标签:mysql 存储 roo 变量 null hadoop def 编辑 www.
hive1.2.2下载:http://mirror.bit.edu.cn/apache/hive/hive-1.2.2/apache-hive-1.2.2-bin.tar.gz
mysql-connect.jar:https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.46.zip
安装连接:https://www.cnblogs.com/tashanzhishi/p/10006705.html
tar -zxvf apache-hive-1.2.1-bin.tar.gz # 我这里的是hive1.2.1,如从上面连接下载,改为1.2.2即可
下图是解压目录:
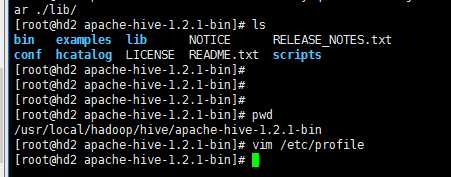
下面的配置主要是针对元数据的配置:若要配置其他信息可以参考:
vim /usr/local/hadoop/hive/apache-hive-1.2.1-bin/conf/hive-site.xml
<configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>qwe123</value> <description>password to use against metastore database</description> </property> </configuration>
配置完毕后对环境变量进行配置:
vim /etc/profile
添加如下图:
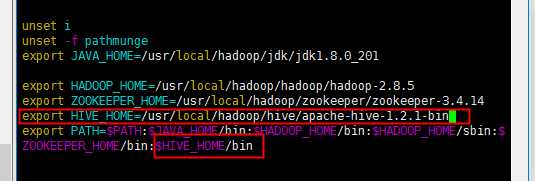
然后重新加载一下环境变量:
该jar包主要是为了hive连接mysql如下:
启动须知:使用hive前,需要将HDFS和YARN进行启动,再使用HIVE.
start-dfs.sh start-yarn.sh
[root@hd2 ~]#hive hive>
下图为实例:

若在启动时出现如下情况:
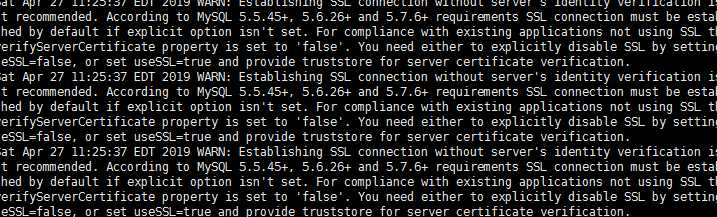
可以在配置文件中添加如下配置:
可以设置一些基本参数,让hive使用起来更便捷,比如:
1、让提示符显示当前库:
hive>set hive.cli.print.current.db=true;
2、显示查询结果时显示字段名称:
hive>set hive.cli.print.header=true;
但是这样设置只对当前会话有效,重启hive会话后就失效,解决办法:
在linux的当前用户目录中,编辑一个.hiverc文件,将参数写入其中:
vi .hiverc
set hive.cli.print.header=true; set hive.cli.print.current.db=true;
下面是启动hive服务,并且在后台运行:
nohup bin/hiveserver2 1>/dev/null 2>&1 &
启动成功后,可以在别的节点上用beeline去连接:
[root@hd2 ~]# beeline beeline> !connect jdbc:hive2://localhost:10000 -n root # -n root 表示root用户无需验证密码,可以不带该参数,后面就会输入密码
如下实例:
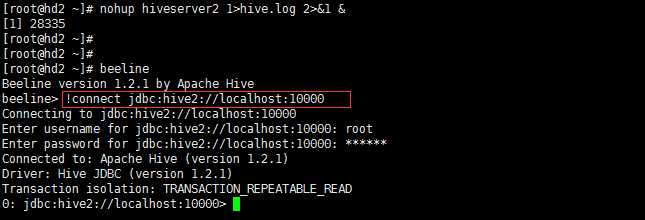
测试使用:
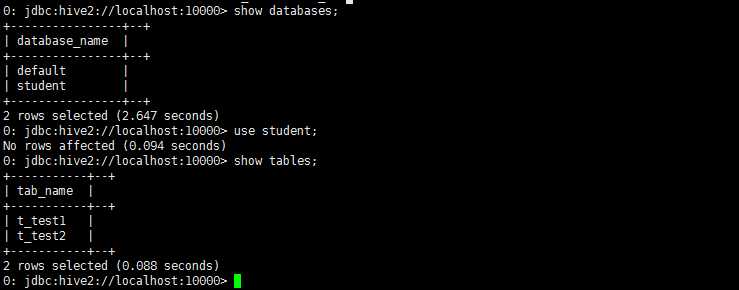
大量的hive查询任务,如果用交互式shell来进行输入的话,显然效率及其低下,因此,生产中更多的是使用脚本化运行机制:
该机制的核心点是:hive可以用一次性命令的方式来执行给定的hql语句
[root@hd2 ~]# hive -e "use student; select * from t_test2;"
下面是实例:
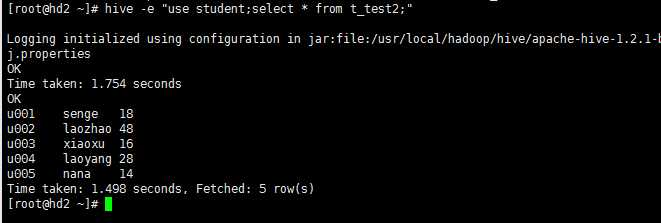
然后,进一步,可以将上述命令写入shell脚本中,以便于脚本化运行hive任务,并控制、调度众多hive任务,示例如下:
[root@hd2 ~] vi t_order_etl.sh
代码如下:
#!/bin/bash hive -e "select * from db_order.t_order" hive -e "select * from default.t_user" hql="create table default.t_bash as select * from db_order.t_order" hive -e "$hql"
可以直接用:
[root@hd2 ~] sh t_order_et1.sh
这里会简单介绍hive中创建的表在HDFS中存储的位置,因为牵扯到内部表和外部表,会在后面的章节中进行详细的阐述。
在hive创建的数据库,会默认的在hdfs的:/user/hive/warehouse/数据库/表,改目录可以自行配置
如下两图所示:
创建t_test2的表:

在HDFS中,会在响应的地方创建文件夹,如下图:
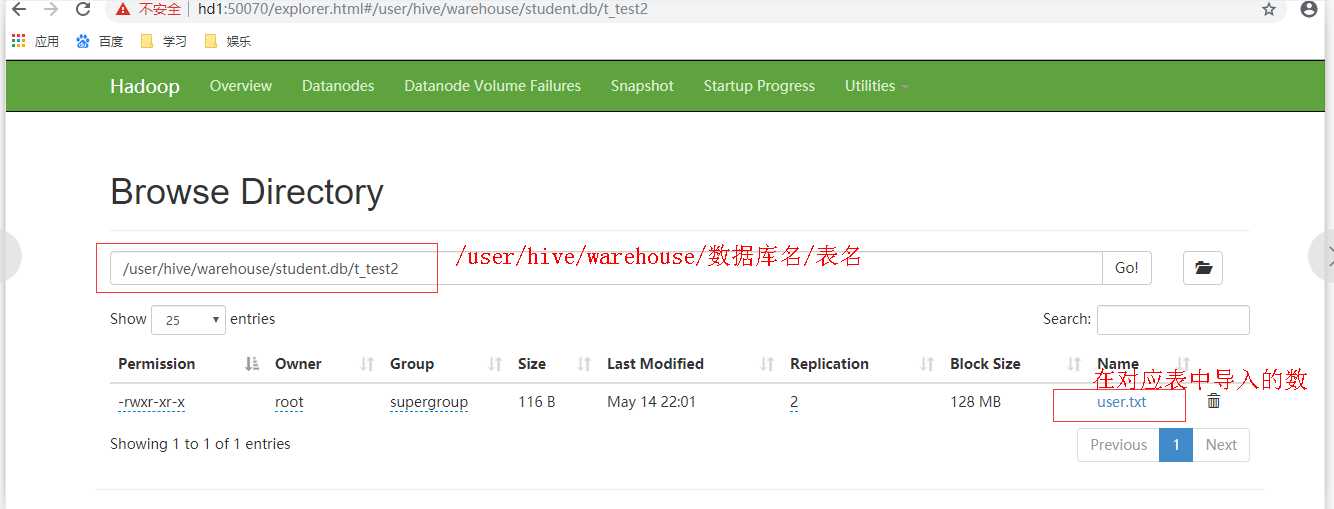
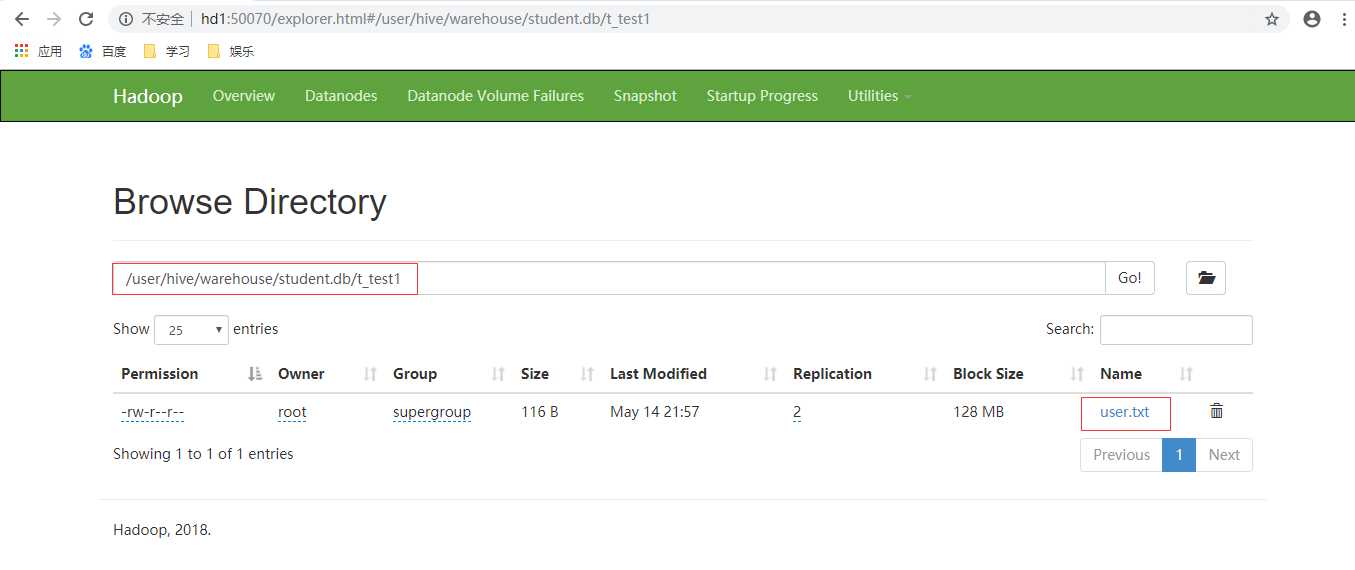
上面的图已经导入了数据:导入数据有两种方式,直接在shell中hdfs命令导入到对应的文件目录,如下:

导入结果如下:
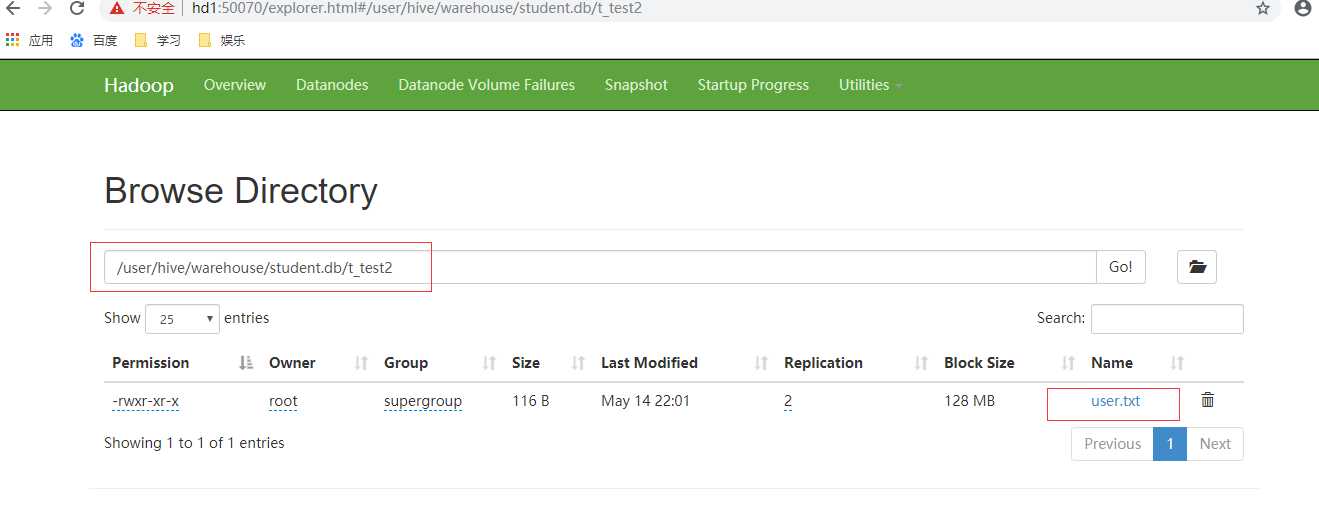
方式二:在hive的命令行中进行数据导入:

导入结果如下:
标签:mysql 存储 roo 变量 null hadoop def 编辑 www.
原文地址:https://www.cnblogs.com/tashanzhishi/p/10863060.html