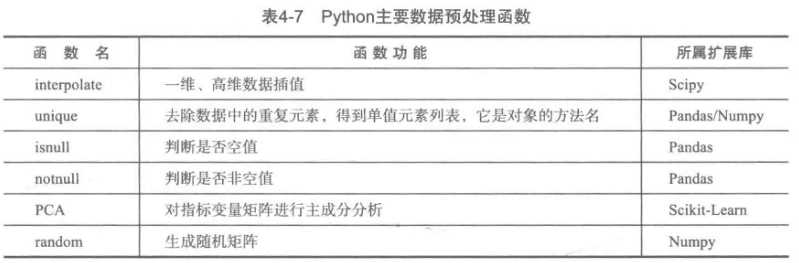
标签:inf 属性 图片 正态分布 code import and one null
原文地址:https://www.cnblogs.com/little-monkey/p/10047032.html