标签:protected 序列化 vat ext private 情况 EDA his cte
做demo前需要先搭建Hadoop集群,并且有linux基础,可参考 https://www.cnblogs.com/linyufeng/p/10831240.html
1.引出问题
给一串数据,找出每年的每个月温度最高的2天。其中有可能包含着相同的数据。
1949-10-01 14:21:02 34c 1949-10-01 19:21:02 38c 1949-10-02 14:01:02 36c 1950-01-01 11:21:02 32c 1950-10-01 12:21:02 37c 1951-12-01 12:21:02 23c 1950-10-02 12:21:02 41c 1950-10-03 12:21:02 27c 1951-07-01 12:21:02 45c 1951-07-02 12:21:02 46c 1951-07-03 12:21:03 47c 1949-10-01 14:21:02 34c 1949-10-01 19:21:02 38c 1949-10-02 14:01:02 36c 1950-01-01 11:21:02 32c 1950-10-01 12:21:02 37c 1951-12-01 12:21:02 23c
2.分析
从肉眼去看,这么几条数据,人工也能很快的得出结果,但如果有几百万条呢?所以采用hadoop的mapReduce框架,mapReduce是一个分布式的离线计算框架,流程分为4步骤split---map---shuffle---reduce。用mapReduce去处理这些数据。处理天气数据所需要使用到的有年和月还有温度,最后输出则是要对应相对应的日。所以创建一个天气类。并且实现writableComparable接口,实现其未实现方法。
package com.sjt.mr.tq.demo; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.WritableComparable; public class MyTQ implements WritableComparable<MyTQ>{ private int year;//年 private int month;//月 private int day;//日 private int wd;//温度 public int getYear() { return year; } public void setYear(int year) { this.year = year; } public int getMonth() { return month; } public void setMonth(int month) { this.month = month; } public int getDay() { return day; } public void setDay(int day) { this.day = day; } public int getWd() { return wd; } public void setWd(int wd) { this.wd = wd; } @Override public void write(DataOutput out) throws IOException { out.writeInt(year); out.writeInt(month); out.writeInt(day); out.writeInt(wd); } @Override public void readFields(DataInput in) throws IOException { year = in.readInt(); month = in.readInt(); day = in.readInt(); wd = in.readInt(); } @Override public int compareTo(MyTQ mytq) { //1980-05-02 34c //比较年是否相同 int c1 = Integer.compare(year, mytq.getYear()); if(c1==0){ //如果相同则比较月份 int c2 = Integer.compare(month, mytq.getMonth()); if(c2==0){ //如果月份相同则比较温度,使得温度降序排序 return -Integer.compare(wd, mytq.getWd()); } return c2; } return c1; } }
3.Map阶段
在map的读入阶段,需要把从split中读取的数据做切割处理,并且让对象进行序列化存入磁盘中。
package com.sjt.mr.tq.demo; import java.io.IOException; import java.text.ParseException; import java.text.SimpleDateFormat; import java.util.Calendar; import java.util.Date; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class MyMapper extends Mapper<Object, Text, MyTQ, IntWritable>{ private MyTQ tqKey=new MyTQ(); private IntWritable Tvalue=new IntWritable(); //key记录的是偏移量,value为一行的数据 @Override protected void map(Object key, Text value, Mapper<Object, Text, MyTQ, IntWritable>.Context context) throws IOException, InterruptedException { try { //1980-01-02 18:15:45 34c //根据制表符分割 获得 split[0]=1980-01-02 18:15:45 split[1]=34c String[] splits =value.toString().split("\t"); //设值key SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd"); Date date = sdf.parse(splits[0]); Calendar calendar = Calendar.getInstance(); calendar.setTime(date); //给tqkey设值 tqKey.setYear(calendar.get(calendar.YEAR)); tqKey.setMonth(calendar.get(calendar.MONTH)+1); tqKey.setDay(calendar.get(calendar.DAY_OF_MONTH)); int wd = Integer.parseInt(splits[1].substring(0, splits[1].length()-1)); tqKey.setWd(wd); //设值温度 Tvalue.set(wd); } catch (ParseException e) { // TODO Auto-generated catch block e.printStackTrace(); } context.write(tqKey, Tvalue); } }
4.分组比较器
调用天气对象的分组比较器会造成一条数据一组的现象,因为条件多了一个天气,所以需要自定义分组比较器。
package com.sjt.mr.tq.demo; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; //分组比较 public class MyGroupComparator extends WritableComparator{ //调用父类的构造方法 public MyGroupComparator(){ super(MyTQ.class,true); } @Override public int compare(WritableComparable a, WritableComparable b) { MyTQ tq1=(MyTQ)a; MyTQ tq2=(MyTQ)b; //先比较年 再比较月 int c1 = Integer.compare(tq1.getYear(), tq2.getYear()); if(c1==0){ return Integer.compare(tq1.getMonth(), tq2.getMonth()); } return c1; } }
5.Reduce阶段
reduce阶段需要对数据进行最后的处理,根据前面的排序只需要取出当前所得结果的前两行就是该年某月中的温度最高的两天,当然也不排除当前数据中只有一条数据是该年某月的,而且还要判断是否存在相同的天的温度是否处于前两行。
package com.sjt.mr.tq.demo; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class MyReduce extends Reducer<MyTQ, IntWritable,Text,IntWritable>{ private Text key=new Text(); private IntWritable value=new IntWritable(); @Override protected void reduce(MyTQ mytq, Iterable<IntWritable> values, Reducer<MyTQ, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { int flag=0;//计数 int day=0;//储存日期 for (IntWritable v : values) { //如果计算为0取第一位的年月日:温度 if(flag==0){ //设key和value值 key.set(mytq.getYear()+"-"+mytq.getMonth()+"-"+mytq.getDay()+":"); value.set(mytq.getWd()); //给day设值 防止重复天数 day=mytq.getDay(); flag++;//计数+1 context.write(key, value); } //如果计数为1且日期不和第一次写出的日期不一致 if(flag!=0&&mytq.getDay()!=day){ key.set(mytq.getYear()+"-"+mytq.getMonth()+"-"+mytq.getDay()+":"); value.set(mytq.getWd()); context.write(key, value); break; } } } }
6.打包运行
部分代码省略,可再文章最后查看到项目源代码及数据处理文件。
并且将打包后的jar包丢入集群,将需要处理的文本储存到hdfs上,命令为:

执行下行命令运行:分析tq.txt文件 MyJob为入口,结果放入output目录下

如果不报错,并且再hdfs的output的目录下出现了下图中的情况说明你成功了。可以对part-r-00000进行下载。
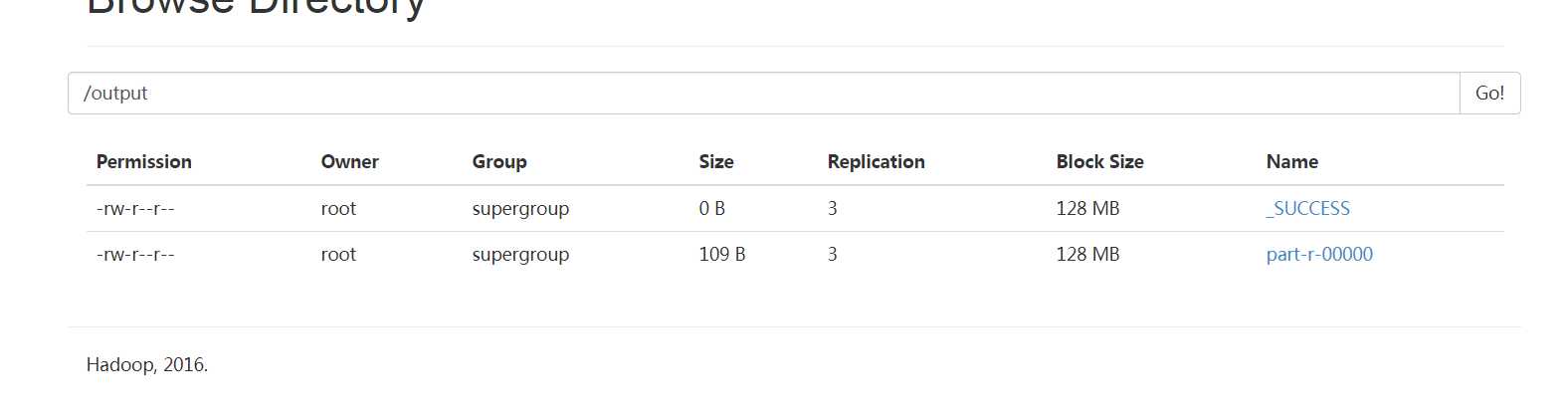
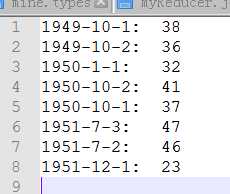
下载的结果如果为下图,则代表运行代码正确。
项目源代码及文件路径 https://github.com/shijintao123/Hadoop
编译报错参考:https://blog.csdn.net/qq_42476731/article/details/90298983
标签:protected 序列化 vat ext private 情况 EDA his cte
原文地址:https://www.cnblogs.com/mangshebaotang/p/10894410.html