标签:range file compile tle 拷贝 doc image merger bookmarks
前些天无意间看到了“birdben”的博客,写的比较详细,但是最新的文章更新时间是“2017-05-07”,时间很是久远,本打算有时间认真学习一下博主所写的文章,但是担心网站会因为某些原因停止服务,于是想到将博主写的所有文章爬下来保存成pdf,说干就干!
你们可以点击这里,查看博主的网站。
pdfkit:可以将文本、html、url转成pdf,但是需要安装wkhtmltopdf.exe,并获取它的安装路径
pdfkit是基于wkhtmltopdf的python封装,支持url,本地文件,文本内容转成pdf,最终还是调用wkhtmltopdf的命令
PyPDF2:处理pdf的模块,可读可写可合并
主页url:https://birdben.github.io/ 第二页url:https://birdben.github.io/page/2/ 最后一页url:https://birdben.github.io/page/14/
某篇文章的url:

查看主页的html
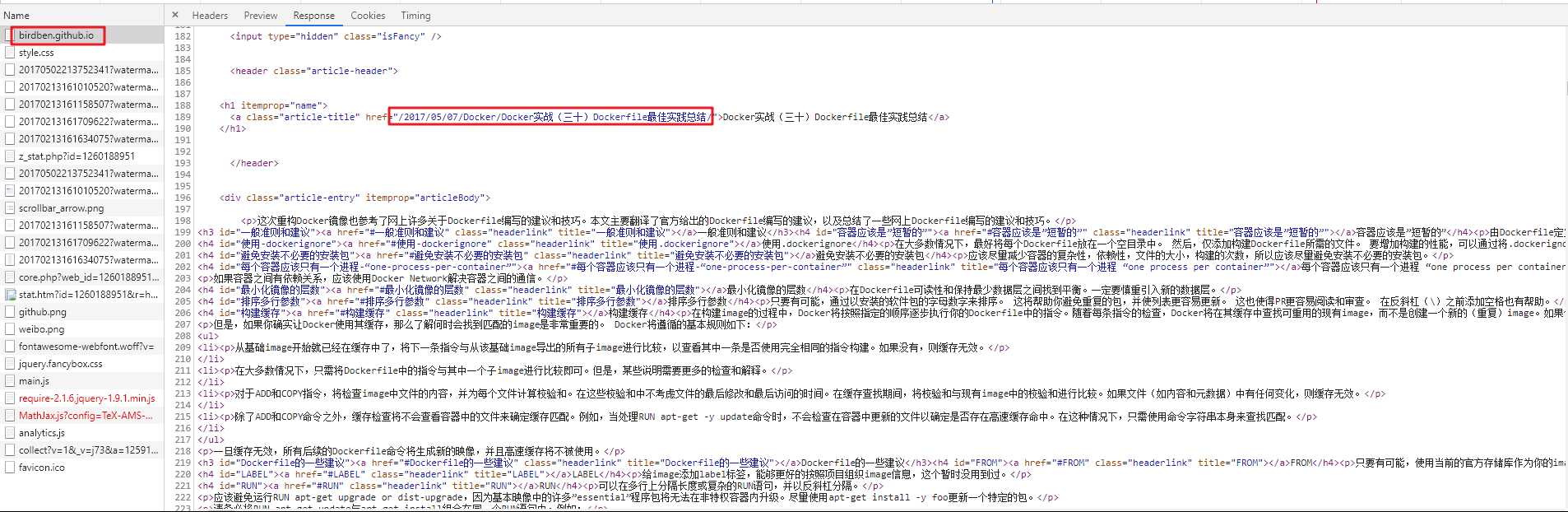
可以看出:该博客网站共有15个主页面,每篇文章的url可以使用 “主页url” + “href” (见上图)
def geturl():
url = "https://birdben.github.io/archives/"
list = [url]
for i in range(2,15):
str = "%spage/%d/" % (url,i)
list.append(str)
return list
返回的结果:

def getname(url,):
r = requests.get ( url )
str = "".join(r.text)
pattern = re.compile(r‘<a class="archive-article-title" href="(.*)">.*?</a>‘)
match = pattern.findall(str)
r.close()
return match
结果:

import requests
import re
import pdfkit
from PyPDF2 import PdfFileReader, PdfFileMerger
import os
#获取一个页面所有的 文章全称 用于构建每篇文章的url路径
def getname(url,):
r = requests.get ( url )
str = "".join(r.text)
pattern = re.compile(r‘<a class="archive-article-title" href="(.*)">.*?</a>‘)
match = pattern.findall(str)
r.close()
return match
#获取他的所有页面,每个页面会有很多文章
def geturl():
url = "https://birdben.github.io/archives/"
list = [url]
for i in range(2,15):
str = "%spage/%d/" % (url,i)
list.append(str)
return list
#将url转换成pdf
def savepdf(url,pdfname):
path_wkthmltopdf = r"C:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe"
config = pdfkit.configuration ( wkhtmltopdf=path_wkthmltopdf )
pdfkit.from_url ( url , pdfname , configuration=config )
#爬取所有文章转成pdf
def do():
urllist = geturl()
for url in urllist:
namelist = getname(url)
for blog in namelist:
blogurl = "https://birdben.github.io" + blog
pdfname = r"pdf\%s.pdf" % blog.strip("/").split("/")[-1] #将pdf保存到当前目录下的pdf目录下,需提前创建
print(blogurl,pdfname)
savepdf(blogurl,pdfname)
#合并pdf
def mergepdf(tmpdir,mergename): #合并文件存放的路径,合并后的pdf文件名
merger = PdfFileMerger()
listfile = [os.path.join(tmpdir, file) for file in os.listdir(tmpdir)]
for file in listfile:
if file.endswith(‘.pdf‘):
filemsg = PdfFileReader(open(file, ‘rb‘))
label = file.split(‘\\‘)[-1].replace(".pdf", "")
merger.append (filemsg, bookmark=label , import_bookmarks=False)
merger.write(mergename)
merger.close()
以上代码是使用到的所有函数
执行:
if __name__ == ‘__main__‘:
do()
#mergepdf("merge",r"merge\docker.pdf") 当do函数执行完后,将需要合并的pdf放到merge目录下(提前创建),再将do注释,再执行mergepdf函数即可
爬取所有文章生成pdf,将生成的pdf放在pdf目录下,需提前创建
将每部分pdf拷贝到另外目录merge下
最终的pdf:
标签:range file compile tle 拷贝 doc image merger bookmarks
原文地址:https://www.cnblogs.com/zqj-blog/p/10602702.html