标签:机器 iii 输入 awd 过拟合 abi adaboost 比较 dde
一、深度学习建模与调试流程
先看训练集上的结果怎么样(有些机器学习模型没必要这么做,比如决策树、KNN、Adaboost 啥的,理论上在训练集上一定能做到完全正确,没啥好检查的)
Deep Learning 里面过拟合并不是首要的问题,或者说想要把神经网络训练得好,至少先在训练集上结果非常好,再考虑那些改善过拟合的技术(BN,Dropout 之类的)。否则的话回去检查三个 step 哪里有问题。
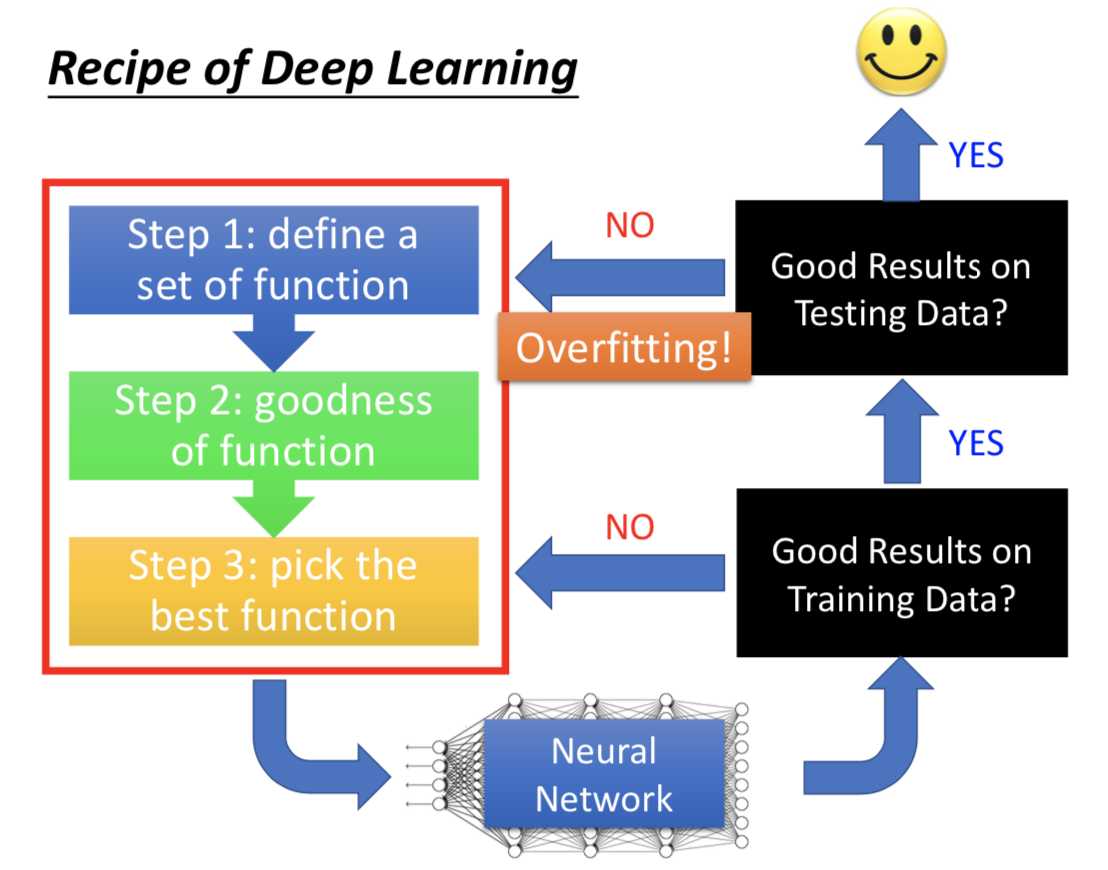
Deep Learning 中的方法为了解决两个主要问题而提出:1.训练集做得不好;2.训练集做得好,测试集做得不好
实际应用的时候搞清楚自己面对的问题,选择对应的技巧。
二、激活函数
1. sigmoid
梯度消失:网络很深的时候,靠近输入的 hidden layers 的梯度对损失函数影响很小, 参数更新的就很慢;靠近输出的情况反之。前面几层的参数都还没怎么更新的时候就收敛了。
原因也比较简单,反向传播的时候每经过一层,都会乘上小于 1 的数(sigmoid 函数 会把输入压到 0~1 之间),结果就越来越衰减。
早期用 RBM ,先训练好前面几层。
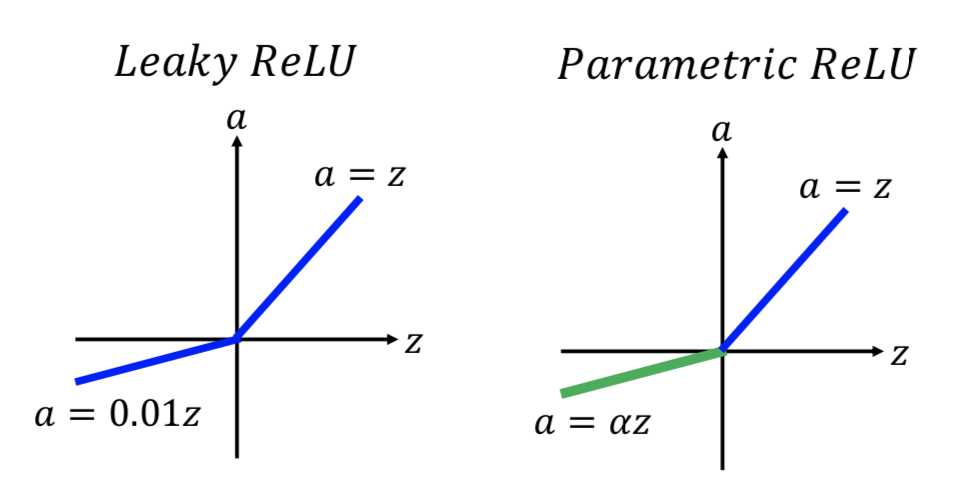
2. ReLU
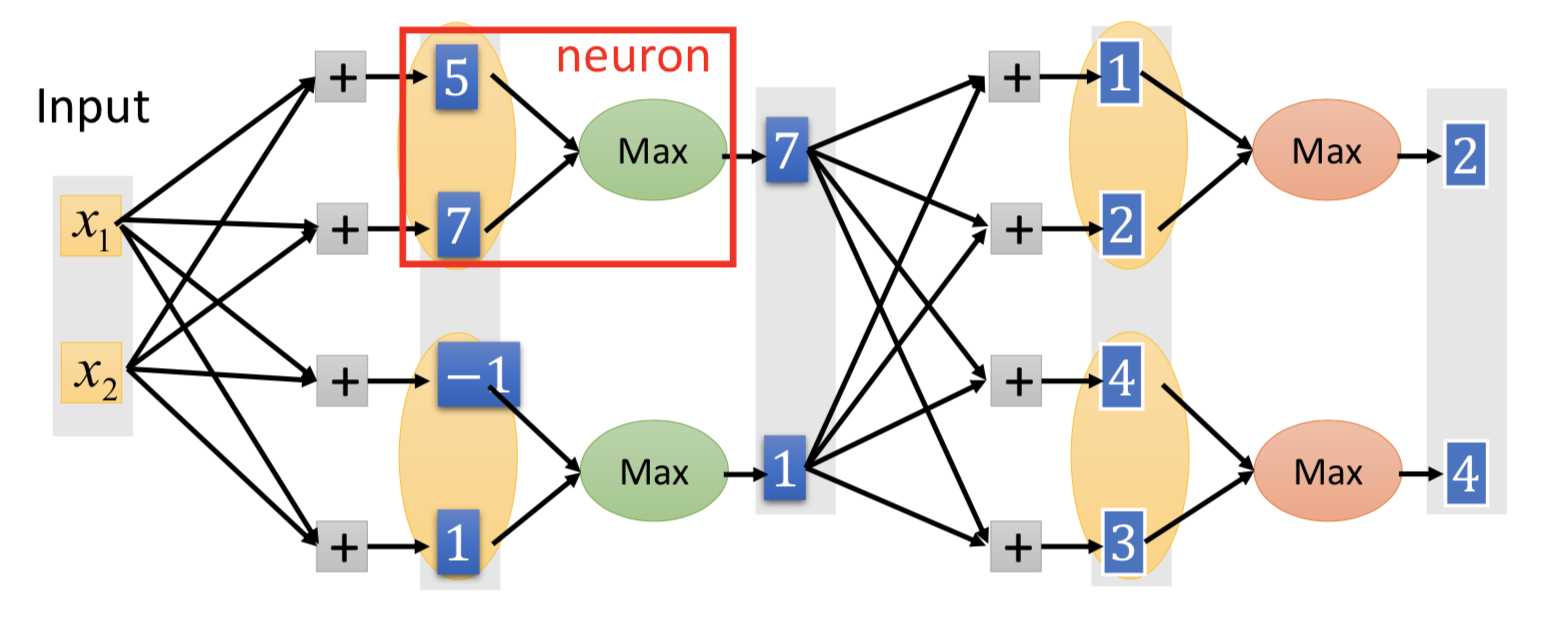
3. maxout network
每个神经元的激活函数的具体形式,是可以学习来的(不一定非得像 ReLU 那样在原点分段):
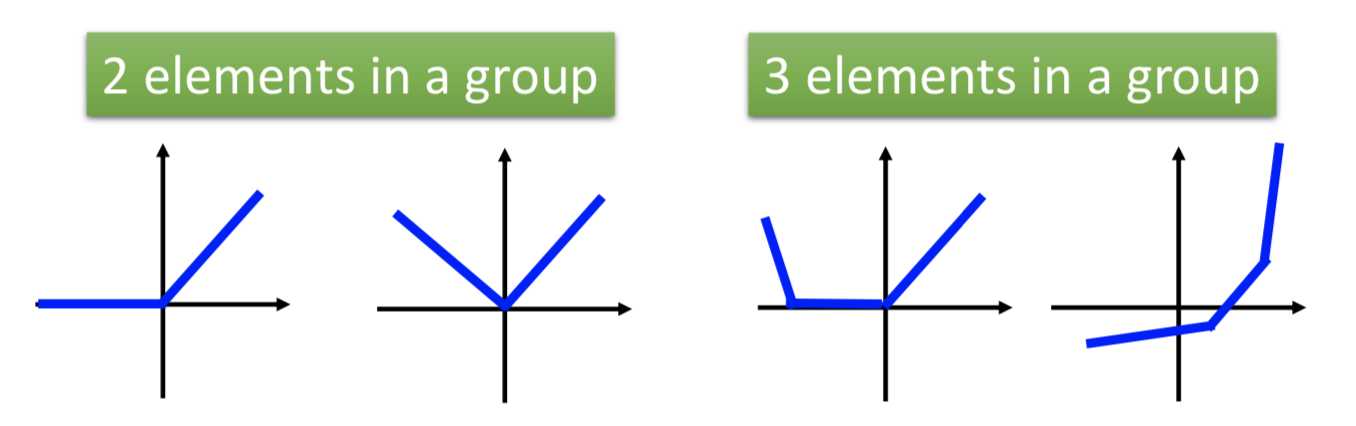
哪些神经元要被 group 起来是事先决定的(比如随机2个或者3个一组之类的,几个一组也可以作为一个参数来学习)。
ReLU 就是特殊情况下的 maxout ;但 maxout 可以实现更多可能的激活函数(根本上是由参数 w 决定的)。
三、梯度下降的改进
1. Adagrad
2. RMSProp
3. Momentum
4. Adam = RMSProp + Momentum
Early Stopping
四、正则化
Dropout
深度学习模型训练技巧 Tips for Deep Learning
标签:机器 iii 输入 awd 过拟合 abi adaboost 比较 dde
原文地址:https://www.cnblogs.com/chaojunwang-ml/p/11196420.html