标签:min ali ctr 线性 最小 基本 mamicode 需要 src
如果我们的数据非常大,有多个对象,如果一对一对的比较,需要比较N*(N-1)/2,检查每一对数据很困难。
大体思路:用一个函数f(x, y)来判断x和y是不是一个候选对,计算候选对的相似度。
For minhash matrics:把矩阵列分为很多桶(buckets),相似度高的行放到相同的桶里。
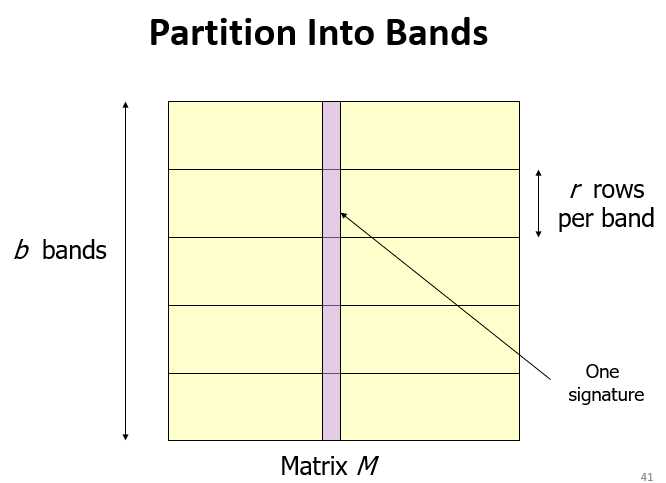
调整b和r捕捉最相似的对。
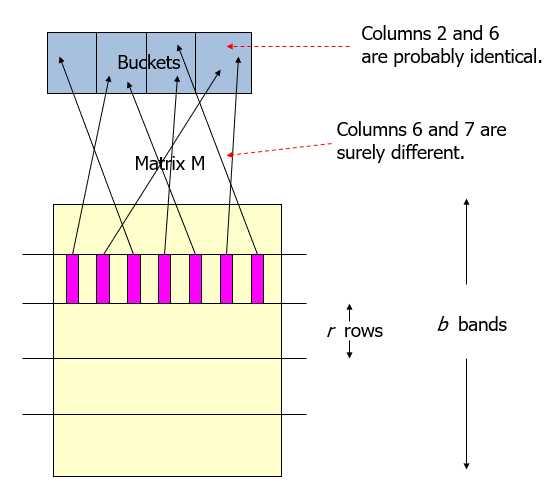
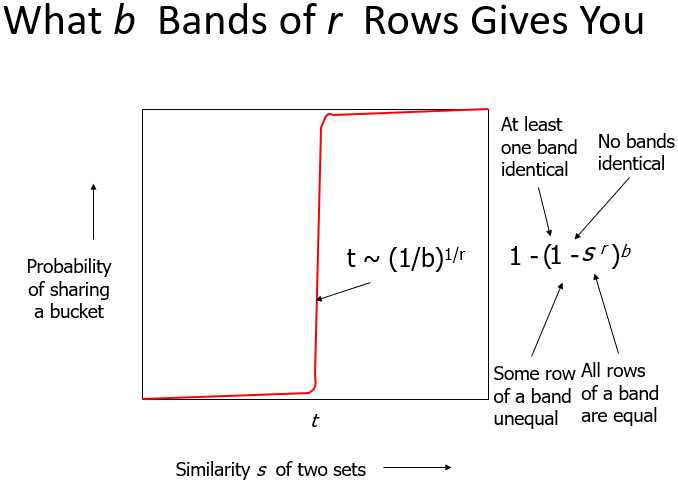
t是阈值,相似的会更加相似,不相似的会更加不相似。
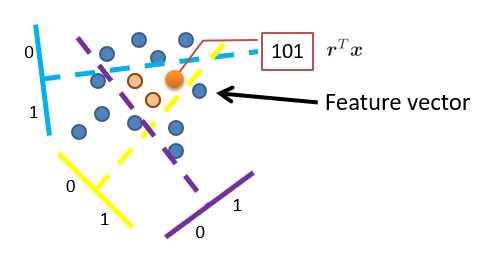
rT*x是一个超平面。
1.Projection Stage:得到一个转换矩阵W,Y = WT
2.Quantization Stage(定量阶段):h(x) = sgn(WTx)
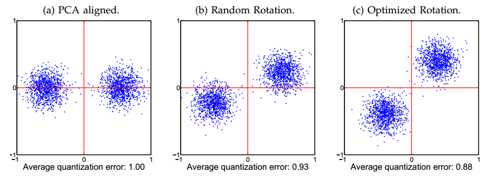
Q(B, Y) = ||B - YTR||F2
B = Sgn(YTR)
R = orthogonal matrix
B = binary hash code
Y = WTX
最基本的方法就是变换数据是的定量损失最小,此变换指线性代数中的线性变换。

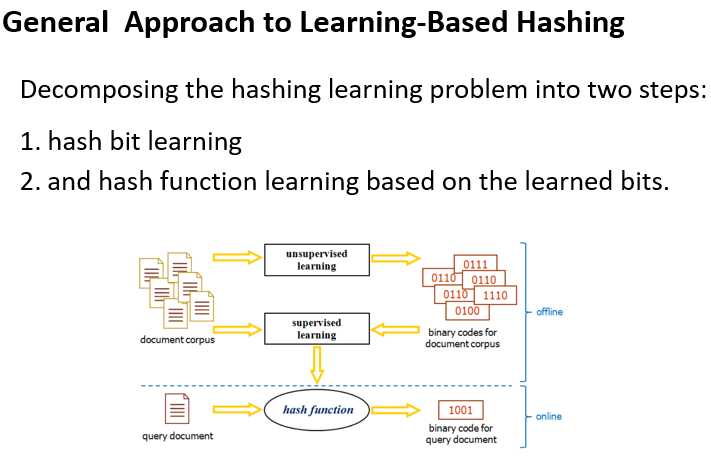
相较于数据独立方法,数据依赖方法(data-dependent methods/learning to hash)使用短的二进制代码可以获得更高的精度和可比较性。也可分为监督学习和非监督学习。
标签:min ali ctr 线性 最小 基本 mamicode 需要 src
原文地址:https://www.cnblogs.com/sharalynwon/p/10596141.html