标签:修改 cursor result 的区别 nes fine win domain path
scrapy startproject ZuCai
会自动生成2个zucai文件夹
cd ZuCai
cd ZuCai
进入最下面的ZuCai文件夹
scrapy genspider zucai trade.500.com/jczq/
开始分析 https://trade.500.com/jczq/ 这个页面
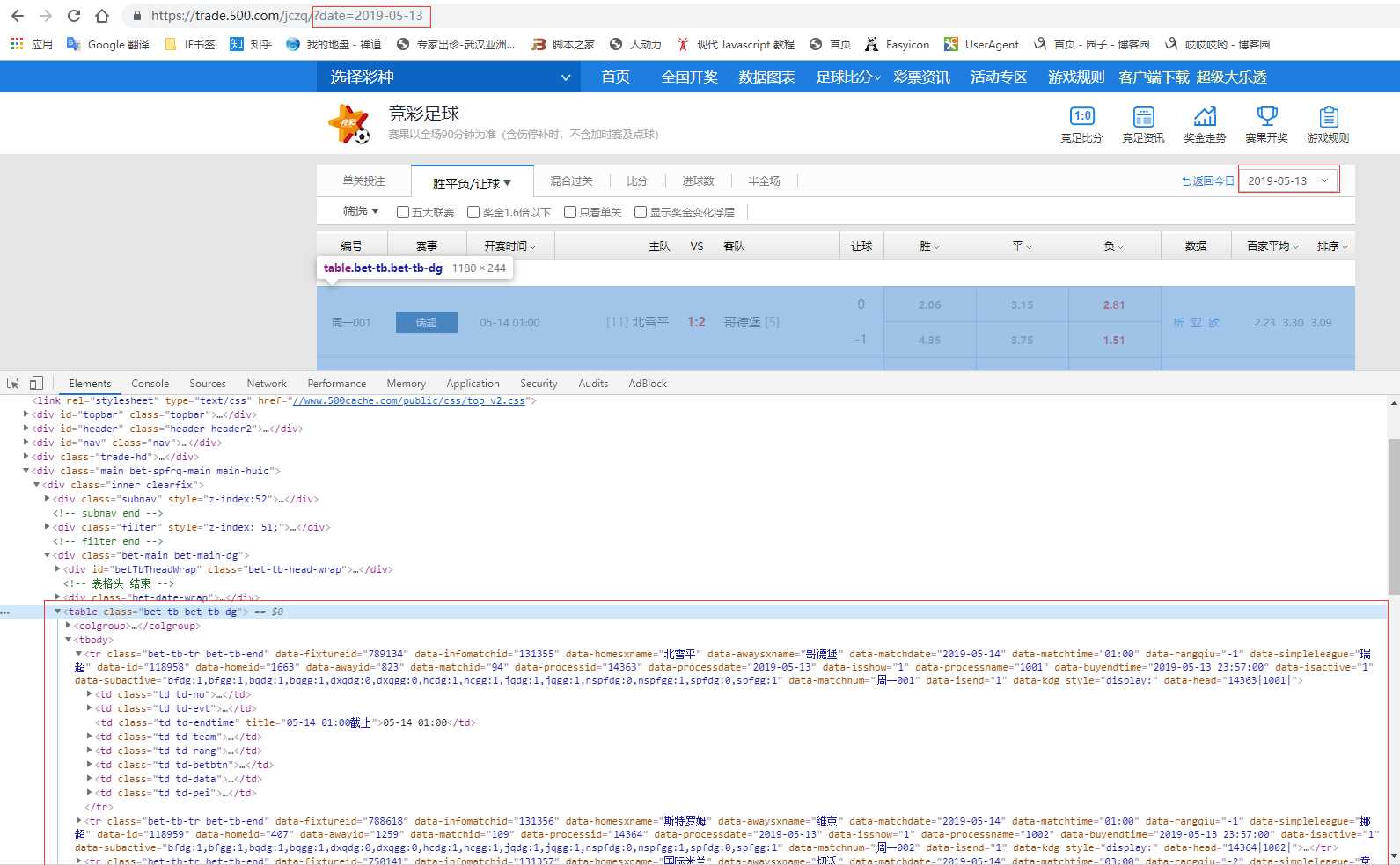
进入页面后,点击F12查看网页代码。通过查找,发现所有的比赛结果全部在 <table class="bet-tb bet-tb-dg">...</table>中,然后继续往下看
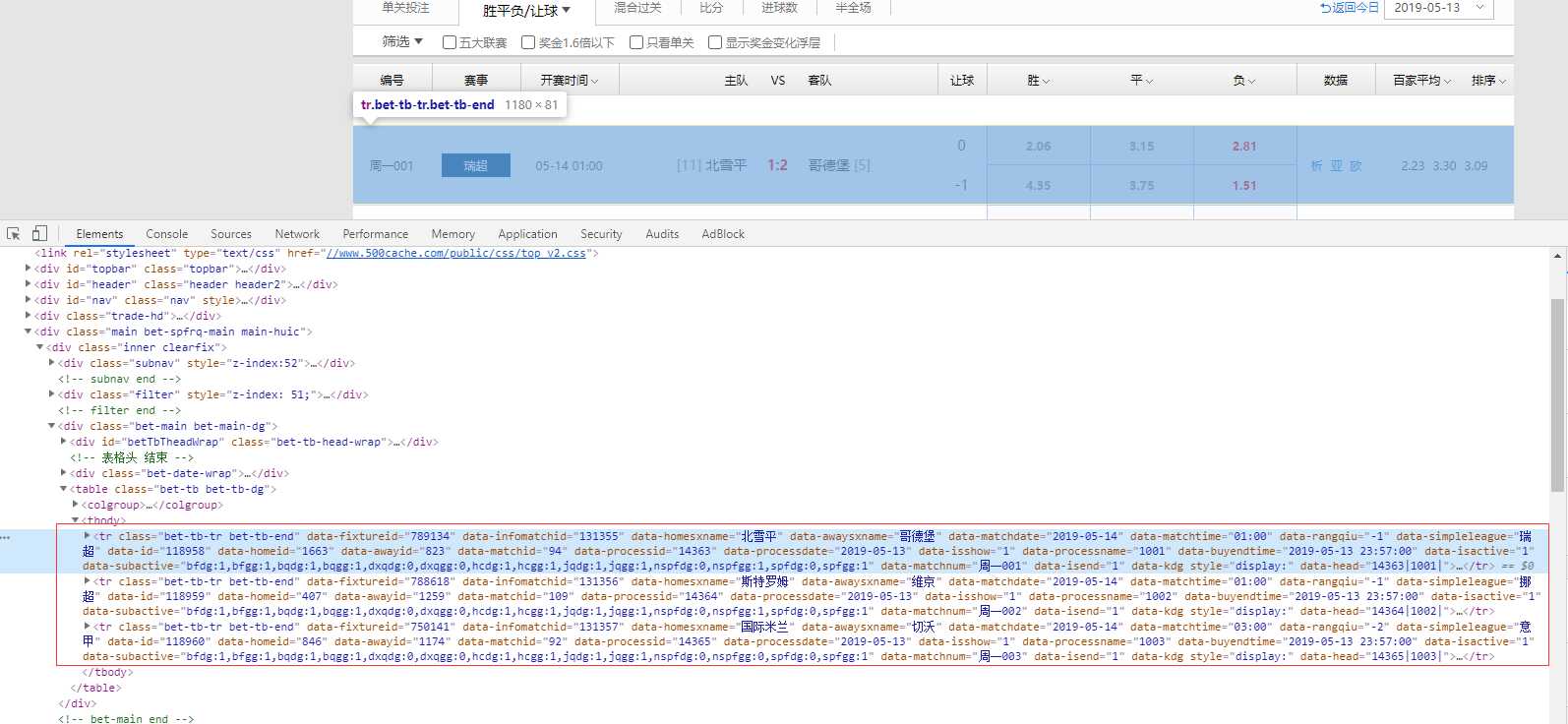
每一行都在一个tr中。这里我们就可以定位到tr,然后获取到所有的tr的值,然后在tr中循环找我们需要的信息

首先在 item.py中确定我们需要爬取的信息
class ZucaiItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
League = scrapy.Field() ---赛事
Time = scrapy.Field()--时间
Home_team = scrapy.Field()--主队
Away_team = scrapy.Field()--客队
Result = scrapy.Field()--赛果
Win = scrapy.Field()--赢的赔率
Level = scrapy.Field()--平局赔率
Negative = scrapy.Field()--负的赔率
pass
然后写zucai.py
def parse(self, response):
datas = response.xpath(‘//div[@class="bet-main bet-main-dg"]/table/tbody/tr‘)
for data in datas:
item = ZucaiItem()
item[‘League‘] = data.xpath(‘.//td[@class="td td-evt"]/a/text()‘).extract()[0]
item[‘Time‘] = data.xpath(‘.//td[@class="td td-endtime"]/text()‘).extract()[0]
item[‘Home_team‘] = data.xpath(‘.//span[@class="team-l"]/a/text()‘).extract()[0]
item[‘Result‘] = data.xpath(‘.//i[@class="team-vs team-bf"]/a/text()‘).extract()[0]
item[‘Away_team‘] = data.xpath(‘.//span[@class="team-r"]/a/text()‘).extract()[0]
item[‘Win‘] = data.xpath(‘.//div[@class="betbtn-row itm-rangB1"]/p[1]/span/text()‘).extract()[0]
item[‘Level‘] = data.xpath(‘.//div[@class="betbtn-row itm-rangB1"]/p[2]/span/text()‘).extract()[0]
item[‘Negative‘] = data.xpath(‘.//div[@class="betbtn-row itm-rangB1"]/p[3]/span/text()‘).extract()[0]
yield item
这里执行的时候有时会报超出数组范围的错误,则需要将对应的extract()[0]替换成extract_first()。后面再说这两者的区别
这里需要将获取的数据存入MySQL数据库
首先得在本地装一个MySQL数据库,然后建一个库和一个表。表的列和item.py中的相同。以便爬取的数据能顺利存入其中。
然后在pepelines.py中写存入数据库的代码
import pymysql
import logging
class ZucaiPipeline(object):
def __init__(self):
self.connect = pymysql.connect(host=‘localhost‘, user=‘root‘, password=‘123456‘, db=‘douban‘, port=3306)
self.cursor = self.connect.cursor()
def process_item(self, item, spider):
try:
sql = ‘insert into jcai values ("{}","{}","{}","{}","{}","{}","{}","{}")‘.format(item[‘League‘], item[‘Time‘], item[‘Home_team‘], item[‘Result‘], item[‘Away_team‘], item[‘Win‘], item[‘Level‘], item[‘Negative‘])
self.cursor.execute(sql)
self.connect.commit()
except Exception as error:
logging.log(error)
return item
def close_db(self):
self.cursor.close()
self.connect.close()
最后 修改setting.py中的信息
USER_AGENT = ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36‘
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
‘ZuCai.pipelines.ZucaiPipeline‘: 300,
}
修改这三处就可以了。
import scrapy
from ZuCai.items import ZucaiItem
class ZucaiSpider(scrapy.Spider):
name = ‘zucai‘
allowed_domains = [‘trade.500.com/jczq/‘]
start_urls = [‘https://trade.500.com/jczq/?date=2019-05-13‘]
def parse(self, response):
datas = response.xpath(‘//div[@class="bet-main bet-main-dg"]/table/tbody/tr‘)
for data in datas:
item = ZucaiItem()
item[‘League‘] = data.xpath(‘.//td[@class="td td-evt"]/a/text()‘).extract()[0]
item[‘Time‘] = data.xpath(‘.//td[@class="td td-endtime"]/text()‘).extract()[0]
item[‘Home_team‘] = data.xpath(‘.//span[@class="team-l"]/a/text()‘).extract()[0]
item[‘Result‘] = data.xpath(‘.//i[@class="team-vs team-bf"]/a/text()‘).extract()[0]
item[‘Away_team‘] = data.xpath(‘.//span[@class="team-r"]/a/text()‘).extract()[0]
item[‘Win‘] = data.xpath(‘.//div[@class="betbtn-row itm-rangB1"]/p[1]/span/text()‘).extract()[0]
item[‘Level‘] = data.xpath(‘.//div[@class="betbtn-row itm-rangB1"]/p[2]/span/text()‘).extract()[0]
item[‘Negative‘] = data.xpath(‘.//div[@class="betbtn-row itm-rangB1"]/p[3]/span/text()‘).extract()[0]
yield item
至此爬取一个页面的赛果信息就完成了。
然后 cd zucai
scrapy crawl zucai 执行。就会发现数据库对应的表中有数据。
爬取竞彩足球的数据信息
标签:修改 cursor result 的区别 nes fine win domain path
原文地址:https://www.cnblogs.com/zc-cong/p/10861440.html