标签:结合 网卡 规则 均衡 访问 cache nginx服务 公司 手机应用
转:https://www.cnblogs.com/afee666/p/6930181.html
高并发(High Concurrency)是互联网分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计保证系统能够同时并行处理很多请求。
高并发相关常用的一些指标有响应时间(Response Time),吞吐量(Throughput),每秒查询率QPS(Query Per Second),并发用户数等。
互联网分布式架构设计,提高系统并发能力的方式,方法论上主要有两种:垂直扩展(Scale Up)与水平扩展(Scale Out)。
垂直扩展:提升单机处理能力。垂直扩展的方式又有两种:
在互联网业务发展非常迅猛的早期,如果预算不是问题,强烈建议使用“增强单机硬件性能”的方式提升系统并发能力,因为这个阶段,公司的战略往往是发展业务抢时间,而“增强单机硬件性能”往往是最快的方法。
不管是提升单机硬件性能,还是提升单机架构性能,都有一个致命的不足:单机性能总是有极限的。所以互联网分布式架构设计高并发终极解决方案还是水平扩展。
水平扩展:只要增加服务器数量,就能线性扩充系统性能。水平扩展对系统架构设计是有要求的,如何在架构各层进行可水平扩展的设计,以及互联网公司架构各层常见的水平扩展实践,是本文重点讨论的内容。
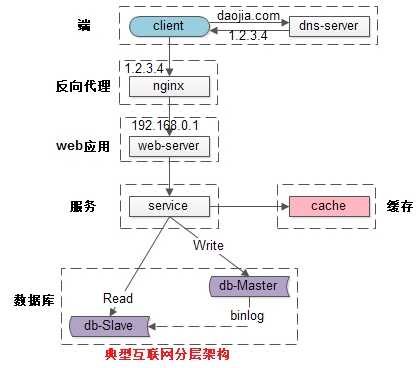
常见互联网分布式架构如上,分为:
整个系统各层次的水平扩展,又分别是如何实施的呢?
反向代理层的水平扩展
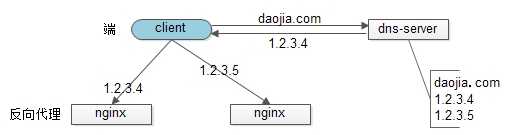
反向代理层的水平扩展,是通过“DNS轮询”实现的:dns-server对于一个域名配置了多个解析ip,每次DNS解析请求来访问dns-server,会轮询返回这些ip。
当nginx成为瓶颈的时候,只要增加服务器数量,新增nginx服务的部署,增加一个外网ip,就能扩展反向代理层的性能,做到理论上的无限高并发。
站点层的水平扩展
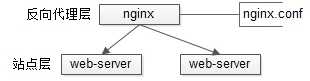
站点层的水平扩展,是通过“nginx”实现的。通过修改nginx.conf,可以设置多个web后端。
当web后端成为瓶颈的时候,只要增加服务器数量,新增web服务的部署,在nginx配置中配置上新的web后端,就能扩展站点层的性能,做到理论上的无限高并发。
服务层的水平扩展
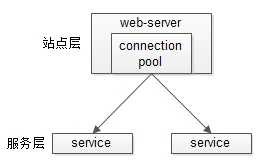
站点层通过RPC-client调用下游的服务层RPC-server时,RPC-client中的连接池会建立与下游服务多个连接,当服务成为瓶颈的时候,只要增加服务器数量,新增服务部署,在RPC-client处建立新的下游服务连接,就能扩展服务层性能,做到理论上的无限高并发。如果需要优雅的进行服务层自动扩容,这里可能需要配置中心里服务自动发现功能的支持。
数据层的水平扩展
在数据量很大的情况下,数据层(缓存,数据库)涉及数据的水平扩展,将原本存储在一台服务器上的数据(缓存,数据库)水平拆分到不同服务器上去,以达到扩充系统性能的目的。
互联网数据层常见的水平拆分方式有这么几种,以数据库为例:
按照范围水平拆分
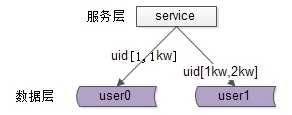
每一个数据服务,存储一定范围的数据,上图为例:
这个方案的好处是:
不足是:
按照哈希水平拆分
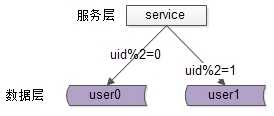
每一个数据库,存储某个key值hash后的部分数据,上图为例:
这个方案的好处是:
不足是:
这里需要注意的是,通过水平拆分来扩充系统性能,与主从同步读写分离来扩充数据库性能的方式有本质的不同。
通过水平拆分扩展数据库性能:
通过主从同步读写分离扩展数据库性能:
缓存层的水平拆分和数据库层的水平拆分类似,也是以范围拆分和哈希拆分的方式居多,就不再展开。
高并发(High Concurrency)是互联网分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计保证系统能够同时并行处理很多请求。
提高系统并发能力的方式,方法论上主要有两种:垂直扩展(Scale Up)与水平扩展(Scale Out)。前者垂直扩展可以通过提升单机硬件性能,或者提升单机架构性能,来提高并发性,但单机性能总是有极限的,互联网分布式架构设计高并发终极解决方案还是后者:水平扩展。
互联网分层架构中,各层次水平扩展的实践又有所不同:
各层实施水平扩展后,能够通过增加服务器数量的方式来提升系统的性能,做到理论上的性能无限。
末了,希望文章的思路是清晰的,希望大家对高并发的概念和实践有个系统的认识。结合上一篇《互联网高可用架构技术实践》的分享,慢慢的互联网分布式架构是不是逐步的不再神秘啦?
标签:结合 网卡 规则 均衡 访问 cache nginx服务 公司 手机应用
原文地址:https://www.cnblogs.com/shyshy/p/11054827.html