标签:har prope 错误 MTA ica 后缀名 实现 res 效果
1、点击tools后再点击Merge TIFF,将所需要的图片集转换成tif格式,源图片集格式支持jpg和tif两种。合成的图片集命名格式为[chi_sim].[test].[exp0].tif 第一个空是字典格式,第二个字体(自定义)名字,第三个空位exp[0]。
2、生成BOX文件,D:\jTessBoxEditorFX\tesseract-ocr\tesseract.exe chi_sim.test.exp0.tif chi_sim.test.exp0 -l chi_sim batch.nochop makebox
D:\temp\train2>D:\jTessBoxEditorFX\tesseract-ocr\tesseract.exe chi_sim.test.exp1.tif chi_sim.test.exp1 -l chi_sim batch.nochop makebox Tesseract Open Source OCR Engine v4.00.00alpha with Leptonica Page 1 Page 2 Page 3 Page 4
-l chi_sim参数是使用已经有的中文训练字库 这个字库是在tessdata目录里,可以自己拷贝进去
3、调整字体坐标,调整识别错误的汉字。使用open打开刚才生成的tif文件,根据刚才生成的box文件调整字库。这个步骤才是真正核心的步骤,也是最麻烦的地方。
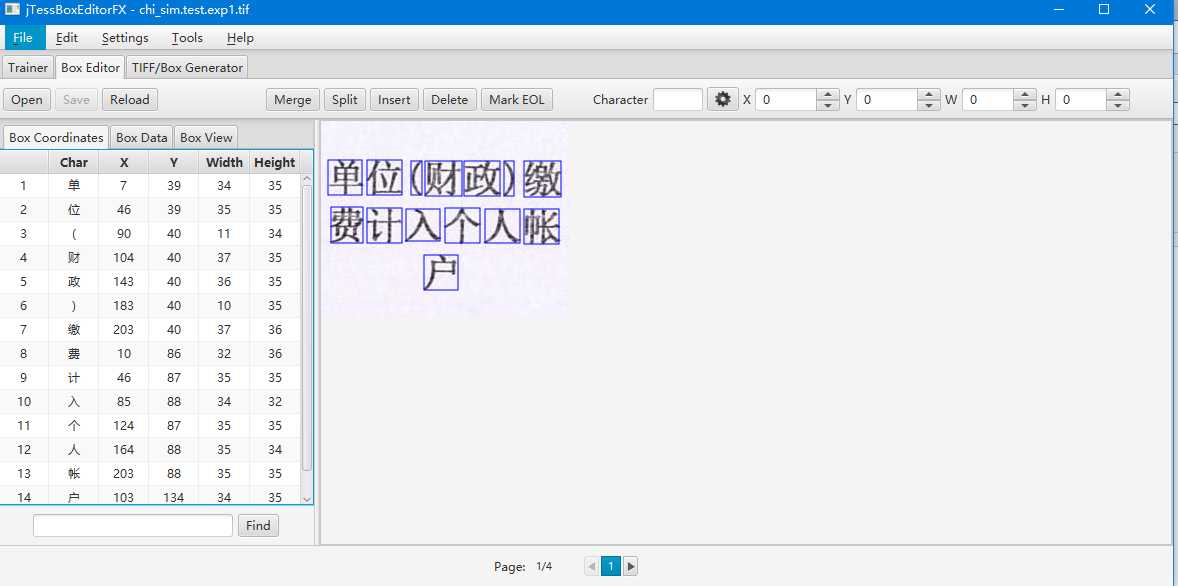
merge合并的时候有几个图片文件,这里就需要按page页分别调整。
4、调整完成box文件后,就需要生成tr文件
D:\jTessBoxEditorFX\tesseract-ocr\tesseract.exe chi_sim.test.exp0.tif chi_sim.test.exp0 nobatch box.train
5、生成unicharset文件
D:\jTessBoxEditorFX\tesseract-ocr\unicharset_extractor.exe chi_sim.test.exp0.box
6、新建font_properties文件 用记事本新建一个明文font_properties.txt
内容格式为test 0 0 0 0 0,test是新建tif中间的内容(chi_sim.test.exp0.tif)。
7、在分别运行三个命令对tr特征集合进行操作
D:\jTessBoxEditorFX\tesseract-ocr\shapeclustering.exe -F font_properties.txt -U unicharset chi_sim.test.exp0.tr
D:\jTessBoxEditorFX\tesseract-ocr\Mftraining.exe -F font_properties.txt -U unicharset -O unicharset chi_sim.test.exp0.tr
D:\jTessBoxEditorFX\tesseract-ocr\cntraining.exe chi_sim.test.exp0.tr
8、重命名把目录下的unicharset、inttemp、pffmtable、shapetable、normproto这五个文件前面都加上test.(就是你的tif中间的名字)
9、组合文件,成功后会生成test.traineddata训练库文件。
D:\jTessBoxEditorFX\tesseract-ocr\combine_tessdata test.(后面是有点的)
10、识别测试,把test.traineddata拷贝到D:\jTessBoxEditorFX\tesseract-ocr\tessdata目录下
D:\jTessBoxEditorFX\tesseract-ocr\tesseract chi_sim.test.exp0.tif output -l test
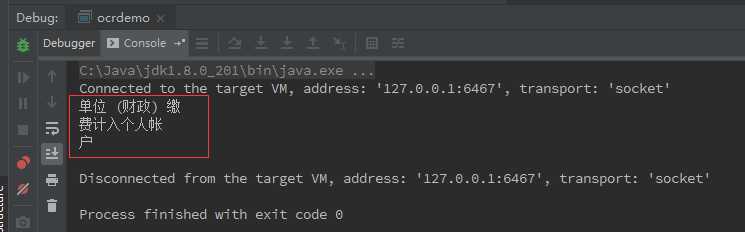
11、在代码中测试效果,可以全部识别出来,简单的代码之前发过(java 使用tess4j实现OCR的最简单样例)

12、如果需要识别的图形比较复杂,一般情况下不能对整张图片进行识别,需要把图片分块识别,用代码也好实现,关键是准备阶段划分图片区域比较费事。
public static void main(String args[]) throws Exception { ITesseract instance = new Tesseract(); instance.setDatapath("tessdata"); //相对目录,这个时候tessdata目录和src目录平级 instance.setLanguage("test");//选择字库文件(只需要文件名,不需要后缀名) try { File imageFile = new File("d:\\temp\\1.jpg"); BufferedImage bufferedImage = ImageIO.read(imageFile); Rectangle rect = new Rectangle(2581,510,249,196);//按区域读取 String result2 = instance.doOCR(bufferedImage,rect); System.out.println(result2); } catch (Exception e) { System.out.println(e.toString()); } }
标签:har prope 错误 MTA ica 后缀名 实现 res 效果
原文地址:https://www.cnblogs.com/asker009/p/11119005.html