标签:list app shuffle code res 数据集 centos 并行 默认
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk1.8
scala-2.10.4(依赖jdk1.8)
spark-1.6
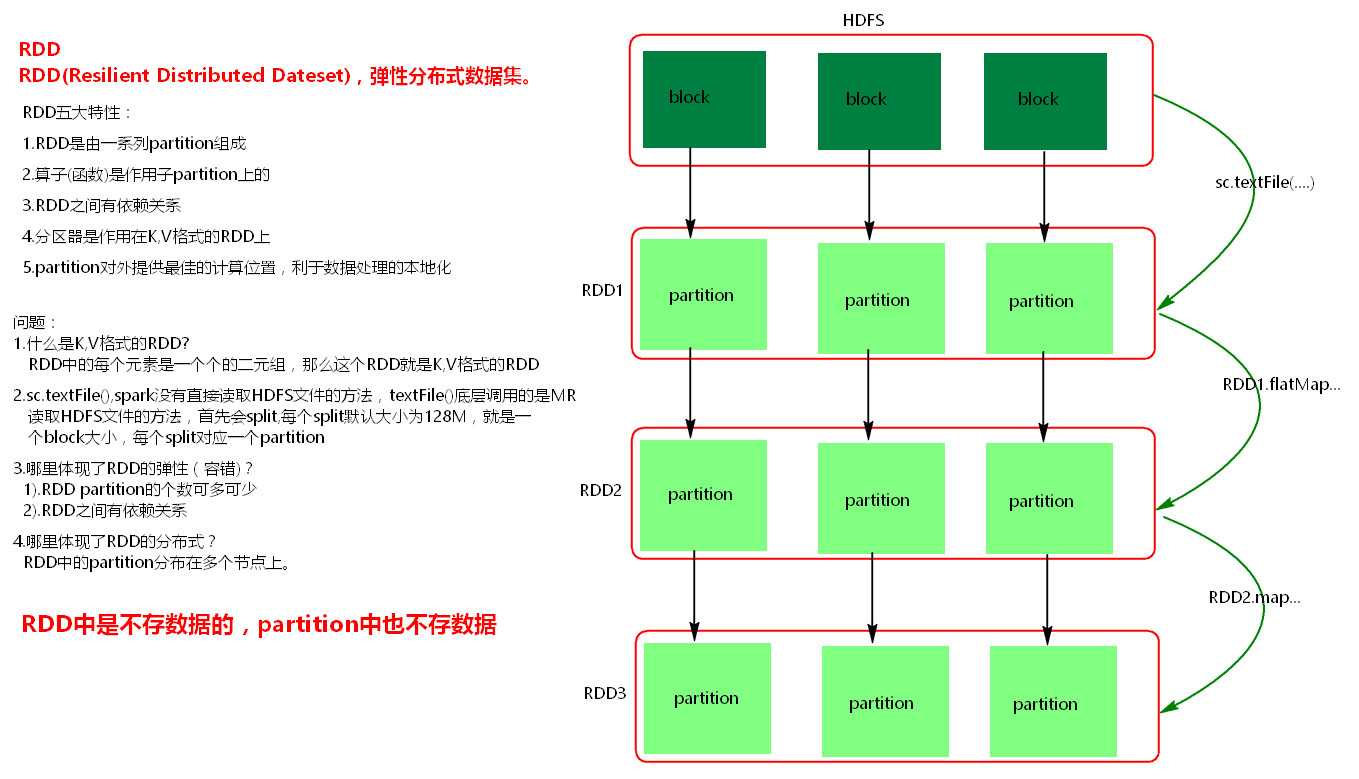
一、RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
RDD特性:
(1)一组分片(Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。
(2)一个计算每个分区的函数。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
(3)RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
(4)一个Partitioner,即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
(5)一个列表,存储存取每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
创建RDD:

二、Spark任务执行原理
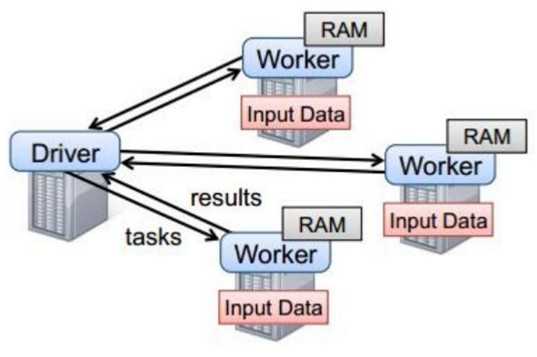
以上图中有四个机器节点,Driver和Worker是启动在节点上的进程,运行在JVM中的进程。
? Driver与集群节点之间有频繁的通信。
? Driver负责任务(tasks)的分发和结果的回收。任务的调度。如果task的计算结果非常大就不要回收了,会造成oom。
? Worker是Standalone资源调度框架里面资源管理的从节点,也是JVM进程。
? Master是Standalone资源调度框架里面资源管理的主节点。也是JVM进程。
三、Spark代码流程
1. 创建SparkConf对象
? 可以设置Application name。
? 可以设置运行模式及资源需求。
2. 创建SparkContext对象
3. 基于Spark的上下文创建一个RDD,对RDD进行处理。
4. 应用程序中要有Action类算子来触发Transformation类算子执行。
5. 关闭Spark上下文对象SparkContext。
四、Transformations转换算子
Transformations 转换算子是延迟执行,也叫懒加载执行。
filter:过滤符合条件的记录数,true保留,false过滤掉。
map:将一个RDD中的每个数据项,通过map中的函数映射变为一个新的元素。特点:输入一条,输出一条数据。
flatMap:先map后flat。与map类似,每个输入项可以映射为0到多个输出项。
sample:随机抽样算子,根据传进去的小数按比例进行又放回或者无放回的抽样。
reduceByKey:将相同的Key根据相应的逻辑进行处理。
sortByKey/sortBy:作用在K,V格式的RDD上,对key进行升序或者降序排序。

五、Action行动算子
Action类算子叫做行动算子,如foreach,collect,count等。Transformations类算子是延迟执行,Action类算子是触发执行。一个application应用程序中有几个Action类算子执行,就有几个job运行。
count:返回数据集中的元素数。会在结果计算完成后回收到Driver端。
take(n):返回一个包含数据集前n个元素的集合。
first:first=take(1),返回数据集中的第一个元素。
foreach:循环遍历数据集中的每个元素,运行相应的逻辑。
collect:将计算结果回收到Driver端。

六、控制算子
控制算子有三种:cache,persist,checkpoint,以上算子都可以将RDD持久化,持久化的单位是partition。
cache和persist都是懒执行的。必须有一个action类算子触发执行。
checkpoint算子不仅能将RDD持久化到磁盘,还能切断RDD之间的依赖关系。

1、cache:默认将RDD的数据持久化到内存中,cache是懒执行。
SparkConf conf = new SparkConf(); conf.setMaster("local").setAppName("CacheTest"); JavaSparkContext jsc = new JavaSparkContext(conf); JavaRDD<String> lines = jsc.textFile("./NASA_access_log_Aug95"); lines = lines.cache(); long startTime = System.currentTimeMillis(); long count = lines.count(); long endTime = System.currentTimeMillis(); System.out.println("共"+count+ "条数据,"+"初始化时间+cache时间+计算时间="+ (endTime-startTime)); long countStartTime = System.currentTimeMillis(); long countrResult = lines.count(); long countEndTime = System.currentTimeMillis(); System.out.println("共"+countrResult+ "条数据,"+"计算时间="+ (countEndTime-countStartTime)); jsc.stop();
2、persist:可以指定持久化的级别。最常用的是MEMORY_ONLY,MEMORY_AND_DISK,MEMORY_ONLY_SER,MEMORY_AND_DISK_SER。”_2”表示有副本数。
持久化级别如下:

cache和persist的注意事项:
(1)cache和persist都是懒执行,必须有一个action类算子触发执行。
(2)cache和persist算子的返回值可以赋值给一个变量,在其他job中直接使用这个变量就是使用持久化的数据了。持久化的单位是partition。
(3)cache和persist算子后不能立即紧跟action算子。
错误:rdd.cache().count() 返回的不是持久化的RDD,而是一个数值了。
3、checkpoint
checkpoint将RDD持久化到磁盘,还可以切断RDD之间的依赖关系。
checkpoint 的执行原理:
(1)当RDD的job执行完毕后,会从finalRDD从后往前回溯。
(2)当回溯到某一个RDD调用了checkpoint方法,会对当前的RDD做一个标记。
(3)Spark框架会自动启动一个新的job,重新计算这个RDD的数据,将数据持久化到HDFS上。
优化:对RDD执行checkpoint之前,最好对这个RDD先执行cache,这样新启动的job只需要将内存中的数据拷贝到HDFS上就可以,省去了重新计算这一步。
使用:
SparkConf conf = new SparkConf(); conf.setMaster("local").setAppName("checkpoint"); JavaSparkContext sc = new JavaSparkContext(conf); sc.setCheckpointDir("./checkpoint"); JavaRDD<Integer> parallelize = sc.parallelize(Arrays.asList(1,2,3)); parallelize.checkpoint(); parallelize.count(); sc.stop();
参考:
Spark:https://www.cnblogs.com/qingyunzong/category/1202252.html
标签:list app shuffle code res 数据集 centos 并行 默认
原文地址:https://www.cnblogs.com/cac2020/p/10637310.html