标签:简单工厂 strong 低耦合 role 效率 缓冲区溢出 数据同步 http请求 tmp
项目
比如项目里面的,你主要负责什么?你们实现了什么?里面用到的xxxx你觉得怎么样,有什么优缺点?项目最大的困难是什么?后面问了用的什么web服务器,数据库,框架和设计模式,然后具体问了观察者模式(这个没答出来)。写项目整体架构,具体功能模块的的实现,用到的技术
- 谈一下做的项目:
基于SSM的商城
- 这个项目是一个小型的购物网站,是我们学习软件工程的一个课程设计。主要是分为前台,后台和数据库
- 前台是用户交互系统。有注册登录界面,首页通过分页显示商品,并且有一个搜索框可以用来搜索商品。用户点击商品,可以对商品进行下单。用户还可以进入秒杀页面对商品进行秒杀。
- 后台管理系统,用以管理员对商品数据、订单数据等进行管理
- 数据库:数据库设计上没有建索引,主键一般是一个业务无关的id,并且是自增的。因为mysql是innoDB做执行引擎的,所以id会是一个聚集索引。由于使用了solr索引,所以数据库设计上没有使用过多索引。另外权限控制上主要是用了两张表,一张是存储用户id和用户信息的,另一张是存储role_id,user_id和role。
- 主要负责:编写前端的下单界面、商品首页界面。部分数据库设计。SSM框架搭建、后端负责秒杀系统redis的缓存和登录权限框架shiro控制权限。
- Solr: Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
- 原理倒排索引:分词,关键字标注所在文章。关键词在文章的位置:记录关键词是文章的第几个关键字。实现高亮显示。
- 利用solr可以实现添加文档,建立关键索引,根据索引查询,高亮显示
- 优点:Solr比较成熟、稳定。
不考虑建索引的同时进行搜索,速度更快。
- 缺点:建立实时索引会导致效率严重下降
- Spring:spring是一个企业级开源项目,通过依赖注入和控制反转
的方式管理对象,而且提供了切面编程。Spring使用了工厂模式和单例模式
- 控制反转:所谓控制反转是指,本来被调用者的实例是有调用者来创建的,这样的缺点是耦合性太强,IOC 则是统一交给 spring 来管理创建,将对象交给容器管理,你只需要在 spring 配置文件总配置相应的bean,以及设置相关的属性,让 spring容器来生成类的实例对象以及管理对象。在spring 容器启动的时候,spring 会把你在配置文件中配置的 bean 都初始化好,然后在你需要调用的时候,就把它已经初始化好的那些 bean 分配给你需要调
用这些 bean 的类。
- IoC 的一个重点是在系统运行中,动态的向某个对象提供它所需要的其他对象。这一点是通过 DI(Dependency Injection,依赖注入)来实现的。比如对象 A 需要操作数据库,以前我们总是
要在 A 中自己编写代码来获得一个 Connection 对象,有了 spring 我们就只需要告诉spring,A 中需
要一个Connection,至于这个 Connection 怎么构造,何时构造,A 不需要知道。在系统运行时,sp
ring 会在适当的时候制造一个 Connection,然后像打针一样,注射到 A 当中,这样就完成了对各个
对象之间关系的控制。A 需要依赖 Connection 才能正常运行,而这个 Connection 是由spring 注入到 A 中的,依赖注入的名字就这么来的。
- 就是将那些与业务无关,却为业务模块所共同调用的逻辑或责任封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可操作性和可维护性。使用“横切”技术,AOP 把软件系统分为两个部分:核心关注点和横切关注点。业务处理的主要流程是核心关
注点,与之关系不大的部分是横切关注点。横切关注点的一个特点是,他们经常发生在核心
关注点的多处,而各处都基本相似。比如权限认证、日志、事务处理。Aop 的作用在于分
离系统中的各种关注点,将核心关注点和横切关注点分离开来。
- 简单工厂:简单工厂模式的实质是由一个工厂类根据传入的参数,动态决定应该创建哪一个产品类。
spring 中的 BeanFactory 就是简单工厂模式的体现,根据传入一个唯一的标识来获得bean 对象,但是否是在传入参数后创建还是传
入参数前创建这个要根据具体情况来定。如下配置
- 单例模式(Singleton)
保证一个类仅有一个实例,并提供一个访问它的全局访问点。
spring 中的单例模式完成了后半句话,即提供了全局的访问点BeanFactory。但没有从构造器级别去控制单例,这是因为 spring 管理
的是是任意的 java 对象。
核心提示点:Spring 下默认的bean 均为 singleton,可以通过 singleton=“true|false” 或者 scope=“?”来指定
- 观察者(Observer)
定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
spring 中 Observer 模式常用的地方是 listener 的实现。如 ApplicationListener。
- springmvc:springmvc是一个基于mvc的web开源框架用来简化web开发的,就是把业务分成model,view和controller,分层之后降低耦合性。方便技术人员的开发。
- 处理流程:
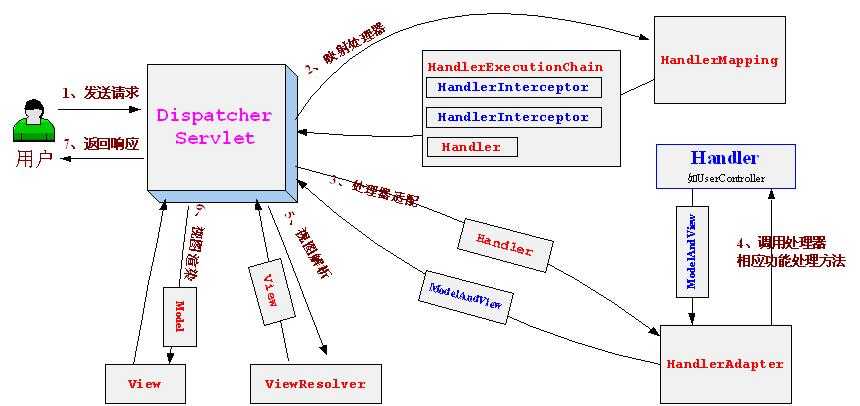
1、DispatcherServlet前端控制器接收发过来的请求,交给HandlerMapping处理器映射器
2、HandlerMapping处理器映射器,根据请求路径找到相应的HandlerAdapter处理器适配器(处理器适配器就是那些拦截器或Controller)
3、HandlerAdapter处理器适配器,处理一些功能请求,返回一个ModelAndView对象(包括模型数据、逻辑视图名)
4、ViewResolver视图解析器,先根据ModelAndView中设置的View解析具体视图
5、然后再将Model模型中的数据渲染到View上
- 优点:依赖注入,控制反转,对象通过spring统一管理。切面编程,简化开发
- 缺点:不支持分布式
- mybatis
- 项目最大困难:在这个项目开始的时候,我们组员都只有一些web基础和java基础。对于很多技术都是第一次接触,所以都是一边学习一边开发,也踩了很多坑。比如开始搭建ssm框架的时候,按照网上教程但是会出错,生成的目录跟博主的不一样,于是我们就只能看视频学习;还有shiro框架学习,跟ssm框架整合的时候也会遇到问题。有一次配置完shiro框架之后,出现了第一次登录失败,但是第二次能登陆的问题。后来发现原来是因为shiro.xml里面配置出错。虽然做项目的时候踩坑不断,但是我们不断坚持,并不断学习,找bug,看别人的源码,看官方文档,看别人的技术博客。所以项目能顺利完成
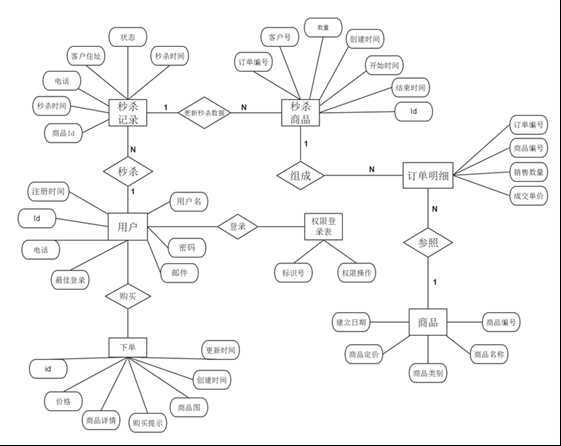
- 项目整体架构
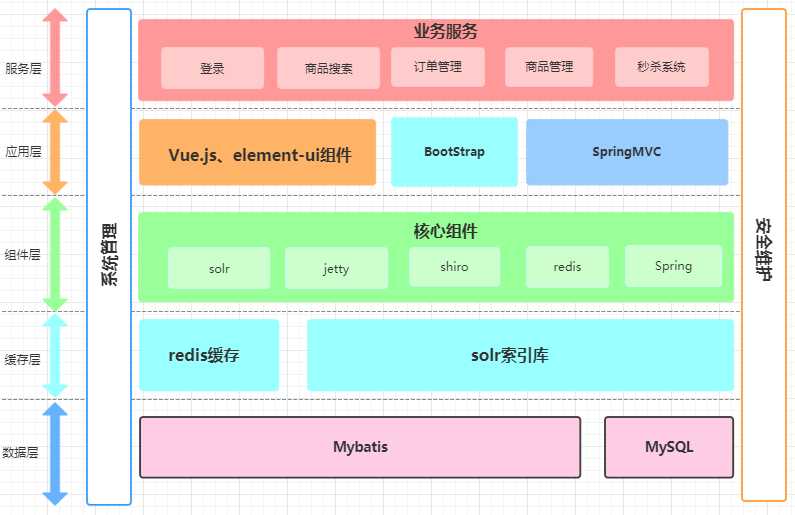
- 具体功能模块的的实现
- MVC设计模式:model,view,controller
多线程:
- Java类加载:
- 类加载过程包括:加载,连接,初始化,使用,卸载
- 加载过程就是将
- 通过类的全限定名定义二进制流
- 将二进制流的数据转化为方法区的运行时数据结构
- 内存中生成类的对象,作为方法区这个类的访问入口
- 连接包括验证,准备,解析
- 验证是对类的符号验证,元数据验证,文件格式验证等
- 准备阶段为类分配内存并且初始化
- 解析将常量池的符号引号转化为直接引用
- 初始化是执行类的初始构造器
- B树和B 树的区别
- B+树的内部节点关键字比子树个数相同,B树内部节点数比子树多一个
- B+树区间遍历更快,因为叶子节点之间用链表相连
- B+树每次查找都会一直找到叶子节点,效率稳定,B树在某个节点查询到之后就可以返回了。
- B+树内部节点只存放索引,所以磁盘可以放的内部节点更多
- 谈谈JAVA面向对象的理解。
- java的面向对象主要是通过封装,继承,多态将程序耦合度降到最低,使得程序更加灵活,易于复用
- JDK容器问题,HashMap的结构、和HashTable的区别,ConcurrentHashMap
- 数组+链表
- Hashtable利用synchronized修饰方法,线程安全的Map
- 1.7以前的concurrentmap主要是利用分段锁保证线程安全的,这样的优点是每次只占用部分锁,能够并发访问
- 其中抛弃了原有的 Segment 分段锁,而采用了 CAS + synchronized 来保证并发
安全性。
- 大于 8 的时候才去红黑树链表转红黑树的阀值,当 table[i]下面的链表长度大于 8
时就转化为红黑树结构
- Spring了解什么,把了解的都说一遍
IOC/DI/AOP
- 虚拟机了解啥,把JMM都说一遍,详细说一下
- GC算法,垃圾回收机制
- YGC
答:说白了就是复制算法,对象只会存在于 Eden 区和名为“From”的
Survivor 区,Survivor 区“To”是空的。紧接着进行 GC,Eden 区中所有存活
的对象都会被复制到“To”,而在“From”区中,仍存活的对象会根据他们的
年龄值来决定去向。年龄达到一定值(年龄阈值,可以通过
-XX:MaxTenuringThreshold 来设置)的对象会被移动到年老代中,没有达到阈值
的对象会被复制到“To”区域。经过这次 GC 后,Eden 区和 From 区已经被清
空。这个时候,“From”和“To”会交换他们的角色,也就是新的“To”就是
上次 GC 前的“From”,新的“From”就是上次 GC 前的“To”。不管怎样,都会保
证名为 To 的 Survivor 区域是空的。Minor GC 会一直重复这样的过程,直到“To”
区被填满,“To”区被填满之后,会将所有对象移动到年老代中。
其中如果发生晋升失败的情况,那么说明老年代的内存空间不够用了,需要
进行一次 FullGC
- FGC
答:FGC 就是标记整理或者是标记清除算法来清除老年代。
- 内存分区
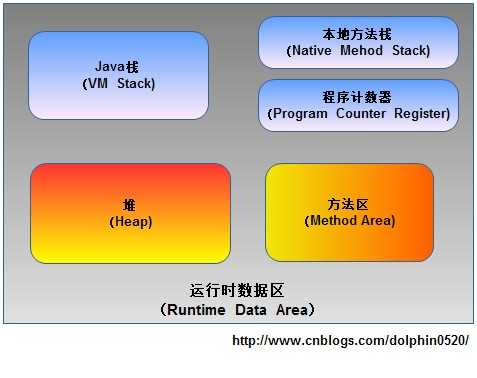
- JMM模型
- JMM 规定了所有的变量都存储在主内存(Main Memory)中。每个线程还有自
己的工作内存(Working Memory)
- JMM 中的 happens-before 原则
happens-before 原则内容如下
- 程序顺序原则,即在一个线程内必须保证语义串行性,也就是说按照代
码顺序执行。
- 锁规则 解锁(unlock)操作必然发生在后续的同一个锁的加锁(lock)之
前,也就是说,如果对于一个锁解锁后,再加锁,那么加锁的动作必须在解锁动
作之后(同一个锁)。
- volatile 规则 volatile 变量的写,先发生于读,这保证了 volatile 变量的
可见性,简单的理解就是,volatile 变量在每次被线程访问时,都强迫从主内存
中读该变量的值,而当该变量发生变化时,又会强迫将最新的值刷新到主内存,
任何时刻,不同的线程总是能够看到该变量的最新值。
- 线程启动规则 线程的 start()方法先于它的每一个动作,即如果线程 A
在执行线程 B 的 start 方法之前修改了共享变量的值,那么当线程 B 执行 start
方法时,线程 A 对共享变量的修改对线程 B 可见
传递性 A 先于 B ,B 先于 C 那么 A 必然先于 C
- 线程终止规则 线程的所有操作先于线程的终结,Thread.join()方法的作
用是等待当前执行的线程终止。假设在线程 B 终止之前,修改了共享变量,线
程 A 从线程 B 的 join 方法成功返回后,线程 B 对共享变量的修改将对线程 A 可
见。
- 线程中断规则 对线程 interrupt()方法的调用先行发生于被中断线程的
代码检测到中断事件的发生,可以通过 Thread.interrupted()方法检测线程是否
中断。
- 对象终结规则 对象的构造函数执行,结束先于 finalize()方法
- TCP/IP 三次握手具体交换哪些信息?
- 1.首先由 Client 发出请求连接即 SYN=1 ACK=0 (请看头字段的介绍), TCP 规定 SYN=1
时不能携带数据,但要消耗一个序号,因此声明自己的序号是 seq=x
- 2.然后 Server 进行回复确认,即 SYN=1 ACK=1 seq=y, ack=x+1,
- 3.再 然 后 Client 再 进 行 一 次 确 认 , 但 不 用 SYN 了 , 这 时 即 为 ACK=1, seq=x+1,
ack=y+1.然后连接建立,为什么要进行三次握手呢(两次确认)。
- 三次握手而不是两次:防止一种异常情况发送,有一个客户端超时报文在服务端已经关闭连接之后到达服务器,如果只是两次握手,那么服务器就会建立起连接,消耗服务器资源。然而三次连接的话服务器会等待客户端响应,客户端收到报文但是不发送确认报文,那么服务器就不会建立连接。
- 排序算法 link
public static void QuickSort(int A[],int begin,int end) {
int i=begin,j=end;
if(i>=j)
return;
int key=A[i];
while(i<j) {
while(i<j&&A[j]>key)
j--;
if(i<j&&A[j]<=key) {
A[i]=A[j];
i++;
}
while(i<j&&A[i]<key)
i++;
if(i<j&&A[i]>=key) {
A[j]=A[i];
j--;
}
}
A[i]=key;
QuickSort(A,begin,i-1);
QuickSort(A,i+1,end);
}
public static void MergSort(int a[],int begin,int end,int[] tmp) {
if(begin<end) {
int mid=(begin+end)/2;
MergSort(a,begin,mid,tmp);
MergSort(a,mid+1,end,tmp);
MergArray(a,begin,mid,mid+1,end,tmp);
}
}
private static void MergArray(int[] a, int Lbegin, int Lend, int Rbegin, int Rend, int[] tmp) {
// TODO Auto-generated method stub
int i=Lbegin,j=Rbegin,k=0;
while(i<=Lend&&j<=Rend) {
if(a[i]<a[j])
tmp[k++]=a[i++];
else
tmp[k++]=a[j++];
}
while(i<=Lend)
tmp[k++]=a[i++];
while(j<=Rend)
tmp[k++]=a[j++];
for(int h=0;h<k;h++)
a[Lbegin+h]=tmp[h];
}
public class HeapSort {
public void heapSort(int []array) {
matHeapAdjust(array);
for(int i=array.length-1;i>0;i--) {
int tmp=array[0];
array[0]=array[i];
array[i]=tmp;
heapAdjust(array,1,i);
}
}
private void heapAdjust(int[] array, int s, int m) {
// TODO Auto-generated method stub
int tmp,i,largest;
tmp=array[s-1];
for(i=2*s;i<=m;i*=2) {
if(i<m&&array[i-1]<array[i]) {
largest=i;
i++;
}else {
largest=i-1;
}
if(tmp>=array[largest])
break;
array[s-1]=array[largest];
s=largest+1;
}
array[s-1]=tmp;
}
private void matHeapAdjust(int[] array) {
// TODO Auto-generated method stub
for(int i=array.length/2;i>0;i--)
heapAdjust(array,i,array.length);
}
}
- 一个是浏览器输入域名后http协议的工作工程
DNS-》HTTP-》TCP->
- 1.客户端浏览器通过 DNS 解析到 www.baidu.com 的 IP 地址为 220.181.0.1,
通过这个 ip 地址找到客户端到服务器的路径,客户端浏览器发起一个 http会话
到 220.181.0.1,然后通过 TCP 进行封装数据包,输入到网络层。
- 2.在客户端的传输层,把 HTTP 会话请求分成报文段,添加源和目的端口,
如服务器端用 80 端口监听客户端的请求,客户端由系统随机选择一个端口,如
5000,与客户端进行交换,服务器把相应的请求返回给客户端的 5000 端口。然
后使用 ip 层的 ip 地址查找目的端。
- 3.客户端的网络层不用关心应用层和传输层的东西,主要做的是通过查找路
由表确定如何到达服务器,期间可能经过多个路由器。
- 4.客户端的链路层,包通过链路层发送到路由器,通过邻居协议查找给定
的 ip 地址和 MAC 地址,然后发送 ARP 请求查找目的地址,如果得到回应后就可
以使用 ARP 的请求应答交换的 ip 数据包现在就可以传输了,然后发送 Ip数据包到达服务器的地址。
- synchronized
问了TCP有哪些应用场景
Redis:
Redis 数据结构
1. String——字符串
主要是通过sds实现,内部结构
struct sdshdr{
int len;
int free;
char buf[];
}
比起c字符串有以下优点
- 常熟复杂度获取字符长度:结构中的len
- 杜绝缓冲区溢出:当对sds修改时会判断free空间是否足够
- 减少修改字符串的空间重分配:空间预分配(len=free)和惰性空间释放(缩短字符不会释放sds空间
- 二进制安全:sds是一个字符数组,可以保存任意文本数据,因为它读取使用len,所以sds可以保存字符,而不是像c字符除了结尾其他地方不能为空字符
- 兼容字符串函数:api会将字符末尾设置为空字符,兼容c字符串
2. Hash——字典
typedef struct dictht{
dictEntry **table;
unsigned long size;
unsigned long sizzemask;
unsigned long used;
}dictht;
typedef struct dictEntry{
void *key;
union{
void *val;
uint64_t u64;
int64_t s64;
}v;
struct dictEntry *next;
}dictEntry;
typedef struct dict{
dictType *type;
void *privdata;
dictht ht[2];
int trehashidx;//rehash不进行时为-1
}
- 广泛应用于redis中,比如数据库和hash键
- 底层有两个hash表,一个平时使用,另一个rehash时使用
- hash算法:hash-》index
- 链地址法解决冲突:每个hash结点都有一个next结点。相同索引通过单链表连接
- 渐进式rehash:rehash就是对hash表扩展或者收缩时,将h[0]的数据迁移到h[1]中。h[0]到h[1]的rehash是多次,渐进式的。这样是为了防止rehash的数据量过大,造成服务器停止服务,rehash过程中,查询会到h[0],和h[1]查询,添加只添加到h[1]
3. List——列表
- 列表应用于慢查询、发布于订阅等功能
- 结点由listnode实现,是一个双向链表
typedef struct listNode{
struct listNode *pre;
struct listNode *next;
void *value;
}
- 链表由list实现。有头节点指针,尾结点指针和链表长度
typedef struct list{
listNode *head;
listNode *tail;
unsigned long len;
void *(*dup)(void *ptr);
void *(free)(void *ptr);
int (*match)(void *ptr,void *key);
}list;
4. Set——集合
typedef struct intset{
uint32_t encoding;
uint32_t length;
int8_t contents[]
}intset;
- 整数集合时集合键实现方式之一
- 底层实现为数组,以有序无重复方式保存元素,有需要时会根据新添加类型,改变数组类型
- 升级操作灵活,并且节省内存
- 不支持降级操作
5. Sorted Set——有序集合
- 跳跃表是有序集合的实现之一:集合中数量较多,或者字符过长,使用跳跃表
- 由zskiplist和zskiplistNode组成:zskpilist有head,tail,level,length
typedef struct zskiplistNode {
struvt zskiplistNode *backward;
double score;
robj *obj;
struct zskiplistLevel{
struct zskiplistNode *forward;
unsigned int span;
}level[];
}zskiplistNode;
- RDB文件
- RDB文件保存和还原数据库键值对
- save命令由服务器保存操作,阻塞服务器
- bgsave由子进程执行,不阻塞服务器
- 服务器状态会保存用save选项设置的保存条件,任意一个保存条件被满足,会自动执行bgsave
- RDB是压缩的二进制文件
- 不同类型键值对,RDBB会用不同方式保存
- AOF持久化
redis 主从复制过程
- redis2.8以前不能高效处理断电后重复复制问题,2.8以后的部分重同步可以解决这个问题
- 部分重同步通过复制偏移量、复制积压缓冲区、服务器运行ID实现
- 复制操作开始,从服务器会变成主服务器的客户端,并向主服务器发送命令来执行复制步骤。后期,会成为双方的客户端
主服务器通过传播命令更新从服务器状态,保持主从服务器一致,而从服务器通过向主服务器发送命令进行心跳检测,以及命令丢失检测
redis 使用场景
- 显示最新的项目列表:LTRIM latest.comments 0 5000
- 排行榜应用,取TOP N操作:ZREVRANGE leaderboard 0 99
- 删除与过滤:我们可以使用LREM来删除评论
- 计数:INCR user: EXPIRE
交集,并集,差集:(Set)
优点:
- 读写性能优异
- 支持数据持久化,支持AOF和RDB两种持久
- 支持主从复制,主机会自动将数据同步到从机,可以进行读写分离。
数据结构丰富:除了支持string类型的value外还支持string、hash、set、sortedset、list等数据结构
设计模式
- 简单工厂模式:简单工厂模式是属于创建型模式,又叫做静态工厂方法(Static Factory Method)模式,但不属于23种GOF设计模式之一。简单工厂模式是由一个工厂对象决定创建出哪一种产品类的实例。简单工厂模式是工厂模式家族中最简单实用的模式,可以理解为是不同工厂模式的一个特殊实现。
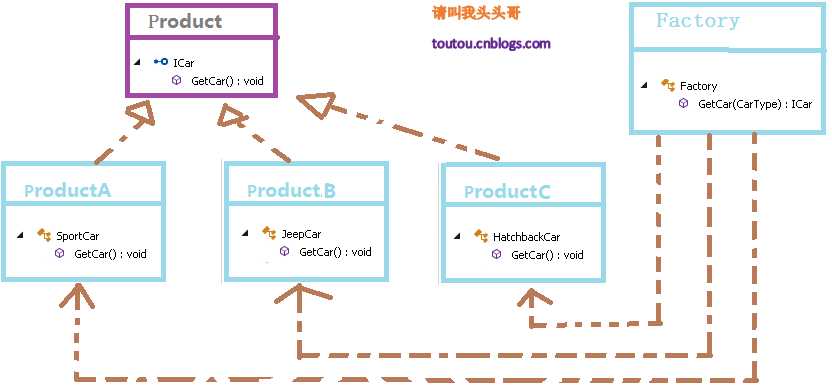
- 优点:简单工厂模式能够根据外界给定的信息,决定究竟应该创建哪个具体类的对象。明确区分了各自的职责和权力,有利于整个软件体系结构的优化。
- 缺点:很明显工厂类集中了所有实例的创建逻辑,容易违反GRASPR的高内聚的责任分配原则
- 工厂方法:在工厂方法模式中,核心的工厂类不再负责所有的产品的创建,而是将具体创建的工作交给子类去做。该核心类成为一个抽象工厂角色,仅负责给出具体工厂子类必须实现的接口,而不接触哪一个产品类应当被实例化这种细节。
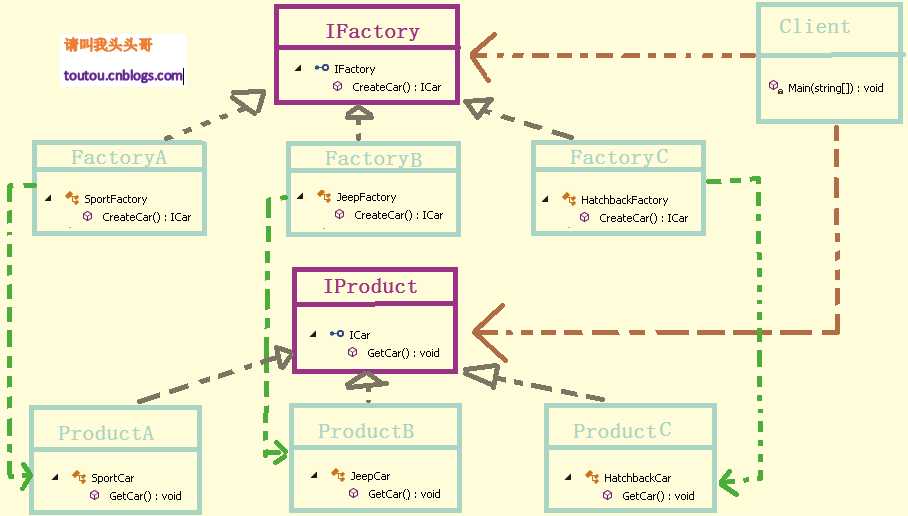
- 优点:
子类提供挂钩。基类为工厂方法提供缺省实现,子类可以重写新的实现,也可以继承父类的实现。-- 加一层间接性,增加了灵活性
屏蔽产品类。产品类的实现如何变化,调用者都不需要关心,只需关心产品的接口,只要接口保持不变,系统中的上层模块就不会发生变化。
典型的解耦框架。高层模块只需要知道产品的抽象类,其他的实现类都不需要关心,符合迪米特法则,符合依赖倒置原则,符合里氏替换原则。
多态性:客户代码可以做到与特定应用无关,适用于任何实体类。
- 缺点:需要Creator和相应的子类作为factory method的载体,如果应用模型确实需要creator和子类存在,则很好;否则的话,需要增加一个类层次。(不过说这个缺点好像有点吹毛求疵了)
- 抽象工厂模式:抽象工厂模式是指当有多个抽象角色时,使用的一种工厂模式。抽象工厂模式可以向客户端提供一个接口,使客户端在不必指定产品的具体的情况下,创建多个产品族中的产品对象。
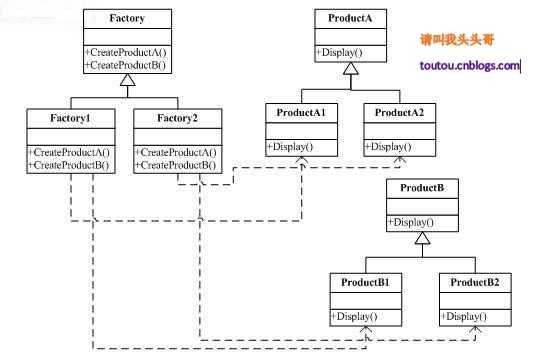
- 优点:
抽象工厂模式隔离了具体类的生产,使得客户并不需要知道什么被创建。
当一个产品族中的多个对象被设计成一起工作时,它能保证客户端始终只使用同一个产品族中的对象。
增加新的具体工厂和产品族很方便,无须修改已有系统,符合“开闭原则”。
- 缺点:增加新的产品等级结构很复杂,需要修改抽象工厂和所有的具体工厂类,对“开闭原则”的支持呈现倾斜性。(不过说这个缺点好像有点吹毛求疵了)
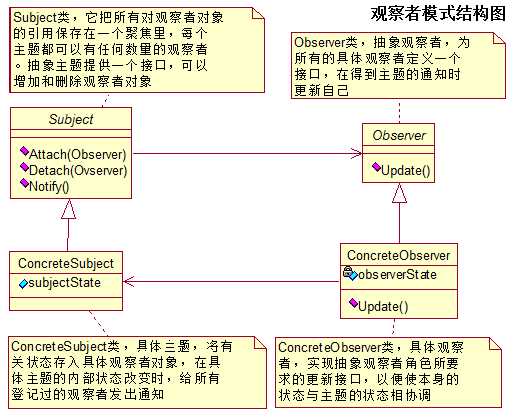
- 观察者模式:定义了一对多的依赖关系,让多个观察者同时监听同一个主题对象,这个主题对象在状态发生变化时,会通知所有观察者对象,使它们能够自动更新自己
- 建造者模式:将一个复杂对象的构建和它的表示分离,使得同样构建过程可创建不同表示。建造者模式可以将部件和其组装过程分开,一步一步创建一个复杂的对象。用户只需要指定复杂对象的类型就可以得到该对象,而无须知道其内部的具体构造细节.

- 优点:1) 客户端不必知道产品内部组成的细节,将产品本身与产品的创建过程解耦,使得相同的创建过程可以创建不同的产品对象。
2) 每一个具体建造者都相对独立,而与其他的具体建造者无关,因此可以很方便地替换具体建造者或增加新的具体建造者, 用户使用不同的具体建造者即可得到不同的产品对象 。
3) 可以更加精细地控制产品的创建过程 。将复杂产品的创建步骤分解在不同的方法中,使得创建过程更加清晰,也更方便使用程序来控制创建过程。
4) 增加新的具体建造者无须修改原有类库的代码,指挥者类针对抽象建造者类编程,系统扩展方便,符合 “开闭原则”
- 缺点:) 产品之间差异性很大的情况: 建造者模式所创建的产品一般具有较多的共同点,其组成部分相似,如果产品之间的差异性很大,则不适合使用建造者模式,因此其使用范围受到一定的限制。
2) 产品内部变化很复杂的情况: 如果产品的内部变化复杂,可能会导致需要定义很多具体建造者类来实现这种变化,导致系统变得很庞大。
- 外观模式:外观模式(Facade),他隐藏了系统的复杂性,并向客户端提供了一个可以访问系统的接口。这种类型的设计模式属于结构性模式。为子系统中的一组接口提供了一个统一的访问接口,这个接口使得子系统更容易被访问或者使用
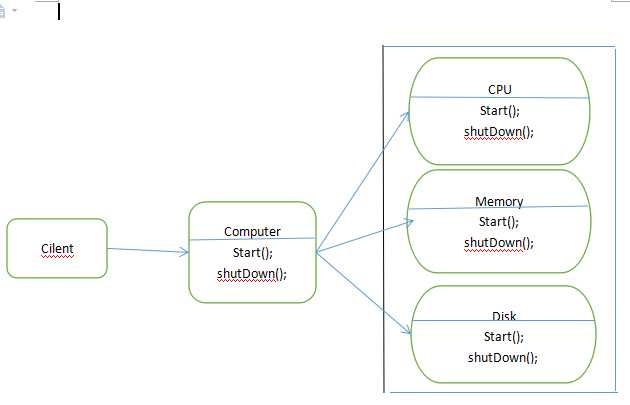
- 优点:
松散耦合:
使得客户端和子系统之间解耦,让子系统内部的模块功能更容易扩展和维护;
简单易用:客户端根本不需要知道子系统内部的实现,或者根本不需要知道子系统内部的构成,它只需要跟Facade类交互即可。
更好的划分访问层次:
有些方法是对系统外的,有些方法是系统内部相互交互的使用的。子系统把那些暴露给外部的功能集中到门面中,这样就可以实现客户端的使用,很好的隐藏了子系统内部的细节。
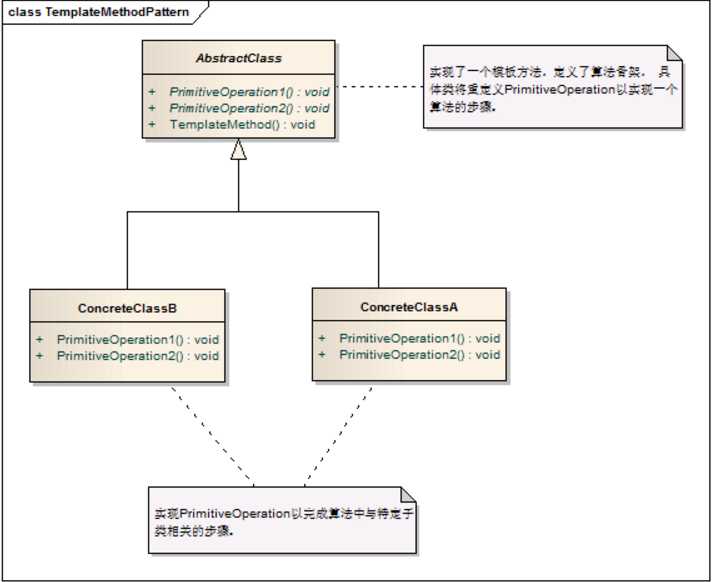
- 模板方法: 定义一个操作中算法的骨架,而将一些步骤延迟到子类中,模板方法使得子类可以不改变算法的结构即可重定义该算法的某些特定步骤。
通俗点的理解就是 :完成一件事情,有固定的数个步骤,但是每个步骤根据对象的不同,而实现细节不同;就可以在父类中定义一个完成该事情的总方法,按照完成事件需要的步骤去调用其每个步骤的实现方法。每个步骤的具体实现,由子类完成
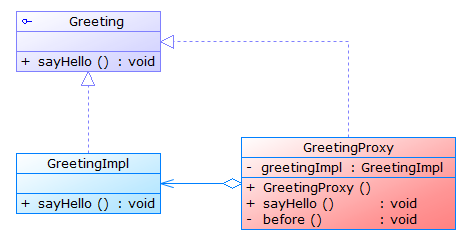
- 代理模式
代理
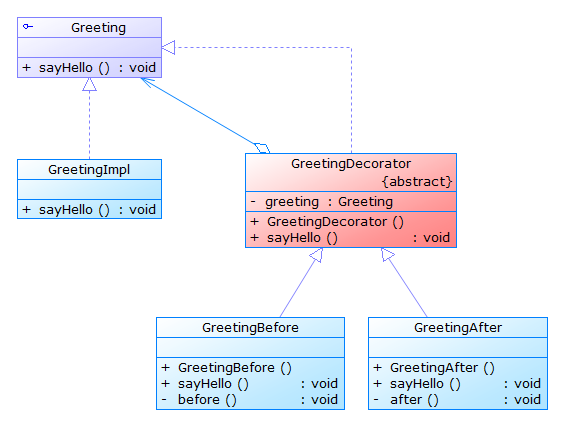
- 装饰模式:装饰器模式,顾名思义,就是对已经存在的某些类进行装饰,以此来扩展一些功能

面试准备
标签:简单工厂 strong 低耦合 role 效率 缓冲区溢出 数据同步 http请求 tmp
原文地址:https://www.cnblogs.com/HannahLihui/p/10467831.html