标签:简单 inf 操作系统 mil and format 图片 表示 png
ASCII(American Standard Code For Information Interchange)码用一个字节中的7位(低7位)来标识字符,可以表示128个不同的字符(包括26个英文字母、9个数字和一些英文符号)。为了扩充ASCII以显示本国的文字和符号,不同的国家和地区制定了不同的编码标准,包括中国的GB2312、日本的JIS等。这些延伸的编码标准使用两个字节来编码字符,并被称为ANSI编码,又被称为MBCS(Multi-Bytes Character Set,多字节字符集)。ANSI编码方式因环境而异,在简体中文操作系统下,ANSI编码标准是GB2312,在日文操作系统下,ANSI编码标准则是JIS。不同的ANSI编码互不相容,同一个编码值在不同的ANSI编码标准下表示不同的字符。
为了统一编码标准,出现了UNICODE。UNICODE编码范围从0到0x10FFFF,可以编码一百多万个字符,能将世界上所有的字符都纳入其中。但由于字符集过于庞大,以每个字符编码值长度相同的方式来编码的话(UCS-4),每个字符需要四个字节。这种方式会造成空间的浪费,因为4个字节所能表示的字符数量远大于UNICODE字符集的大小。为了节省空间,出现了可变长度编码方式,如UTF-8,UTF-16。
UTF-8的编码单元(code unit,即编码值的最短长度)为8位,每个码点(code point)编码成1至4个字节。它的编码方式很简单,按照码点的范围把码点的二进制位拆分为1至4个字节:
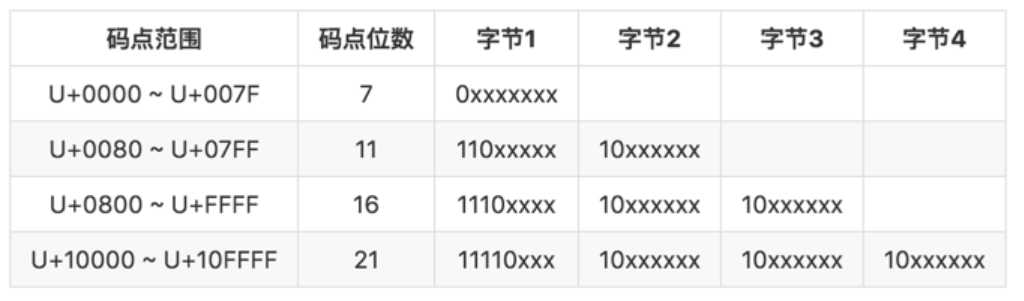
(图源:milo yip)
UTF-8编码的优点:字符长度可变,节省空间,且和ASCII编码兼容。
UTF-16:编码单元为16位,每个码点编码成2或4个字节。向后兼容UCS-2(BMP字符集),取UCS-2中0xD800~0xDBFF范围内的值作为high surrogate,取0xDC00~0xDFFF范围内的值作为low surrogate,high surrogate和low surrogate拼接成为4字节的码点,表示超出BMP的字符。high surrogate和low surrogate部分都有1024种可能的值,因此UTF-16的4字节字符数量为:1024*1024=0x100000,这是UNICODE字符集范围上限是0x10FFFF的原因,为了照顾那些使用UTF-16的语言(如c/c++/java)和操作系统(如windows),这个上限不能突破,哪怕UTF-8和UTF-32能表示更大的字符范围。
参考:
《从零开始的JSON库教程:Unicode》,milo yip
《其实你并不懂Unicode》,纤夫张
注:
VS中有两种字符集,分别是多字节字符集(不是UTF-8)和UNICODE(UTF-16)。
MessageBoxA(NULL, "Hello你好", NULL, MB_OK)
MessageBoxW(NULL, L"Hello你好", NULL, MB_OK)
cout<<"Hello你好"
都能正确显示
wcout<<L"Hello你好"
则不行,需要先wcout.imbue(locale("chs"))
标签:简单 inf 操作系统 mil and format 图片 表示 png
原文地址:https://www.cnblogs.com/ZhaoWenjie/p/10726481.html