标签:conf 创建用户 server app 直接 out 临时 help xml配置
1、什么是快照?
快照就是对当前的虚拟机状态进行拍照,保留虚拟机当前状态的操作信息。
2、为什么要为虚拟机做快照?
第一:为克隆不同状态的虚拟机提前做准备。
第二:当对虚拟机的某些操作执行错误而且改正比较麻烦的时候,可以切换到之前正常的虚拟机状态重新进行相关的操作。
3、如何为虚拟机做快照?
(1)选择要克隆的虚拟机,然后“右键”,选择“快照”,然后选择“拍摄快照”。
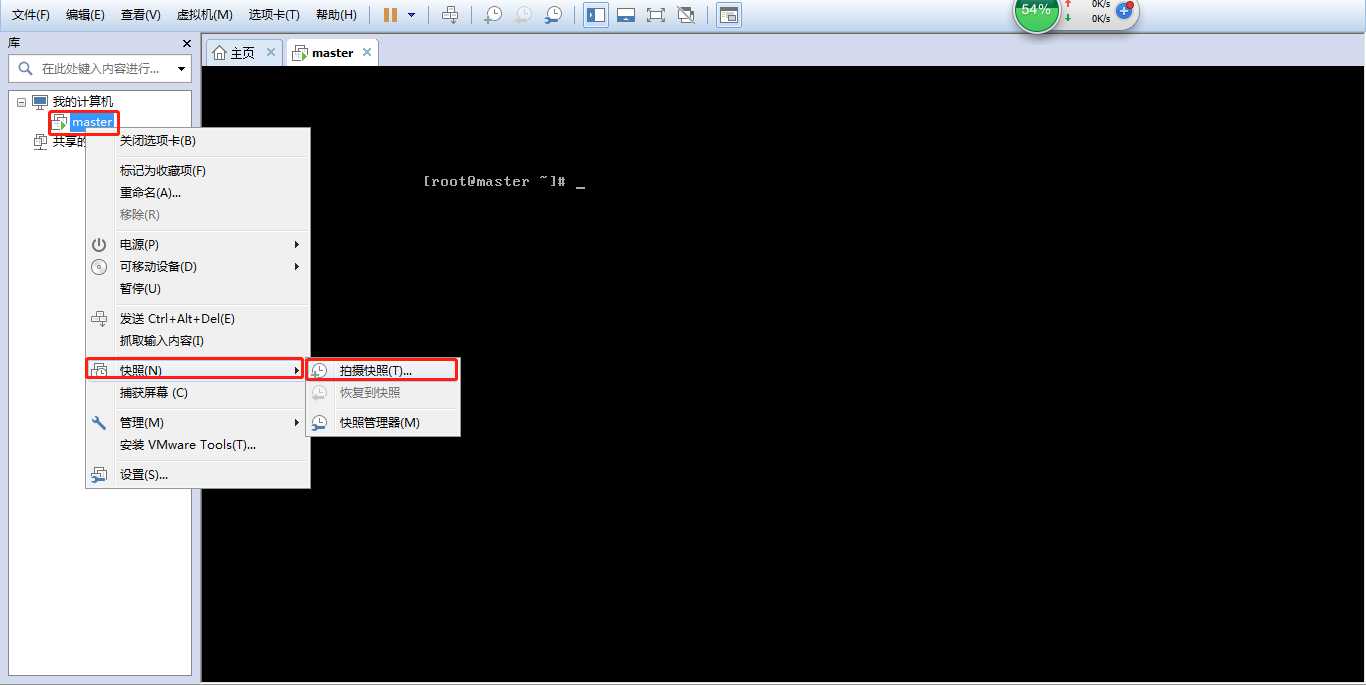
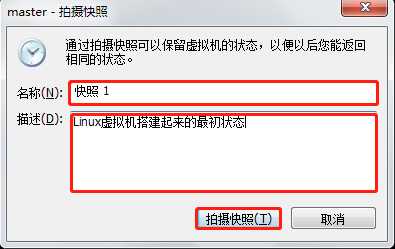
(2)可以为快照取个名称,也可以为虚拟机当前的状态做个描述,然后点击“拍摄快照”。
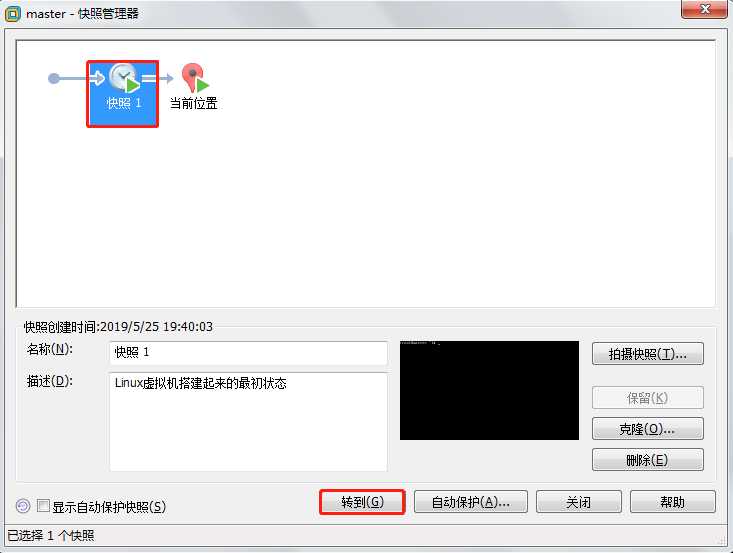
4、如何转到某一特定状态的快照?
(1)选择对应状态的快照,然后点击“转到”。
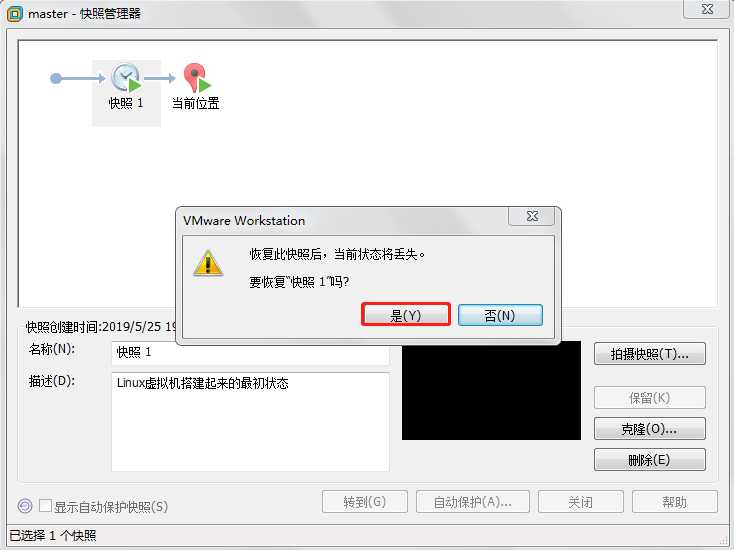
(2)然后在接下来的弹框中点击“是”即可。这样简单操作之后,虚拟机就实现了快照状态的一个转换。
1、打开并登陆虚拟机
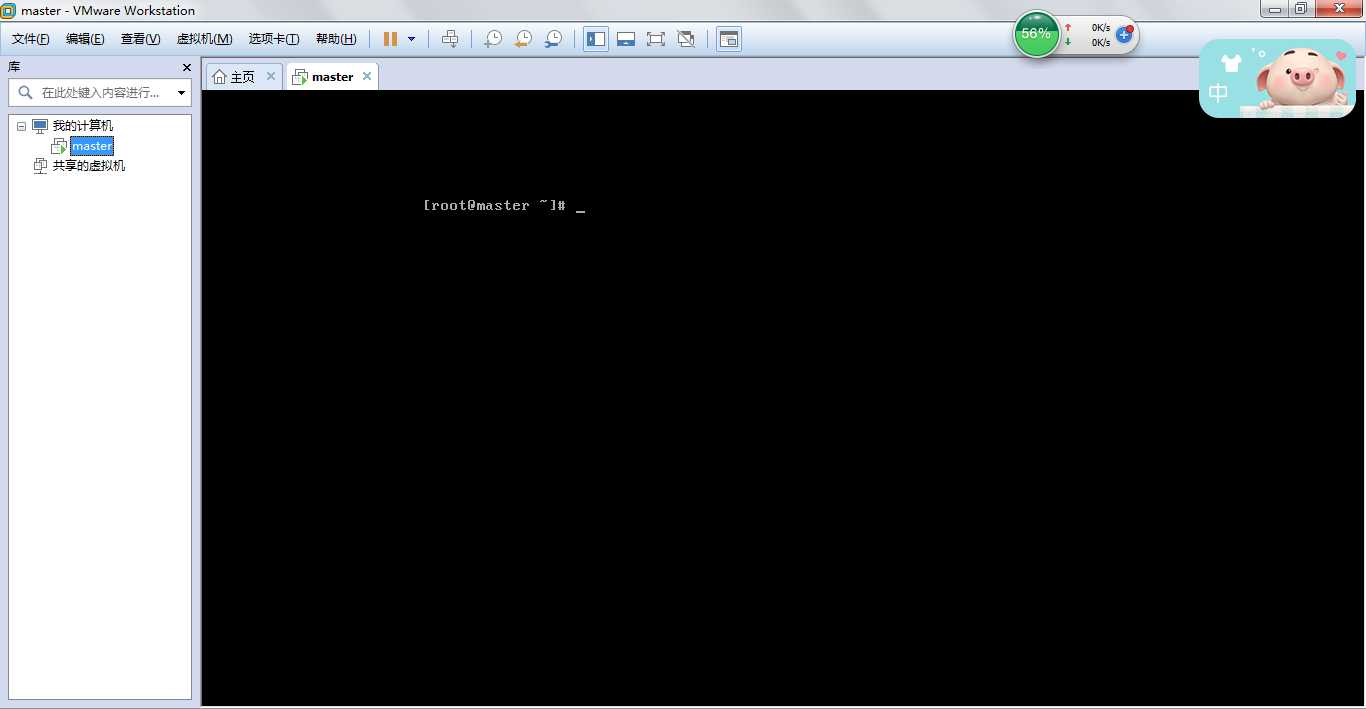
2、用ifconfig命令来查看网络接口配置信息,此时只能查到回环地址127.0.0.1和子网掩码255.0.0.0。
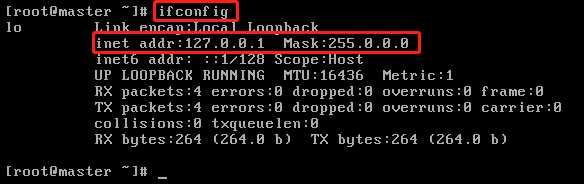
3、做3个小测试
(1)ping 127.0.0.1(回环地址),如果能ping通,就说明虚拟机的网络协议是正常的(一般也是能ping通的)。注意:ping通之后同时按“Ctrl” 和“C”即可断开连接。
(2)ping 网关
1)这里面就牵涉到一个问题:我的网关是多少?在哪里看?
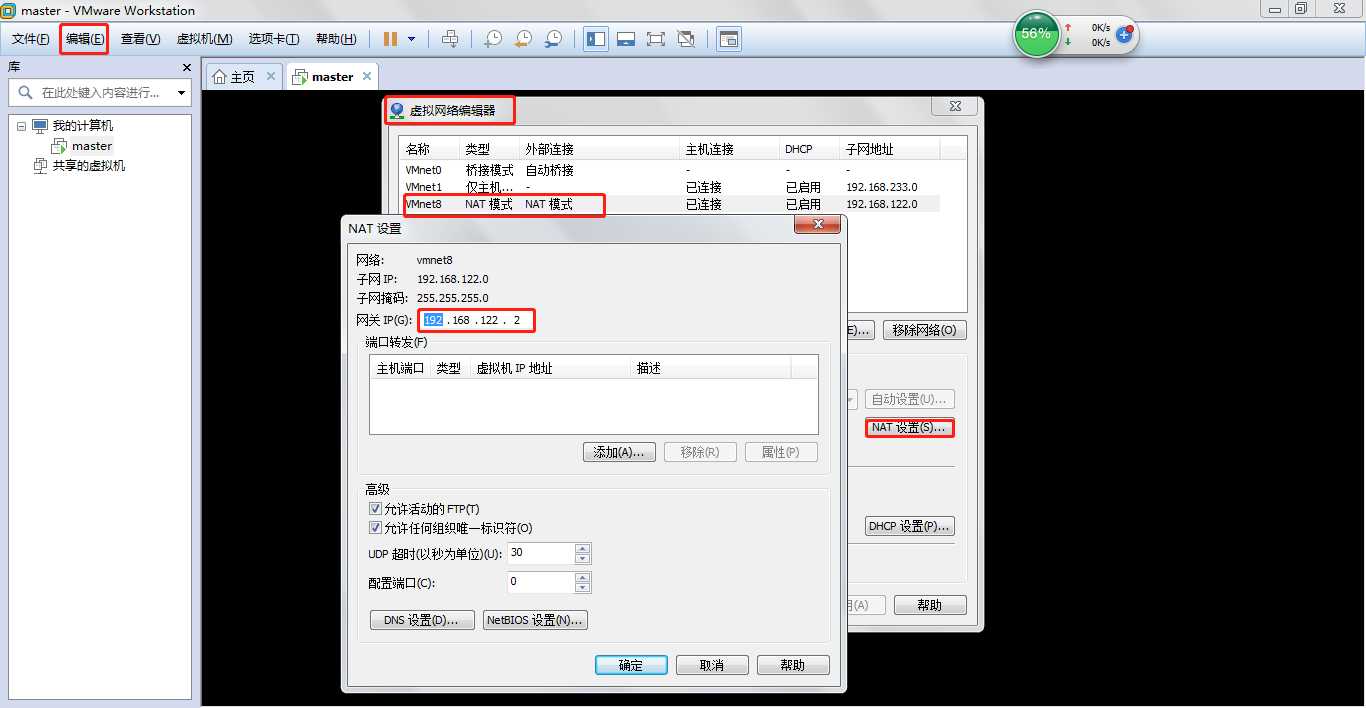
2)找到网关地址之后,然后开始ping网关。

一般第一次是ping不通的,那就说明我们的网卡链路是有问题的,所以我们需要查看网卡,找出问题的原因。那么这就又有两个问题:
第一,在哪里查看网卡信息?
我们输入如下命令:vi /etc/sysconfig/network-scripts/ifcfg-eth0 即编辑/etc/sysconfig/network-scripts/目录下的ifcfg-eth0文件(可以使用Tab键)
第二,该如何配置网卡?
进入文件之后,首先输入“i”进入文件编辑模式,然后把ONBOOT=no修改为yes,然后按”Esc”键退出编辑模式,再接下来按“:wq”保存退出即可。
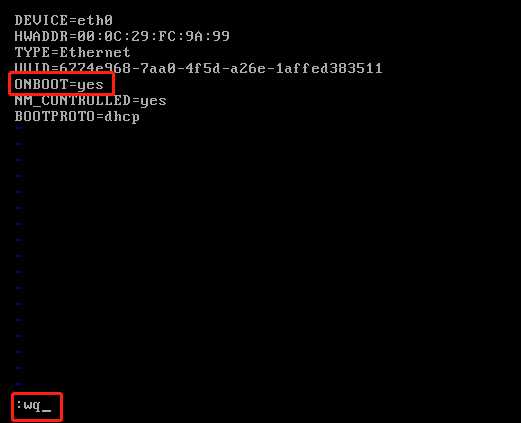
为什么要修改呢?ONBOOT=no表示什么意思呢?
实质上ONBOOT=no表示我们的网卡没有开启,所以我们要将no改为yes,来开启网卡。
3)重启网络服务
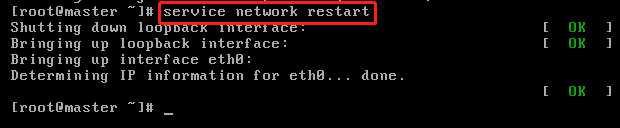
OK,刚才我们修改了网卡的配置,所以这个时候我们需要重启网络服务。切记,每次修改网卡之后都需要重启网络服务,这样修改的配置才能生效。
如何重启网络服务呢?我们需要输入命令service network restart即可。重启成功的标志如下图。
下面我们再来ping一下网关,你会发现,已经能够成功的ping通网关了。
(3)ping IP地址
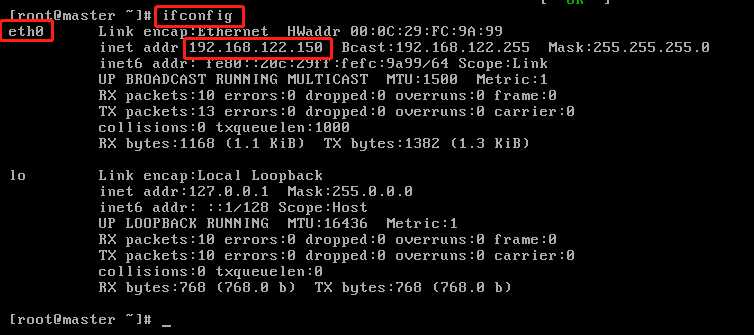
1)我们继续输入ifconfig命令查看一下网络接口配置信息,我们发现多了一个eth0的网卡,而且可以看到ip地址。
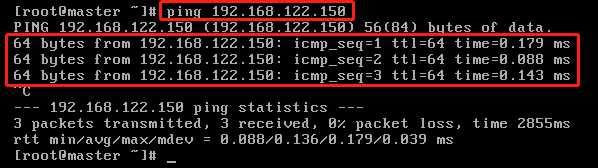
2)然后我们ping IP地址,如果能ping通,说明我们的本机网卡链路没有问题。我们发现是可以ping通的,如下图所示。
(4)ping外网
我们输入命令ping www.baidu.com来检查一下虚拟机和外部网络的连通性,如果能够ping通,就说明我们的虚拟机已经和互联网打通了。
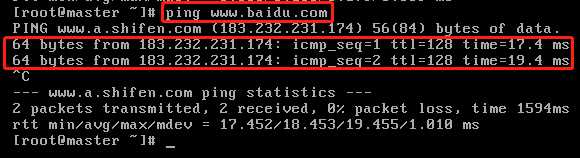
在实际应用中,由于我们使用的是DHCP(Dynamic Host Configuration Protocol:动态主机配置协议)服务器来分配的地址,那么每次重启DHCP服务器ip地址有可能是会变动的。 而我们用Linux来搭建集群学习Hadoop的话,是希望IP固定不变的,因为有很多地方会涉及到IP地址的配置,如果IP地址变化就会涉及到很多相关地方的修改,所以我们需要配置静态IP,那么具体如何进行配置呢?
(1)在哪里配置?
输入命令vi /etc/sysconfig/network-scripts/ifcfg-eth0
(2)如何配置?
具体配置如下图所示:
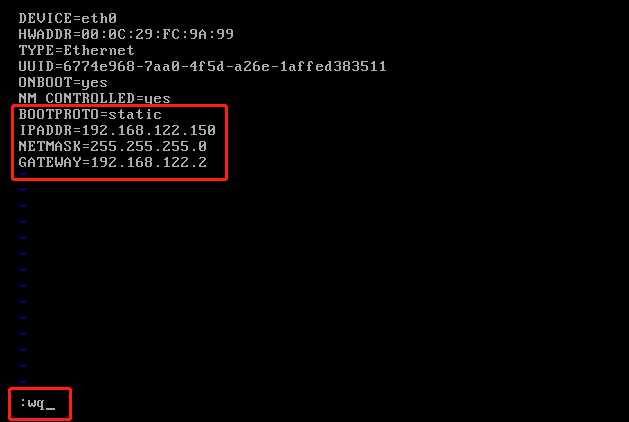
其中配置的属性和值的注释如下:
BOOTPROTO=static //把dhcp修改为static
IPADDR=192.168.122.150 //可以自己设置,但必须与GATEWAY网段一致,比如122
NETMASK=255.255.255.0 //默认设置
GATEWAY=192.168.122.2 //网关地址
(3)修改完之后需要重启网络服务,即输入命令service network restart

(4)重启成功之后,继续输入ifconfig查看一下ip,这个时候ip地址就固定了。
1、为什么要进行用户组和用户的设置?
默认只有一个root超级用户,它的权限是很大的,如果误删文件,整个系统的使用可能就会出现问题,存在很大的安全性问题,所以,我们需要单独创建用户,然后在该用户上进行相关的操作。(可能会出现一个问题,某些操作权限不够,只需要配置sudo权限或切换到root用户下执行即可)
2、如何创建用户组和用户?
(1)创建用户组:groupadd
比如创建hadoop用户组:groupadd hadoop
(2)创建用户:useradd
比如创建hadoop用户:useradd hadoop
注意:1)默认创建用户的时候会同时创建一个同名的用户组,前边是用户,后边是用户组。

2)在任何目录下执行该命令都可以,最后创建的这个用户的目录是在home目录下,也就是说指不指定-m参数效果都一样。
(3)查看帮助信息:
useradd --help
一般情况下,哪个命令不知道怎么用,不知道使用哪个参数,就用“命令 --help”
(4)切换用户:su
比如切换到hadoop用户:su hadoop
注意:root用户向其他用户切换的时候不需要输入密码,但是其他用户向root用户切换或其他用户之间在切换的时候是需要输入密码,所以需要为用户设置密码。
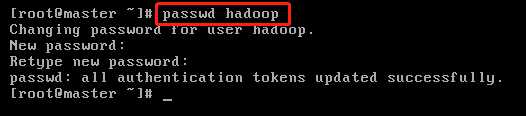
(5)为用户设置密码:passwd
比如为hadoop用户设置密码:passwd hadoop,然后按回车输入两次密码即可,”password --help”查看该命令用法。
1、为什么要为用户设置sudo权限?
用户在执行某些系统命令时会出现用户权限不够的问题,需要切换到root用户下执行,频繁的切换会很麻烦,而且也很容易导致权限问题。所以最好为用户配置sudo权限。所有的操作都可以在该用户下操作,出现权限不够的问题只需要在命令前边加上sudo即可。
2、如何为用户设置sudo权限?
首先要明确是为哪个用户设置sudo权限。比如为hadoop用户设置sudo权限。
(1) 在root用户下,输入visudo即可。
(2) 在打开的文件末尾添加“hadoop ALL=(ALL) NOPASSWD:ALL”即可。
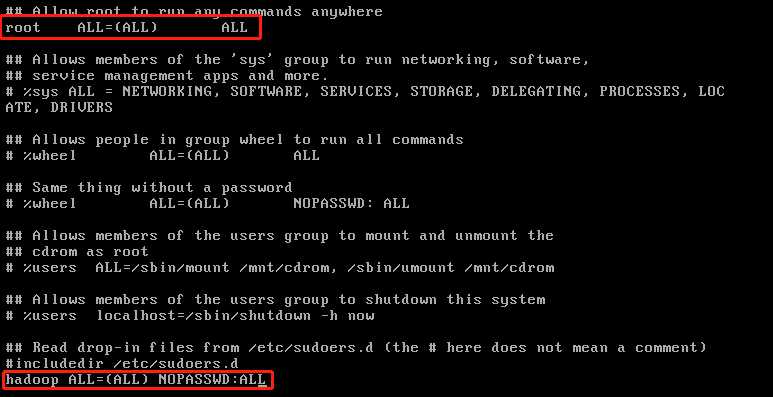
(3) 验证sudo权限是否配置成功
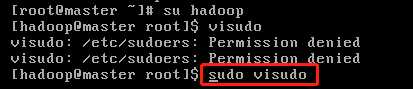
这样特定用户的sudo权限就配置成功了,接下来就可以正常使用sudo命令了。
由于直接在Linux虚拟机上操作比较不方便,所以我们选择使用第三方远程连接工具X-shell远程连接到Linux虚拟机,然后通过X-shell对Linux虚拟机进行相关操作。
1、 如何实现X-Shell和Linux虚拟机的远程连接?
(1) 安装X-Shell远程连接工具
(2) 实现X-Shell和Linux虚拟机的远程连接
1) 首先打开X-Shell工具,然后在X-Shell和Linux虚拟机之间新建一个会话并做如下配置。
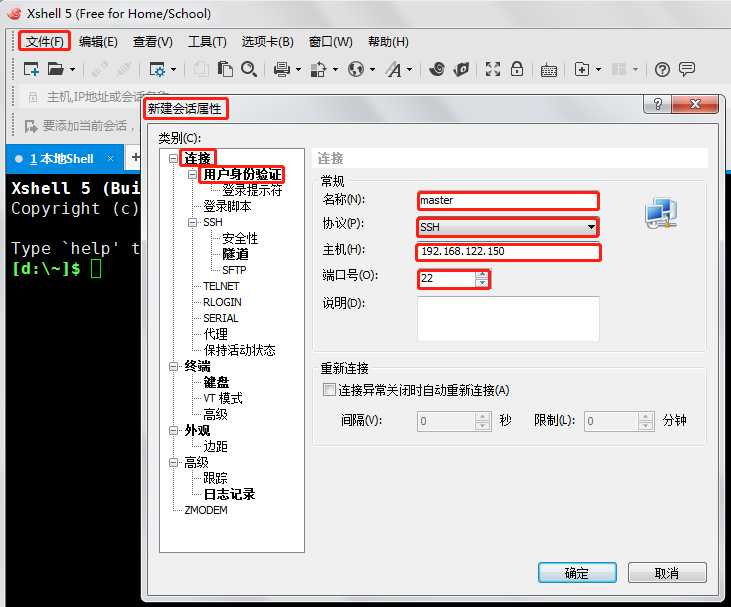
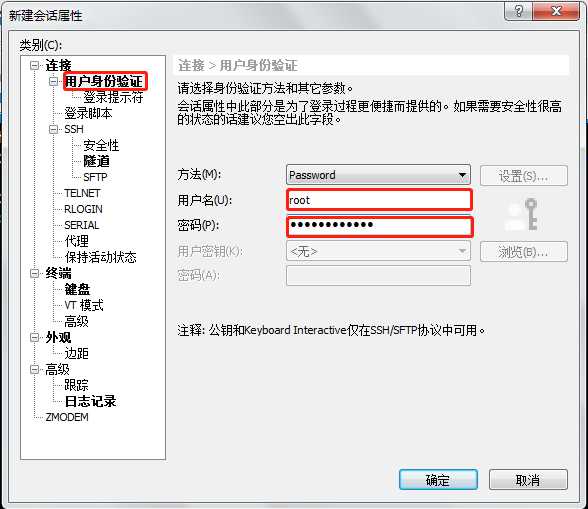
2) 配置完成之后点击“用户身份验证”,进行用户名和密码的配置。然后点击“确定”。配置成功之后再用X-Shell连接远程虚拟机,就不用输入用户名和密码了。
3) 选择对应的对话连接即可。
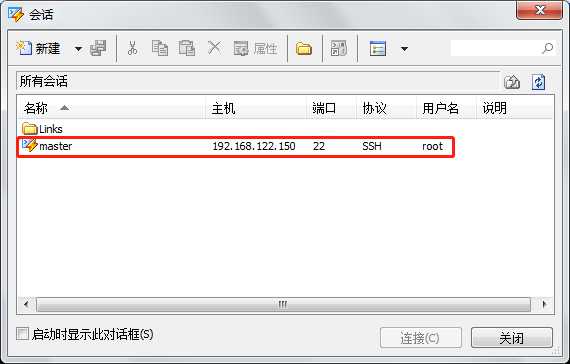
4)连接结果如下所示。这样就实现了X-Shell和远程虚拟机的连接。接下来就可以在X-Shell上进行相关的操作,实际上还是在Linux虚拟机上执行的操作。
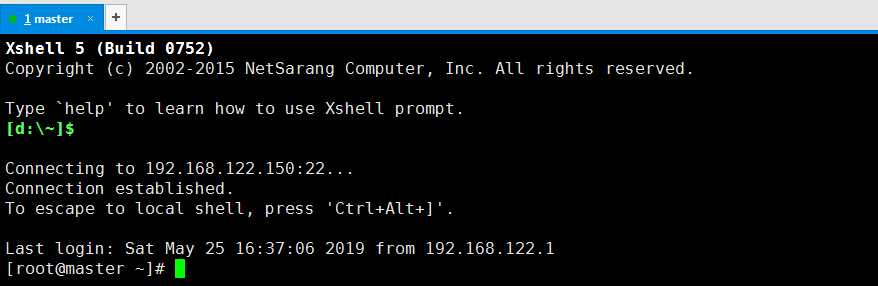
1、如何查看主机名?
(1)直接通过命令提示符即可看出主机名。

(2)通过hostname命令也可显示主机名。

2、如何修改主机名?
(1)临时性修改
执行命令hostname 主机名(要修改的主机名)
比如hostname test

注意:临时性修改的方法当虚拟机重启的时候就不生效了,而且不会改变命令提示符中的主机名,所以为临时性修改。
(2)永久性修改
我们输入命令vi /etc/sysconfig/network,然后在该文件中修改即可。
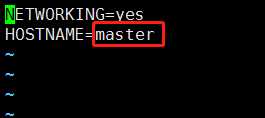
注意:修改完之后不会立即显示出修改后的结果,我们需要输入reboot命令重启linux操作系统,重启之后,我们才能看到修改后的结果。
1、防火墙是干什么的?为什么要关闭防火墙?
防火墙是对我们的服务器进行的一种保护,但是有时候也会妨碍集群间的相互通讯,所以为了不影响集群间的通信我们可以关闭掉防火墙。
2、怎么关闭防火墙?
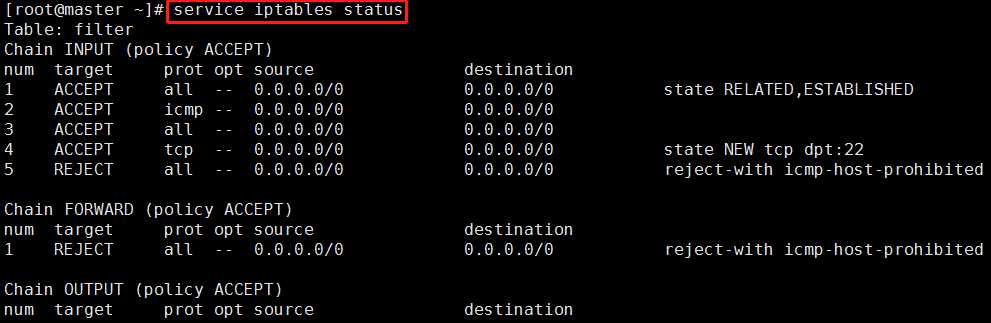
(1)首先查看防火墙状态
当出现如下信息时就表明防火墙是开启的状态。
service iptables status
(2)关闭防火墙的两种方法:
1)临时性关闭
service iptables stop
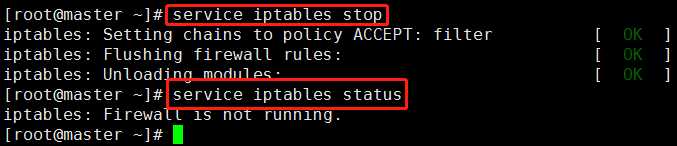
注意:临时性关闭防火墙的效果和临时性修改主机名的效果一样,当重启linux虚拟机之后就不起作用了。
2)永久性关闭
chkconfig iptables off
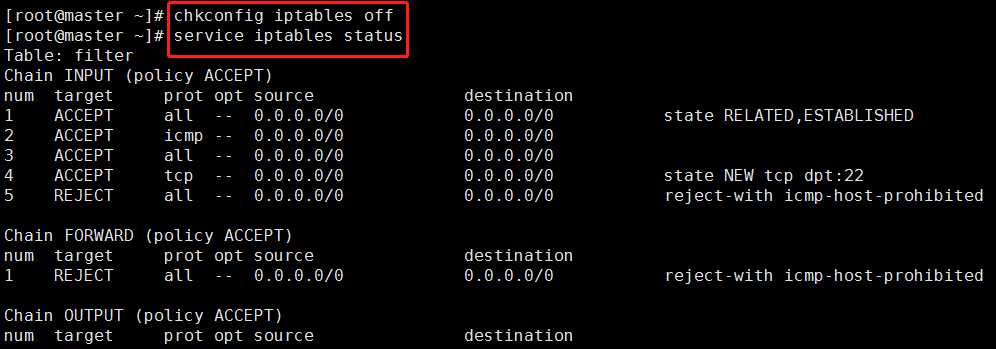
注意:永久性关闭防火墙之后,需要重新启动linux操作系统,即输入reboot命令才能生效。
1、lrzsz传输包
(1)为什么要安装lrzsz安装包?
lrzsz传输包主要用于文件的上传和下载,rz表示上传,sz表示下载,由于在集群搭建过程中需要对一些文件进行上传或下载,所以需要首先安装lrzsz传输包。
(2)怎么安装lrzsz安装包?
在root用户下,输入yum install lrzsz即可。这里我们采用的是yum的安装方式,因为这种方式可以把依赖的软件一起安装好。

2、安装openssh-clients服务
(1)为什么要安装openssh-clients服务?
做免密码登录的时候需要用到这个服务
(2)怎么安装openssh-clients服务?
输入命令 yum install -y openssh-clients
(-y表示在下载安装过程中全部输入yes或y)

(3)安装完成之后,可以输入命令ssh,按回车,如果能查看到ssh的用法即表示安装成功。
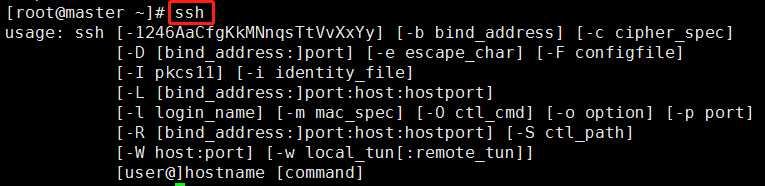
1、在哪配置?
vi /etc/hosts

2、如何配置?
参照该文件中的提示信息来配置
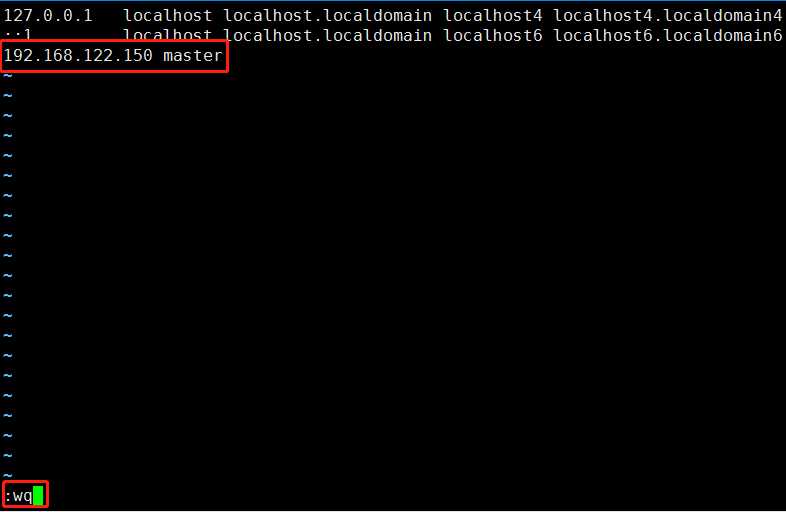
解释如下:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4是什么意思
第一部分:网络IP地址。
第二部分:对应的主机名
第三部份:主机名.域名,注意主机名和域名之间有个半角的点。
第四部份:主机名别名,其实还是主机名。
第五部份:主机名别名.域名,注意主机名和域名之间有个半角的点。
IP地址后是主机名或主机名列表,主机名列表中第一个为主机名,其他为主机名别名,主机名别名可以有多个。
主机域名用 ”主机名.域名“来表示。
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
::1想当于IPv6的locahost对应的IP地址,类似于IPv4的127.0.0.1
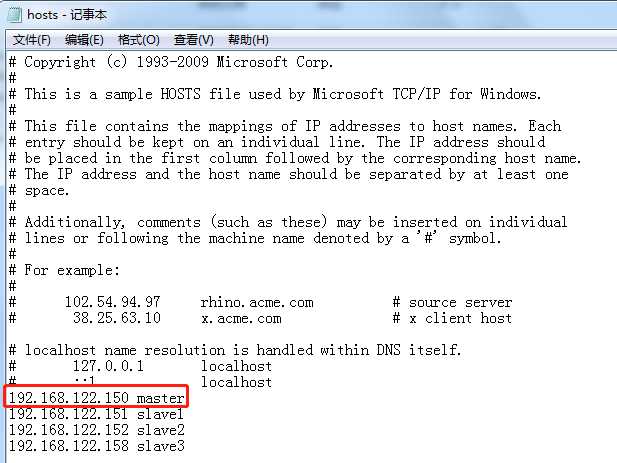
参照上边的格式在文件末行添加ip和hostname
比如:192.168.122.150 master即可。
如果还需要配置其他主机名和IP之间的对应关系,只需要按照上面的格式逐行配置即可。
1、SSH是什么?为什么要配置ssh免密码登录?
SSH是一个可以在应用程序中提供安全通信的一个协议,通过SSH可以安全地进行网络数据传输,它的主要原理就是利用非对称加密体系,对所有待传输的数据进行加密,保证数据在传输时不被恶意破坏、泄露或者篡改。但是hadoop使用ssh主要不是用来进行数据传输的,hadoop主要是在启动和停止的时候需要主节点通过SSH协议将从节点上面的进程启动或停止。也就是说如果不配置SSH免密码登录对hadoop的正常使用也没有任何影响,只是在启动和停止hadoop的时候需要输入每个从节点的用户名的密码就可以了,但是我们可以想象一下,当集群规模比较大的时候,比如上百台,如果每次都要输入每个从节点的密码,那肯定是比较麻烦点,所以这种方法肯定是不可取的,所以我们要进行SSH免密码的配置,而且目前远程管理环境中最常使用的也是SSH(Secure Shell)。
2、如何配置ssh免密码登录?
首先要明确是为哪个用户创建免密码登录,比如我们为hadoop用户创建SSH免密码登录。
1)在hadoop用户下,切换到hadoop用户的家目录(即/home/hadoop目录)。
2)创建.ssh目录:输入mkdir .ssh命令(其实不用提前创建该目录也行,直接在hadoop用户下执行生成秘钥的命令之后,系统会自动在hadoop的家目录下(/home/hadoop)创建.ssh目录)
3)生成秘钥:输入命令ssh-keygen -t rsa,然后一直按回车。
ssh-keygen是ssh秘钥生成器,-t是指定参数,rsa是一种加密算法。
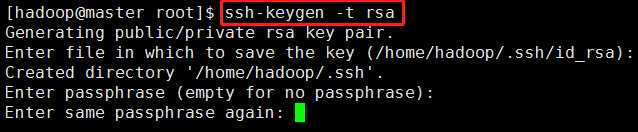
4)切换到.ssh目录下:输入cd /home/hadoop/.ssh,然后输入“ll”命令查看,发现有一个公钥,有一个私钥,(ssh生成的秘钥对都是存储在.ssh这个目录下的)

5)将公钥copy到认证文件里。
输入命令:cp id_rsa.pub authorized_keys
注意:上述命令中文件名authorized_keys一定要正确无误。
然后ll查看就多了一个文件authorized_keys

6)退回到hadoop的家目录,为.ssh赋予权限
chmod 700 .ssh
表示为.ssh目录赋予700的权限
chmod 600 .ssh/*
表示为.ssh目录下的所有文件赋予600的权限
注意:700、600指什么意思?比如文件权限"-rw-------"其中第一个“-”表示该文件为普通文件,接下来9个字符3个为一组,第一组表示该用户的读、写、执行权限,第二组表示用户组,第三组表示其他用户。其中文件的读、写和执行权限,对应字母分别为W/r/x 对应数字分别为4/2/1,那么700就表示用户有读、写、执行权限(7=4+2+1),而用户组和其他用户什么权限都没有。(其实赋予权限这两步也可以不做)
扩展知识:
chmod和chown的区别和联系?
chown用于对文件或目录赋予用户和用户组权限
chmod用于对文件或目录赋予读写执行权限
7)验证SSH免密码是否配置成功
用ssh登录master,第一次登录需要输入yes,第二次以后就不用输入密码了,如果能达到这个效果就表示SSH免密码登录设置成功,登陆的时候用ssh master这个命令。
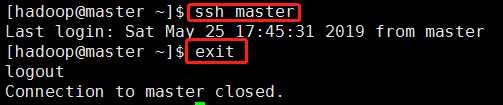
注意:每次免密码登录到其他主机做完对应操作之后一定要退出出来。否则很容易出现错误。
1、为什么要安装jdk?
因为hadoop软件是由Java编写的,Java代码的运行要有Java运行环境及相关的依赖包,所以首先要安装配置JDK。
2、怎么安装JDK?
(1)首先创建安装目录
就是把自己所有需要安装的文件都放在这个安装目录下,以便于管理和维护。(一般在搭建集群之前都要进行目录规划,比如你安装的软件放在哪个目录下,数据、元数据、临时数据放在哪个目录下等等,这些目录都要提前规划好,并赋予好对应的权限,而且这些路径要和配置文件里的一致)
(2)如何创建安装目录呢?
Linux创建目录的命令:mkdir (make directory 的缩写)
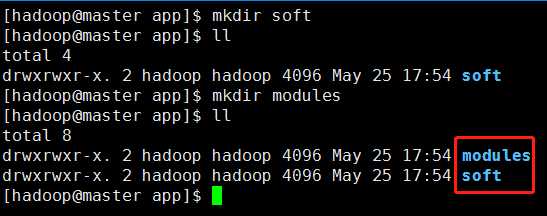
比如我们可以输入mkdir -p /home/hadoop/app(-p指就是如果没有父目录,我们也可以一同创建),当然我们也可以切换到cd /home/hadoop目录下,然后输入mkdir app命令创建这个目录。

为了便于管理,实现安装包和解压包的隔离,我再创建两个目录,soft目录用于存储安装包,modules目录用于存储解压后的软件包。
(3)上传已经在本地下载好的jdk安装包到已创建安装目录下
可以使用rz命令,也可以使用filezilla或其他文件传输工具
(4)输入命令tar zxvf 安装包,进行解压(这里安装的tar包是放到一个soft目录下,解压之后的软件放到一个modules目录下)
tar zxvf jdk-7u79-linux-x64.tar.gz -C ./../modules/

(其中,z代表gzip的压缩包;x代表解压;v代表显示过程信息;f代表后面接的是文件)
注意:指定文件的路径时要和自己文件的存放路径一致,一定要灵活运用。
3、设置环境变量并生效
1)vi /etc/profile,然后配置如下内容。
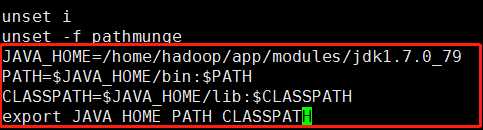
2)输入:source /etc/profile使配置文件生效。

(source命令的作用是,将目前设定的配置刷新。或者我们常说的让配置文件生效)
4、验证jdk的安装是否成功
输入java -version,出现版本信息就表示jdk安装成功。

1、下载并上传Hadoop安装包
切换到之前规划好的软件安装目录,用rz命令或FileZilla工具上传提前下载到本地的Hadoop安装包到指定的软件安装目录下。或使用命令“wget+软件安装包链接”的形式在线下载Hadoop安装包,由于软件包比较大,下载时间比较长,所以不建议采用这种方式。
2、如果是在root用户下上传的hadoop安装包,那么该安装包的权限就是root用户,那么如果在hadoop用户下解压,就会出现权限问题导致不能正确解压。所以在解压之前要先赋予文件正确的权限。

3、解压Hadoop安装包
输入如下命令进行解压:

4、配置hadoop环境变量
(1)输入命令vi /etc/profile
(2)配置环境变量
1)配置格式如下:
添加HADOOP_HOME=hadoop的安装目录
PATH=$HADOOP_HOME/bin:$PATH
export HADOOP_HOME PATH
2)具体配置如下:
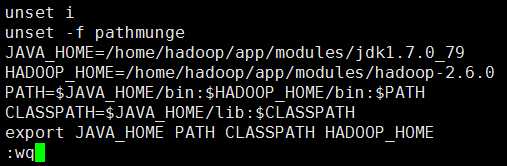
然后:wq保存退出
(3)使配置文件生效source /etc/profile
(4)输入命令“hadoop version”检查hadoop是否安装成功。

5、修改hadoop配置文件
(1)为什么要修改配置文件
如果不修改hadoop配置文件,系统将使用hadoop默认的属性值,有些默认属性值不满足伪分布式集群的搭建(比如副本个数默认为3,而现在只有一个datanode节点无法存储3个副本),所以就要根据集群搭建的特殊需求修改相应的属性来覆盖默认的属性值。
(2)配置文件的位置
Hadoop安装目录下的/etc/hadoop
比如:
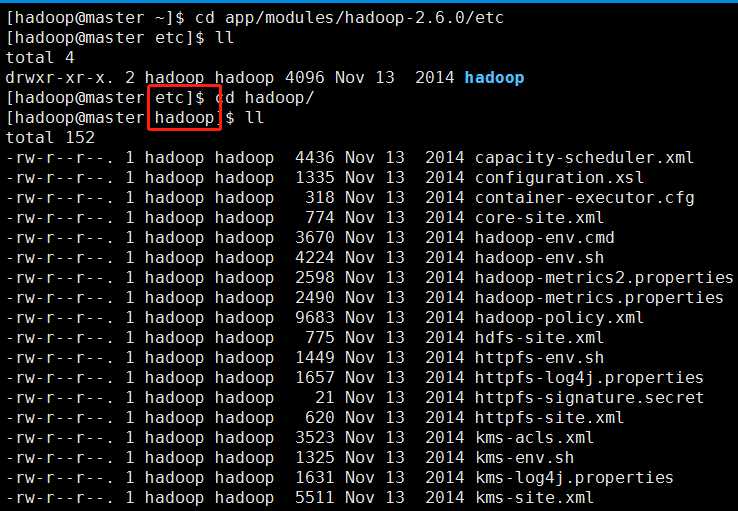
(3)修改哪些配置文件以及如何修改?
主要修改6个配置文件:
(1) hadoop-env.sh
主要修改JDK的安装目录,具体配置如下:

(2)core-site.xml
(3)hdfs-site.xml
(4)mapred-site.xml
(5)yarn-site.xml
(6)slaves
主要配置从节点(比如DataNode)的主机名,即你想让哪个节点作为DataNode节点,那么你就可以把该节点的主机名配置到slaves文件中,如果有多个节点要配置,就按照上面的要求逐行添加,具体配置如下:

6、创建配置文件中指定的3个目录。如果不提前创建,将会导致格式化失败。

修改目录的用户权限为hadoop,否则会因为权限问题导致数据写入不成功。

注意:这几个目录一定要提前创建,并赋予好权限,而且要和配置文件中指定的目录一致。
1、为什么要格式化NameNode?
格式化是对HDFS这个分布式文件系统中的DataNode进行分块,统计所有分块后的初始元数据,然后存储在NameNode中。
2、执行如下命令对NameNode进行格式化。
在hadoop用户下,使用hadoop目录下的bin目录下的hadoop命令, 即先切换到hadoop用户下的hadoop安装目录下。然后输入命令bin/hadoop namenode -format即可。
切换到hadoop安装目录下的bin目录,然后输入命令./hadoop namenode -format也可以,如下图所示:

当出现如下标志,就表示NameNode已经成功的格式化了。
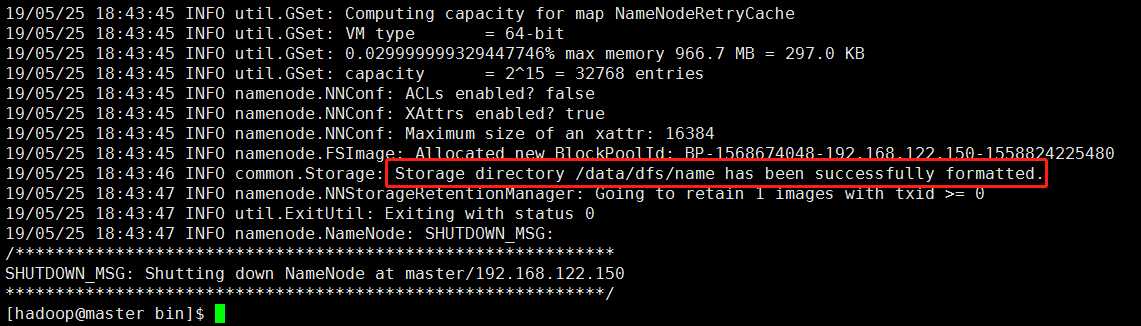
格式化成功之后,查看hdfs-site.xml配置文件中dfs.namenode.name.dir指定的/data/dfs/name目录下是否有current目录,如果有,也说明格式化成功)
在current目录下有如下几个文件,他们代表的含义分别如下:

fsimage:是NameNode元数据在内存中满了之后,持久化保存到的文件。
fsimage*.md5是校验文件,用于校验fsimage的完整性。
seen_txid记录一个id号。
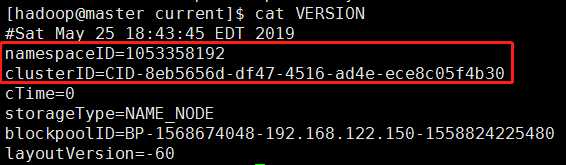
VERSION文件里保存的是namespaceID:NameNode的唯一ID
clusterID:集群ID,NameNode和DataNode的集群ID应该一致,表明是一个集群。
edits:是编辑日志文件,当用户对文件系统进行操作的时候,就会生成对应的编辑日志文件。目前还没有做任何操作,所以还没有编辑日志文件。
(1)在hadoop安装目录下的sbin目录下执行start-all.sh脚本。

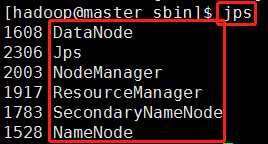
(2)输入jps(java process server) ,如果出现以下进程(5个,不包括jps)表示集群启动成功。
其中jps的作用是显示当前系统的java进程情况,及其id号。jps仅查找当前用户的Java进程,而不是当前系统中的所有进程。
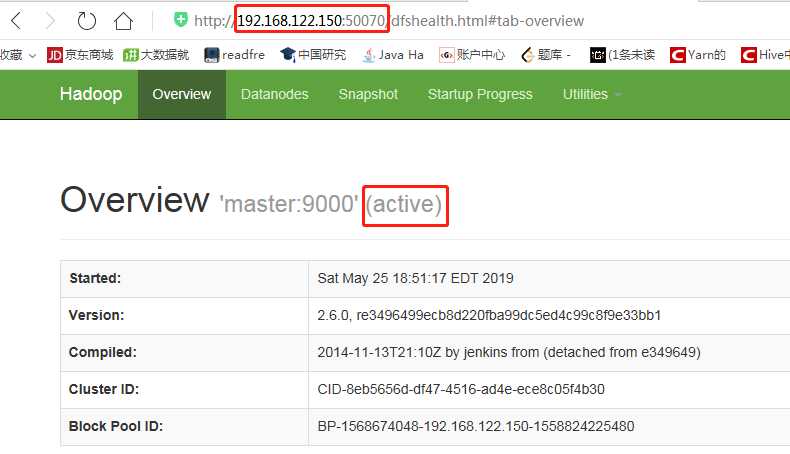
Hadoop伪分布集群启动之后,我们可以通过WebUI查看HDFS和YARN。
(1)通过默认的50070端口访问HDFS文件系统,这个端口可以在默认配置文件hdfs-default.xml中找到。
(2)通过默认的8088端口访问YARN,这个端口可以在默认配置文件yarn-default.xml中找到。
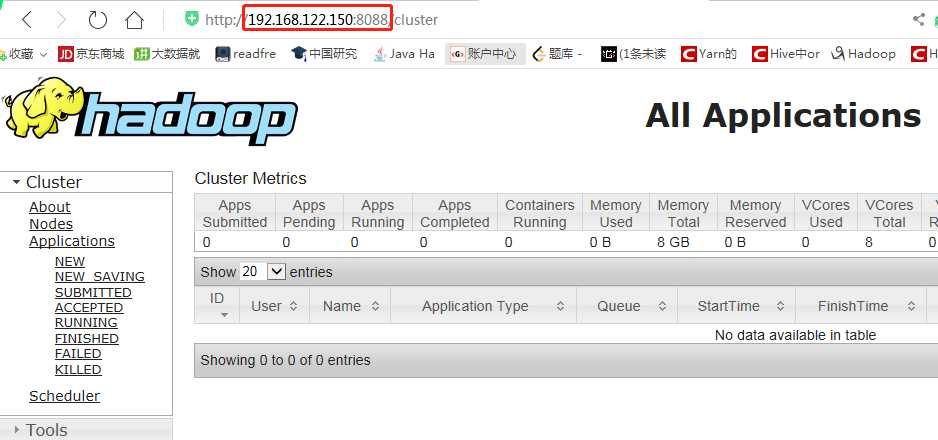
(3)通过主机名访问HDFS和YARN
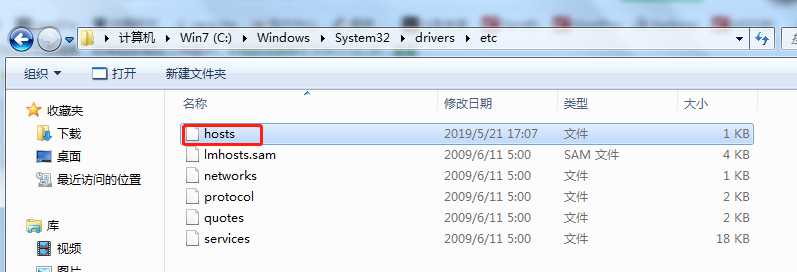
1)在本机的Windows系统中,以上Web UI我们都是通过ip在浏览器中直接访问的,如果想通过hostname来访问,我们需要配置Windows下的HOSTS文件。Windows下的HOSTS文件绝对路径为C:\Windows\System32\drivers\etc
2)在HOSTS文件中添加hostname与ip之间的对应关系,中间用空格分开。
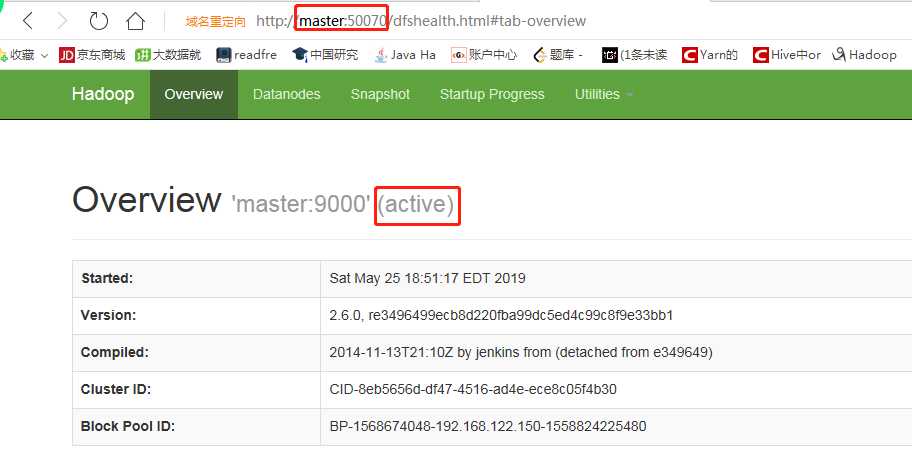
3)然后就可以通过hostname访问HDFS和YARN。
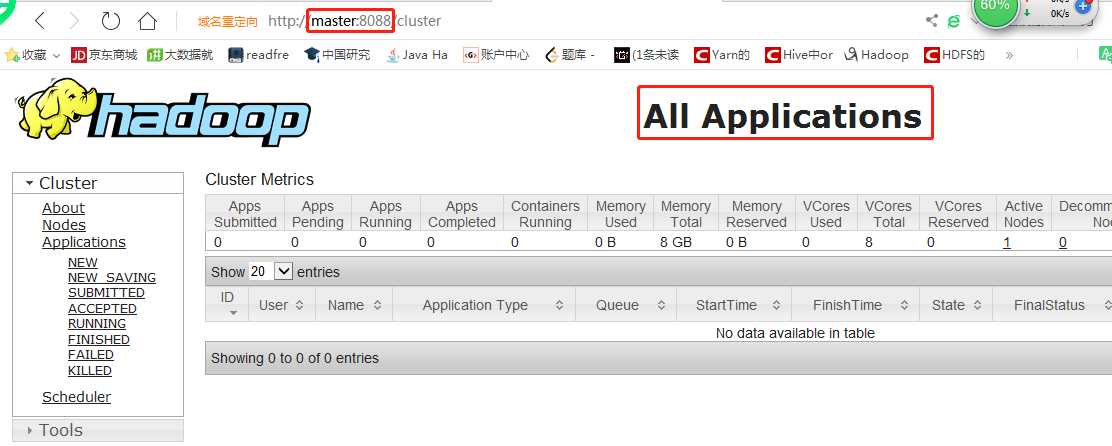
(1)Hadoop 伪分布集群搭建好之后,我们通过命令查看hdfs根目录下没有任何文件。

(2) 准备数据
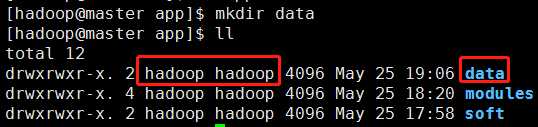
1) 首先在/home/hadoop/app目录下创建一个data目录。
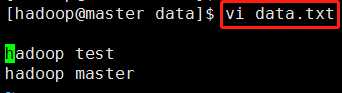
2) 然后在data目录下创建一个文件data.txt,可以输入如下数据。
3) 然后把该文件上传至hdfs的/目录下。

4) 检查是否上传成功

(3) 运行Hadoop例子中自带的wordcount程序。
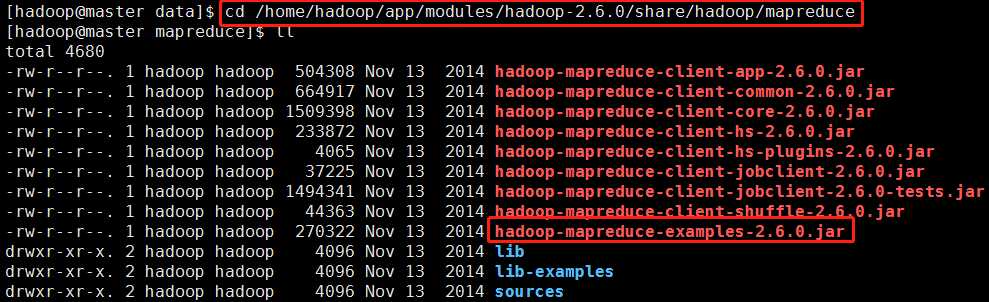
1)切换到mapreduce代码的jar包所在的位置
2)执行如下命令运行WordCount

其中hadoop jar是运行mapreduce的jar包的命令。
./hadoop-mapreduce-examples-2.6.0.jar指jar包的位置,这里用的是相对路径。
wordcount表示要运行的主类的名称,因为jar包中可以包含多个mapreduce代码,要运行哪个必须明确指定。
/data.txt指HDFS文件系统中/目录下的data.txt文件,用来表示输入路径,注意:输入路径必须存在。
/out指/目录下out目录,用来表示输出目录,注意:输出目录不能提前存在,如果提前存在,代码就不会运行并提示相应的错误。
4) 运行成功之后,可以通过web界面查看作业运行结果。结果就在part-r-00000文件中。可以下载该文件查看最终运行结果。
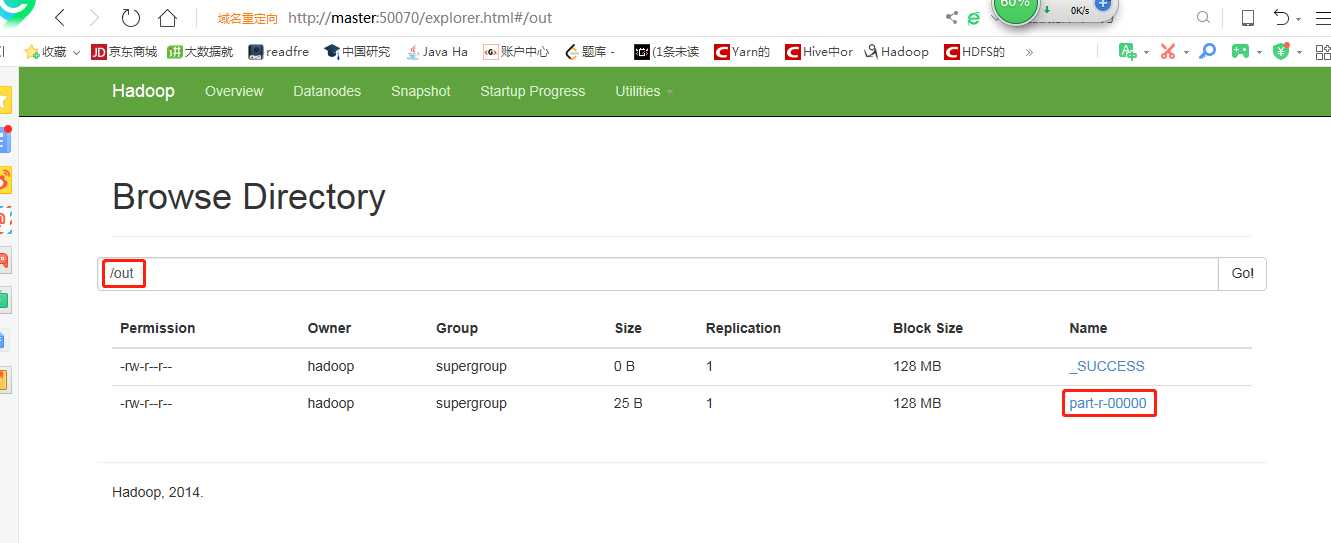
也可以通过shell命令的方式查看最终运行结果,操作如下:

5)也可以在192.168.74.133:8088界面中看到作业的运行进度和状态。
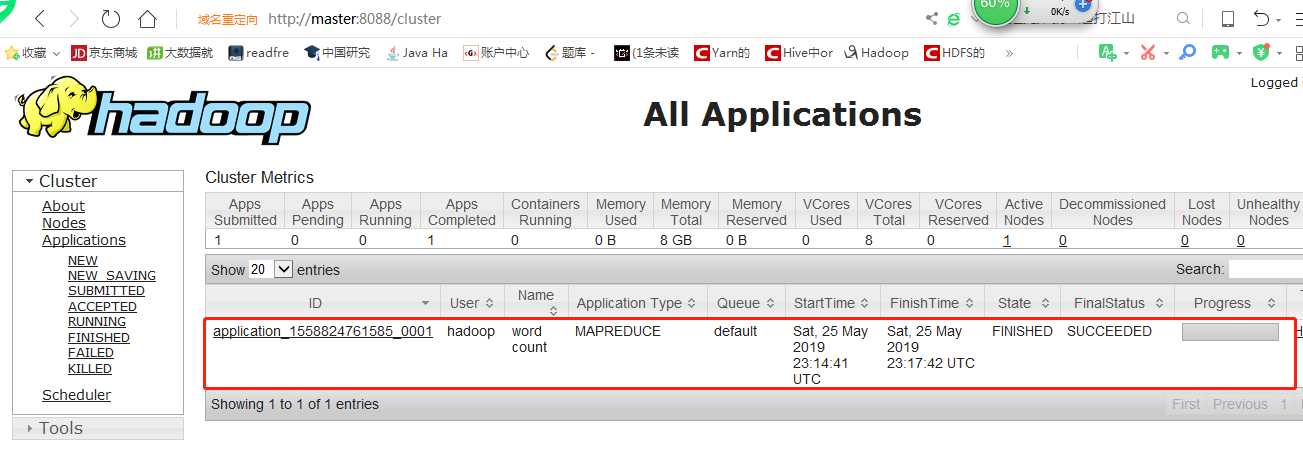
如果以上wordcount程序能正常运行,说明Hadoop伪分布集群就安装成功了。
标签:conf 创建用户 server app 直接 out 临时 help xml配置
原文地址:https://www.cnblogs.com/zhoupp/p/10924536.html