标签:label render pip apt bsp 初始 src and 一个
一 微信好友数据分析
(一)要实现对微信好友数据分析这神奇的操作,首先得准备好工具,那就是安装以下几种库数据
安装 wxpy库 : pip install wxpy
安装 PIL库:pip install pillow
安装 pyecharts库:pip install pyecharts
安装 Itchat库:pip install itchat
安装 Jieba库: pip install jieba
安装 Pandas库:pip install Pandas
安装 Numpy库:pip install Numpy
安装地图数据包:pip install echarts-china-provinces-pypkg
pip install echarts-countries-pypkg
(二)准备好了库,就来实现以下的操作
2.1.爬取好友列表,显示好友昵称、性别和地域和签名, 文件保存为 xlsx 格式
2.1 统计好友的地域分布,并且做成词云和可视化展示在地图上
2.1 获取所有好友的头像,合并成一张大图
(三)分解要实现上述的操作的步骤
3.1 获取用户信息,首先让程序登录微信,并获取我的好友相关信息。
#导入模块 from wxpy import * #初始化机器人,选择缓存模式(扫码)登录 bot = Bot(cache_path=True) #获取我的所有微信好友信息 friend_all = bot.friends()
运行登录代码会自动弹出一个如下的提示的一个二维码页面,打开微信,用手机扫码同意后,进入微信并获取微信好友的相关信息。
3.2 登陆微信成功获取数据后我们可以统计自己微信的好友数目,统计好友男女性比例及好友的省市分布
print(friend_all[0].raw) print( len(friend_all)) lis=[] for a_friend in friend_all: NickName = a_friend.raw.get(‘NickName‘,None) #Sex = a_friend.raw.get(‘Sex‘,None) Sex ={1:"男",2:"女",0:"其它"}.get(a_friend.raw.get(‘Sex‘,None),None) City = a_friend.raw.get(‘City‘,None) Province = a_friend.raw.get(‘Province‘,None) Signature = a_friend.raw.get(‘Signature‘,None) HeadImgUrl = a_friend.raw.get(‘HeadImgUrl‘,None) HeadImgFlag = a_friend.raw.get(‘HeadImgFlag‘,None) list_0=[NickName,Sex,City,Province,Signature,HeadImgUrl,HeadImgFlag] lis.append(list_0)
结果如下:

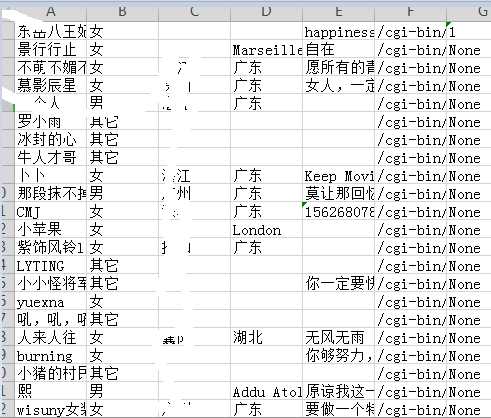
3.3 把上述 lis 列表的信息保存到 excel 中,便于后面的使用,将这个功能写成函数 lis2e07()
def lis2e07(filename,lis): import openpyxl wb = openpyxl.Workbook() sheet = wb.active sheet.title = ‘list2excel07‘ file_name = filename +‘.xlsx‘ for i in range(0, len(lis)): for j in range(0, len(lis[i])): sheet.cell(row=i+1, column=j+1, value=str(lis[i][j])) wb.save(file_name) print("写入数据成功!") print(lis2e07(‘yubg‘,lis))
打开 excel 文件,数据如下图所示:
3. 4 数据分析
Friends = bot.friends() data = Friends.stats_text(total=True, sex=True,top_provinces=30, top_cities=500) print(data)
对数据的简单分析,并将结果打印出来,输出结果如下:

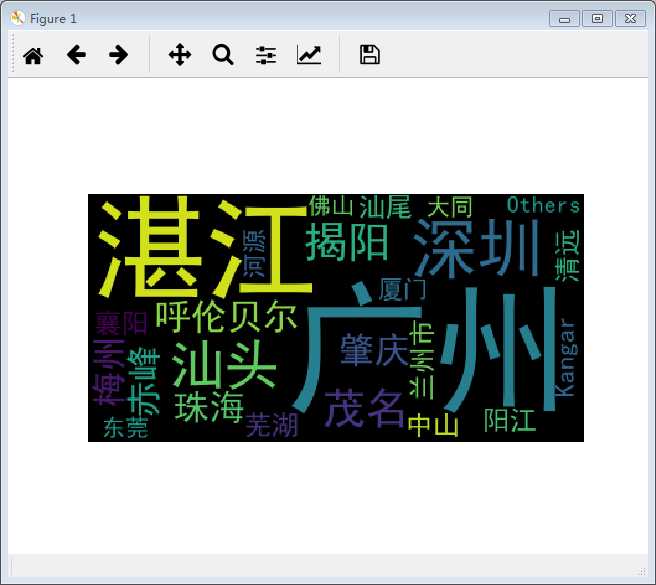
3.5 对 city 列数据做成词云
方法一:利用 plt+wordcloud 方法
from pandas import read_excel df = read_excel(‘yubg1.xlsx‘,sheetname=‘list2excel07‘)(此次调用该表之前,要去文件中打开该表,在表的第一行加上Nickname,sex,city等对应的文字) from wordcloud import WordCloud import matplotlib.pyplot as plt import pandas as pd from pandas import DataFrame word_list= df[‘city‘].fillna(‘0‘).tolist()#将 dataframe 的列转化为 list,其中的 nan 用“0”替换 new_text = ‘ ‘.join(word_list) wordcloud = WordCloud(font_path=‘simhei.ttf‘, background_color="black").generate(new_text) plt.imshow(wordcloud) plt.axis("off") plt.show()
效果图:
方法二:利用 pyecharm 做词云
import pandas as pd #count = df.city.value_counts() #对 dataframe 进行全频率统计,排除了 nan city_list = df[‘city‘].fillna(‘NAN‘).tolist()#将 dataframe 的列转化为 list,其中的 nan 用“NAN” 替换 count_city = pd.value_counts(city_list)#对 list 进行全频率统计 from pyecharts import WordCloud name = count_city.index.tolist() value = count_city.tolist() wordcloud = WordCloud(width=1300, height=620) wordcloud.add("", name, value, word_size_range=[20, 100]) wordcloud.show_config() wordcloud.render(r‘C:/Users/Administrator/map1.html‘)
做成的词云图保存在 c:\Users\lenovo\wc1.html 网页中,打开如下图:

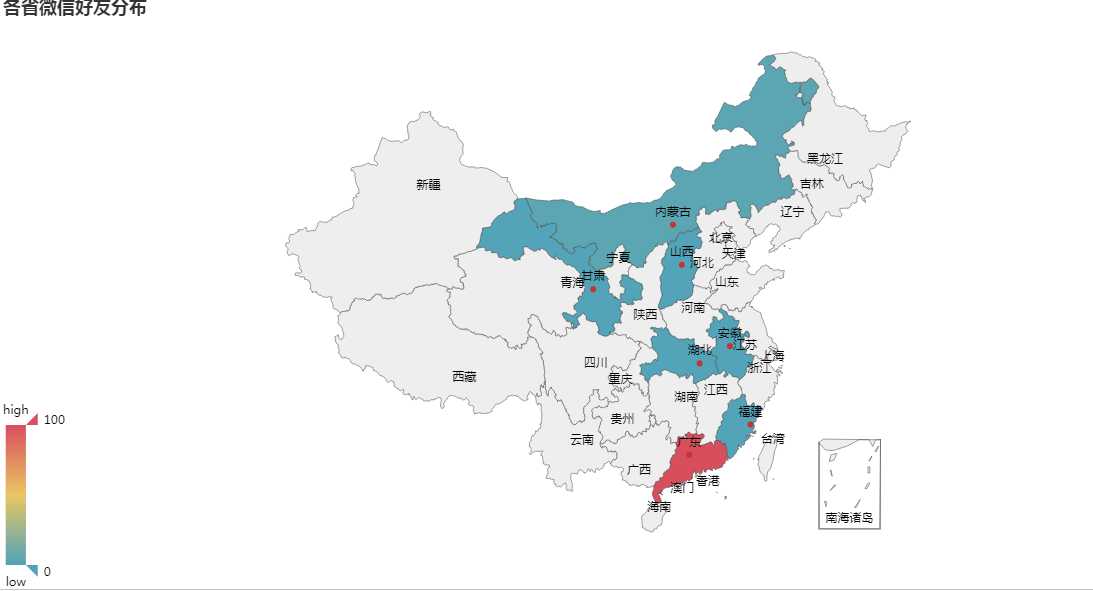
3.6 将好友省份可视化展示在地图上
province_list = df[‘province‘].fillna(‘NAN‘).tolist()#将 dataframe 的列转化为 list,其中的 nan 用“NAN”替换 count_province = pd.value_counts(province_list)#对 list 进行全频率统计 from pyecharts import Map value =count_province.tolist() attr =count_province.index.tolist() map=Map("各省微信好友分布", width=1200, height=600) map.add("", attr, value, maptype=‘china‘, is_visualmap=True, visual_text_color=‘#000‘, is_label_show = True) #显示地图上的省份 map.show_config() map.render(r‘C:/Users/Administrator/map2.html‘)
做成的地图保存在 c:\Users\lenovo\map1.html 网页中,打开如下图
( 四)操作过程的完整个完整代码如下:
# -*- coding: utf-8 -*- """ Created on Sun Jun 2 21:35:32 2019 @author: Administrator """ from wxpy import* bot=Bot(cache_path=True) friend_all=bot.friends() print(friend_all[0].raw) print( len(friend_all)) lis=[] for a_friend in friend_all: NickName = a_friend.raw.get(‘NickName‘,None) #Sex = a_friend.raw.get(‘Sex‘,None) Sex ={1:"男",2:"女",0:"其它"}.get(a_friend.raw.get(‘Sex‘,None),None) City = a_friend.raw.get(‘City‘,None) Province = a_friend.raw.get(‘Province‘,None) Signature = a_friend.raw.get(‘Signature‘,None) HeadImgUrl = a_friend.raw.get(‘HeadImgUrl‘,None) HeadImgFlag = a_friend.raw.get(‘HeadImgFlag‘,None) list_0=[NickName,Sex,City,Province,Signature,HeadImgUrl,HeadImgFlag] lis.append(list_0) # lis 列表的信息保存到 excel 中,便于后面的使用,将这个功能写成函数 lis2e07() def lis2e07(filename,lis): import openpyxl wb = openpyxl.Workbook() sheet = wb.active sheet.title = ‘list2excel07‘ file_name = filename +‘.xlsx‘ for i in range(0, len(lis)): for j in range(0, len(lis[i])): sheet.cell(row=i+1, column=j+1, value=str(lis[i][j])) wb.save(file_name) print("写入数据成功!") print(lis2e07(‘yubg‘,lis)) #将city的结果打印出来 Friends = bot.friends() data = Friends.stats_text(total=True, sex=True,top_provinces=30, top_cities=500) print(data) #利用 plt+wordcloud 方法 对 city 列数据做成词云 from pandas import read_excel df = read_excel(‘yubg1.xlsx‘,sheetname=‘list2excel07‘)(此次调用该表之前,要去文件中打开该表,在表的第一行加上Nickname,sex,city等对应的文字) from wordcloud import WordCloud import matplotlib.pyplot as plt import pandas as pd from pandas import DataFrame word_list= df[‘city‘].fillna(‘0‘).tolist()#将 dataframe 的列转化为 list,其中的 nan 用“0”替换 new_text = ‘ ‘.join(word_list) wordcloud = WordCloud(font_path=‘simhei.ttf‘, background_color="black").generate(new_text) plt.imshow(wordcloud) plt.axis("off") plt.show() #利用 pyecharm 做词云 import pandas as pd #count = df.city.value_counts() #对 dataframe 进行全频率统计,排除了 nan city_list = df[‘city‘].fillna(‘NAN‘).tolist()#将 dataframe 的列转化为 list,其中的 nan 用“NAN” 替换 count_city = pd.value_counts(city_list)#对 list 进行全频率统计 from pyecharts.charts.wordcloud import WordCloud #设置对象 name = count_city.index.tolist() value = count_city.tolist() wordcloud = WordCloud(width=1300, height=620) wordcloud.add("", name, value, word_size_range=[20, 100]) wordcloud.show_config() wordcloud.render(r‘C:/Users/Administrator.html‘) #将这些个好友在全国地图上做分布 province_list = df[‘province‘].fillna(‘NAN‘).tolist()#将 dataframe 的列转化为 list,其中的 nan 用“NAN”替换 count_province = pd.value_counts(province_list)#对 list 进行全频率统计 from pyecharts import Map value =count_province.tolist() attr =count_province.index.tolist() map=Map("各省微信好友分布", width=1200, height=600) map.add("", attr, value, maptype=‘china‘, is_visualmap=True, visual_text_color=‘#000‘, is_label_show = True) #显示地图上的省份 map.show_config() map.render(r‘C:/Users/Administrator/map2.html‘)
标签:label render pip apt bsp 初始 src and 一个
原文地址:https://www.cnblogs.com/2987831760qq-com/p/10975811.html