标签:行存储 并行 数据文件 处理 分区 ext rri 逻辑 mic
一、Maptask并行度与决定机制
1.一个job任务的map阶段的并行度默认是由该任务的大小决定的;
2.一个split切分分配一个maprask来并行处理;
3.默认情况下,split切分的大小等于blocksize大小;
4.切片不是mapper类中对单词的切片,而是对每一个处理文件的单独切片。
eg. 默认情况下,一个maptask处理的文件大小为128M,比如一个400M的数据文件,就需要4个maptask并行来处理,而500M的数据文件也是需要4个maptask。
二、Maptask运行机制
1.读数据文件:执行类Driver通过InputFormat类读取文件中的数据;
2.mapper阶段:通过文件的大小决定了maptask的数量,然后mapper进行逻辑运行(读数据、切分、封装);
3.OutputCollector阶段:mapper方法通过OutputCollector接口将KV对写入到环形缓冲区中(这个过程不需要我们处理我们);
4.溢写阶段:环形缓冲区默认的大小为100M,当环形缓冲区中数据量到达阈值的80%的时候发生溢写,溢写的过程中会保证数据KV对使用默认的分区和排序(HashPartitioner分区、字典排序,而环形缓冲区大小和阈值的大小都是可以通过配置来修改的);
5.归并排序:将溢写的数据进行合并排序。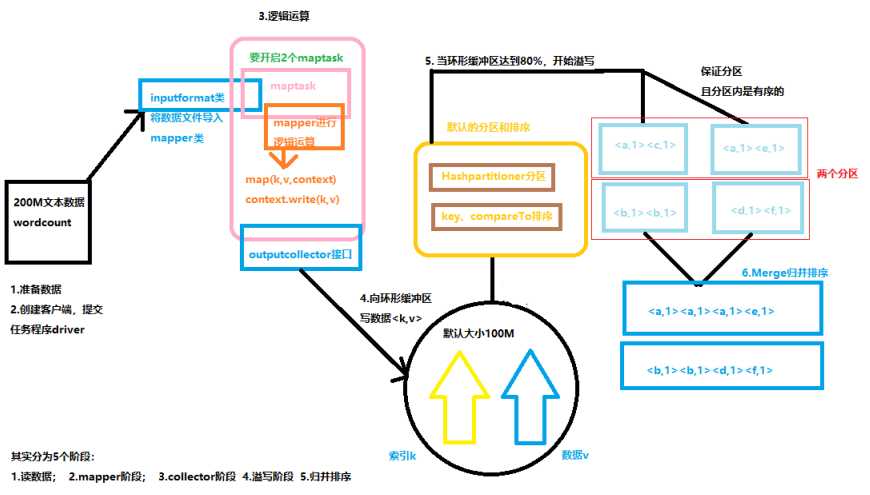
三、MR的小文件优化案例
当许多个小文件上传到HDFS集群上时,每个小文件都将会占用一个blocksize的大小(128M),而且在对它们进行MR计算时,一个文件就会开启一个maptask,这样会浪费很多的资源,下面有两种解决方案:
1.在文件上传到HDFS集群前,先将文件进行合并成一个大的文件,再上传到HDFS集群进行存储和计算;
2.若文件已经上传到HDFS集群,需要直接进行计算时,
可以再Driver类中设置输入流之前设置InputFormatClass属性为CombinerTextInputFormat(它的默认为TextInputFormat),
原理是:CombineTextInputFormat类可以将多个小文件交给一个split切片,然后交给一个maptask来处理,即再Driver类中设置输入流FileInputFormat前加入代码:
job.setInputFormatClass(CombinerTextInputFormat.class); CombinerTextInputFormat.setMaxInputSplitSize(job,4194304); //设置切片最大值为4M CombinerTextInputFormat.setMinInputSplitSize(job,3145725); //设置切片最大值为3M
表示大小在3M~4M的文件会被方法一个切片中,那么如果有无数的小文件,一个maptask中大概会有28~42个小文件一起处理。
四、自定义分区Partitioner
在MR程序中,默认分区为HashPartitioner,以下为源码:
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public HashPartitioner() {
}
public int getPartition(K key, V value, int numReduceTasks) {
return (key.hashCode() & 2147483647) % numReduceTasks;
}
}
HashPartitioner继承了父类Partitioner,其中getPartition方法返回int值0(注释:分区数量决定了reducetask的数量,不分区reducetask值为1,所以一直返回int值0,也就只会产生一个结果文件!!!)
而如果我们想要进行自定义分区,就要重新定义一个分区类继承Partitioner类:
public class FlowPartitioner extends Partitioner<Text,FlowBean> {
@Override
public int getPartition(Text key, FlowBean value, int i) {
//获取用来分区的电话号码前三位
String phoneNum = key.toString().substring(0, 3);
//设置分区逻辑
int partitionNum = 4;
if ("135".equals(phoneNum)){
return 0;
}else if ("137".equals(phoneNum)){
return 1;
}else if ("138".equals(phoneNum)){
return 2;
}else if ("139".equals(phoneNum)){
return 3;
}
return partitionNum;
}
}
我在流量统计案例中也写了该分区类,然后再Driver类中的InputFormat类之前加入设置的自定义分区代码:
job.setPartitionClass(PhoneNumPartitioner.class); job.setNumReduceTasks(5); (注意:输出文件数量要大于partitioner分区的数量)
总结:MR程序运算过程中,决定maptask个数的有块大小(blocksize)、数据文件大小、文件输入方式(小文件优化);而决定reducetask个数的是分区(无分区时reducetask个数为1,生成一个结果文件)。
标签:行存储 并行 数据文件 处理 分区 ext rri 逻辑 mic
原文地址:https://www.cnblogs.com/HelloBigTable/p/10591105.html