标签:enc turn 方式 .com 联系 集合 import sep ems
1.列表,元组,字典,集合分别如何增删改查及遍历。
#列表的遍历 myList=["小红","小李",80,90] print("列表的遍历:") for l1 in myList: print(l1) #元组的遍历 myTuple=(23,65,79,50) print("元组的遍历:") for T1 in myTuple: print(T1) #集合的遍历 mySet={43,58,90,74} print("集合的遍历:") for S1 in mySet: print(S1) #字典的遍历 classmate=["张三","李四","小虎"] sorce=[89,76,90] d={} print("字典的遍历:") d=dict(zip(classmate,sorce)) for i in d.keys(): print(i,d[i])

2.总结列表,元组,字典,集合的联系与区别。参考以下几个方面:
列表和元组有很多相似的地方,操作也差不多。不过列表是可变序列,元组为不可变序列。也就是说列表主要用于对象长度不可知的情况下,而元组用于对象长度已知的情况下,而且元组元素一旦创建变就不可修改。 字典主要应用于需要对元素进行标记的对象,这样在使用的时候便不必记住元素列表中或者元组中的位置,只需要利用键来进行访问对象中相应的值。集合中的元素不可重复的特点使它被拿来去重。列表和元组的存储与查找方式通过值来完成,而字典则是通过键值对(键不能重复)来完成,集合则是通过键(不能重复)来完成。
3.词频统计
1.下载一长篇小说,存成utf-8编码的文本文件 file
2.通过文件读取字符串 str
3.对文本进行预处理
4.分解提取单词 list
5.单词计数字典 set , dict
6.按词频排序 list.sort(key=lambda),turple
7.排除语法型词汇,代词、冠词、连词等无语义词
exclude={‘a‘,‘the‘,‘and‘,‘i‘,‘you‘,‘in‘,‘but‘,‘not‘,‘with‘,‘by‘,‘its‘,‘for‘,‘of‘,‘an‘,‘to‘} #定义数组#
#读取Harry Potter.txt文件中的英文内容#
def gettxt():
sep=".,:;?!-_‘"
txt=open(‘C:/Users/Administrator/Desktop/简爱.txt‘,‘r‘).read().lower()
for ch in sep :
txt=txt.replace(ch,‘ ‘)
return txt
#分解提取单词#
bigList=gettxt().split()
print(bigList);
print(‘big:‘,bigList.count(‘big‘))
bigSet=set(bigList)
#过滤单词,包括一些冠词和连词等#
bigSet=bigSet-exclude
print(bigSet)
#单词计数#
bigDict={}
for word in bigSet:
bigDict[word]=bigList.count(word)
print(bigDict)
print(bigDict.items())
word=list(bigDict.items())
#按词频排序#
word.sort(key=lambda x:x[1],reverse=True)
print(word)
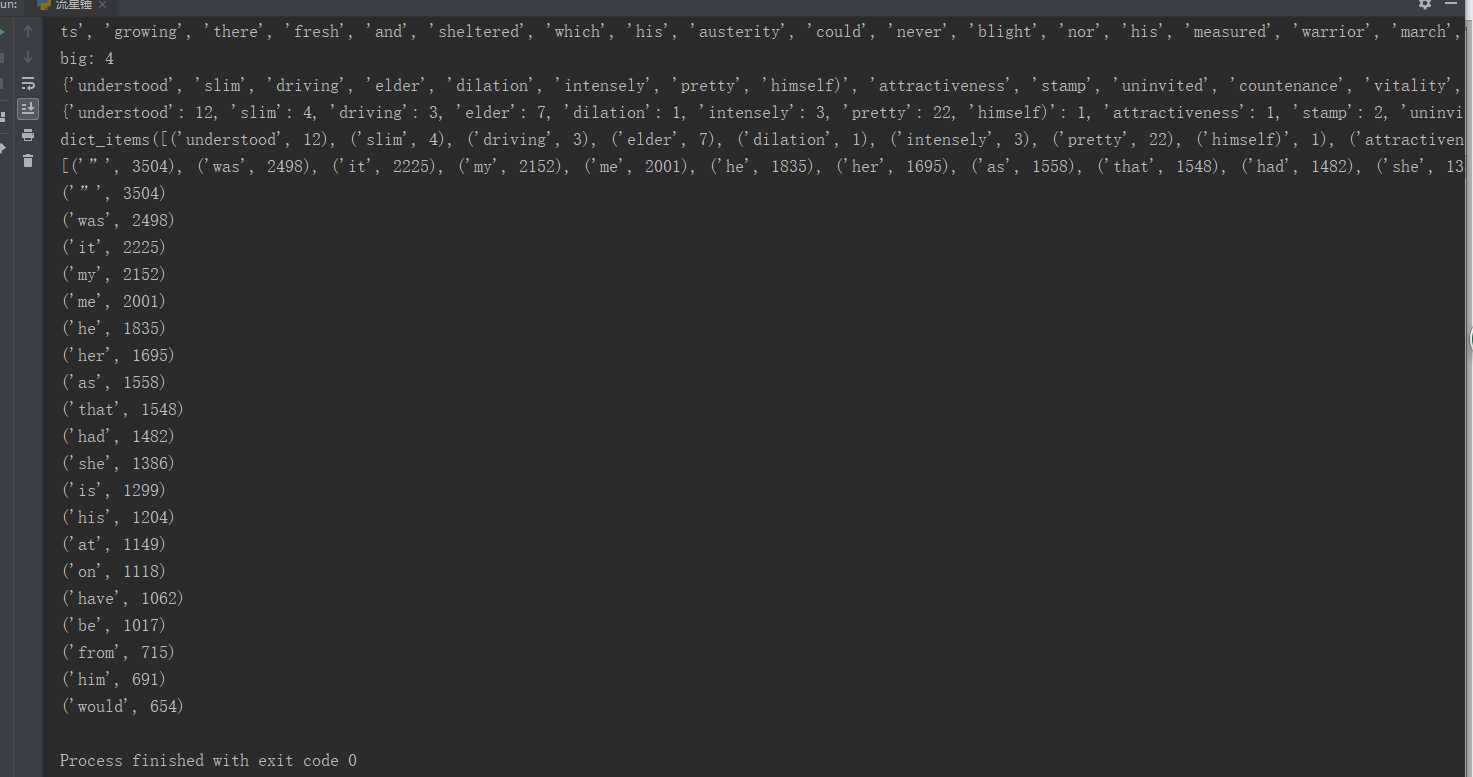
#输出频率较高的词语top20#
for i in range(20):
print(word[i])
#排序好的单词列表word保存成csv文件#
import pandas as pd
pd.DataFrame(data=word).to_csv(‘C:/Users/Administrator/Desktop/简爱.csv‘,encoding=‘utf-8‘)
8.输出TOP(20)
标签:enc turn 方式 .com 联系 集合 import sep ems
原文地址:https://www.cnblogs.com/destinymingyun/p/10531764.html