标签:阈值处理 网络 ack 架构 mamicode instance 怎么 坐标 忽略
Mask Scoring R-CNN
CVPR2019 | Mask Scoring R-CNN 论文解读

作者 | 文永亮
研究方向 | 目标检测、GAN
推荐理由:
本文解读的是一篇发表于CVPR2019的paper,来自华科和地平线,文章提出了Mask Scoring R-CNN的框架是对Mask R-CNN的改进,简单地来说就是给Mask R-CNN添加一个新的分支来给mask打分从而预测出更准确的分数。
源码地址:https://github.com/zjhuang22/maskscoring_rcnn
研究动机:
Mask R-CNN其实是何恺明大神在Faster R-CNN系列的延伸,Mask R-CNN和Faster R-CNN都是 two stages的,第一阶段是RPN(Region Proposal Network),产生一些候选的目标边界框,使用RoIAlign为每一个候选区域提取特征,生成分类、bbox回归还有mask的预测,其实就是在Faster R-CNN的基础上添加一个新的分支预测mask。
但是Mask R-CNN存在着一个问题,就是在实例分割的任务中,蒙版分割质量是由检测分支的分类置信度决定。然而,mask的质量(我们这里用instance mask和ground truth之间的IoU做评判)通常与分类置信度没有太强的关联。
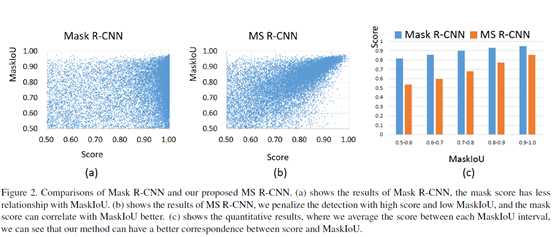
相信大家都知道IoU是目标窗口和原来标记窗口的交叠率,如果Mask R-CNN的分类置信度能够决定分割蒙版的质量的话,也就是说其质量与分类分数呈现相关性,但是从图二(a)中可以看出,当分类分数高于0.5时(横坐标),甚至到达1时,MaskIoU参差不齐,可以说从0.5到1的质量分数都有,从而证实了Mask R-CNN的MaskIoU与分类置信度没有太强的关联。所以作者提出的Mask Scoring R-CNN,MS R-CNN中提出的框架其实很简单,就是在原有的Mask R-CNN框架的基础上添加一个额外的分支MaskIoU head模块,这个模块用来学习MaskIoU。这个框架得到的分数如图二(b)(c)的所示,可以明显看出分类分数高的同时蒙版质量也得到了提升。
Mask Scoring R-CNN:
·Mask Scoring:
既然我们发现了Mask R-CNN的问题,那么我们现在就来解决它,首先我们考虑蒙版的分数由什么决定?
从上面的动机中我们得知,MaskIoU可以来评价蒙版的质量,因为理想的mask应该是与Ground Truth完全重合的,所以我们必须考虑MaskIoU。除此之外,一个理想的评价mask的分数,除了与GT的重合率之外,这个实例分割只属于一个类,对于其他类的分数都为0。所以学习mask的分数就分解成两个任务,就是把mask分类到正确的类中以及把建议框的MaskIoU回归到目标前景中。
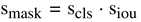
有如上公式,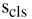 专注于对建议框进行分类,
专注于对建议框进行分类,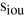 聚焦于回归MaskIoU。
聚焦于回归MaskIoU。
·MaskIoU head:
整个MS R-CNN的改进就在于这个MaskIoU Head,MaskIoU Head模块的输入由两部分组成,一是ROIAlign得到的RoI feature map,二是Mask Head分支输出的mask。Mask经过MaxPooling之后与RoI feature map进行concat,然后经过3层卷积和2层全连接层,输出的就是MaskIoU。以下是其完整的架构,如图三:
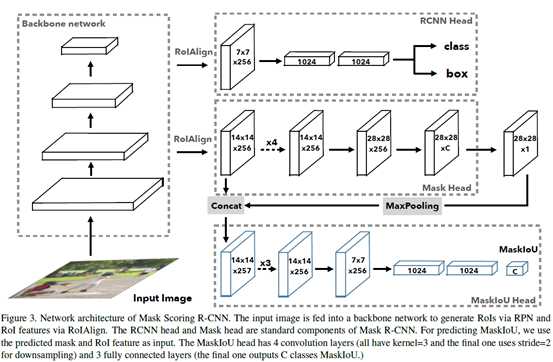
·Training:
怎么训练MaskIoU Head?只把mask分支输出的mask与GT计算IoU作为target是不够的,因为mask分支输出的mask有好有坏,所以文章中做了阈值处理,使用RPN生成的proposals与GT的IoU大于0.5的mask称为binary mask,这个binary mask与GT的MaskIoU就作为MaskIoU的target。
·Inference:
RCNN Head输出的top-k(例如top100)分数的框,经过SoftNMS后,送入Mask Head,得到mask与ROI feature map进行concat送入MaskIoU Head得到MaskIOU,然后与分类结果得到的分数相乘得到mask score。
实验结果:
实验结果这里有很多种不同的AP,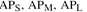 表示在不同scales时的AP,
表示在不同scales时的AP,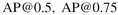 意思是使用了不同IoU阈值。作者用的数据集是COCO 2017val集。
意思是使用了不同IoU阈值。作者用的数据集是COCO 2017val集。
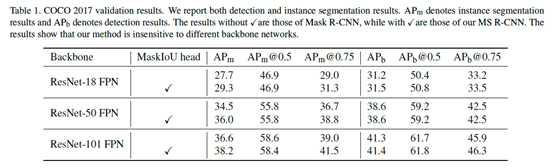
Table 1表明了作者提出的Mask Scoring R-CNN对不同的backbone网络并不敏感,相比Mask R-CNN基本上AP有1点左右的提升。
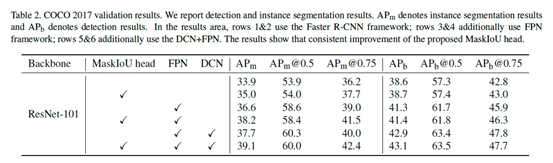
Table 2表明无论是否使用FPN和DCN,MaskIoU head都在AP上有提升。
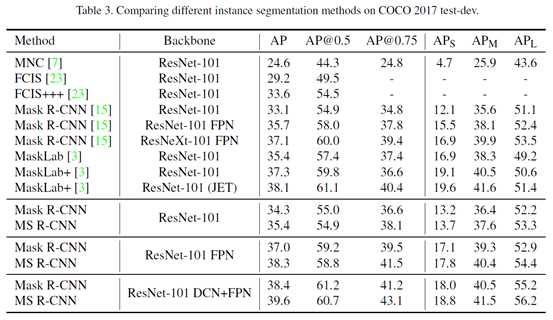
Table 3是跟目前的实例分割方法在COCO 2017 test-dev上做对比。

这是MS R-CNN和Mask R-CNN对比效果,评分得到了修正。
MaskIoU head的各种选择:
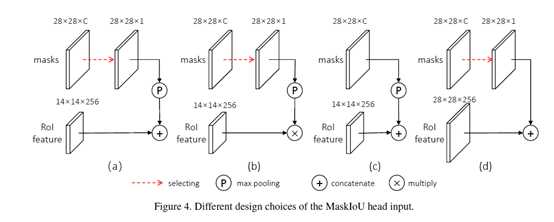
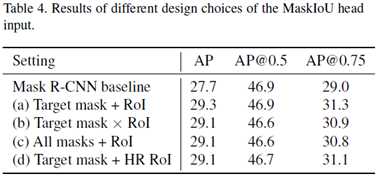
文章做了下面4种输入组合:
1.target mask和ROI feature concat
2.target mask和ROI feature 相乘
3.所有mask和ROI feature concat
4.target mask和高分辨率的ROI feature concat
还有一个问题就是,我们知道RoI内可能有很多种目标类别,我们应该让MaskIoU学习所有的类别,还是学习RoI内的所有出现的类别,抑或是选取RoI内分类得分高的类呢?
由此分成了三种情况:
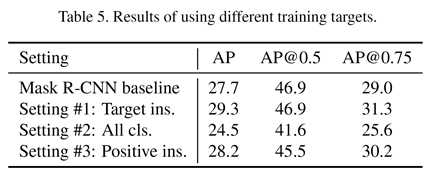
发现第二种情况学习所有类别的情况是最差的,甚至比原来Mask R-CNN的效果还差。而第三种学习所有正类的情况比学习target类别差的原因是学习所有正类会增加MaskIoU head的负担,所以文章选择了学习target类别的情况一。
点评:
作者认为分类置信度不能单纯的作为mask的得分,所以很简单的想法就是另外创建了一个MaskIoU分支学习MaskIoU,最后与分类分数相乘的到Mask Score。感觉与IoU-Net类似。但是这样就导致mask与检测分支相关,使mask受限于box。
CVPR2019 | Mask Scoring R-CNN 论文解读
标签:阈值处理 网络 ack 架构 mamicode instance 怎么 坐标 忽略
原文地址:https://www.cnblogs.com/ManWingloeng/p/10717578.html