标签:正则表达 ret 迭代器 结果 筛选 ali 多少 abc object
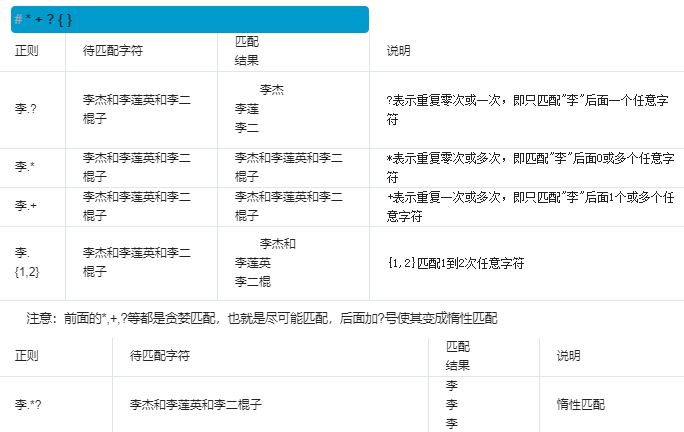

在满足匹配时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配

*? 重复任意次,但尽可能少重复
+? 重复1次或更多次,但尽可能少重复
?? 重复0次或1次,但尽可能少重复
{n,m}? 重复n到m次,但尽可能少重复
{n,}? 重复n次以上,但尽可能少重复
. 是任意字符 * 是取 0 至 无限长度 ? 是非贪婪模式。 何在一起就是 取尽量少的任意字符,一般不会这么单独写,他大多用在: .*?x 就是取前面任意长度的字符,直到一个x出现
import re # 第一个参数是正则表达式,第二个参数是待匹配的文本内容 ret = re.findall(‘a‘, ‘eva egon yuan‘) # 返回所有满足匹配条件的结果,放在列表里 print(ret) ret = re.search(‘a‘, ‘eva egon yuan‘) print(ret) # 结果 : <_sre.SRE_Match object; span=(2, 3), match=‘a‘>? print(ret.group()) # 结果:‘a‘ # 函数会在字符串内查找模式匹配,直到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None,并且需要注意的是如果ret是None,再调用.group()会直接报错。这一易错点可以通过if判断来进行筛选 if ret: print(ret.group()) ret = re.match(‘a‘, ‘abc‘).group() # 同search,不过仅在字符串开始处进行匹配 print(ret) # ‘a‘ # match是从头开始匹配,如果正则规则从头开始可以匹配上,就返回一个对象,需要用group才能显示,如果没匹配上就返回None,调用group()就会报错
ret = re.split(‘[ab]‘, ‘abcd‘) # 先按‘a‘分割得到‘‘和‘bcd‘,在对‘‘和‘bcd‘分别按‘b‘分割
print(ret) # [‘‘, ‘‘, ‘cd‘]
ret = re.sub(‘\d‘, ‘H‘, ‘eva3egon4yuan4‘, 1) # 将数字替换成‘H‘,参数1表示只替换1个
print(ret) # evaHegon4yuan4
ret = re.subn(‘\d‘, ‘H‘, ‘eva3egon4yuan4‘) # 将数字替换成‘H‘,返回元组(替换的结果,替换了多少次)
print(ret) # (‘evaHegonHyuanH‘, 3)
obj = re.compile(‘\d{3}‘) #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字
ret = obj.search(‘abc123456ee‘) #正则表达式对象调用search,参数为待匹配的字符串
print(ret.group()) #结果 : 123
print(ret) # 结果 : <_sre.SRE_Match object; span=(3, 6), match=‘123‘>
import re
ret = re.finditer(‘\d‘, ‘ds3sy4784a‘) #finditer返回一个存放匹配结果的迭代器
print(ret) # <callable_iterator object at 0x10195f940>
print(next(ret).group()) #查看第一个结果 3
print(next(ret).group()) #查看第二个结果 4
print([i.group() for i in ret]) #查看剩余的左右结果 [‘7‘, ‘8‘, ‘4‘]
import re
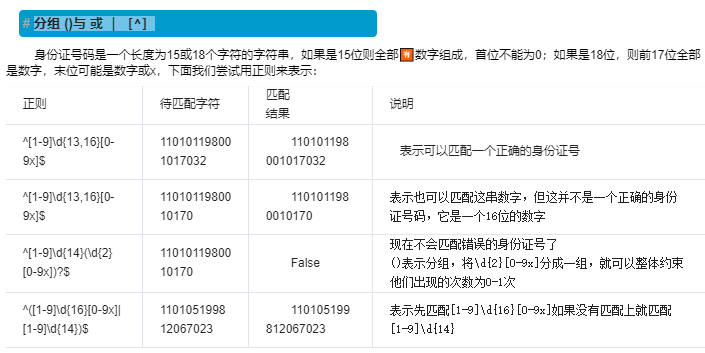
res = re.search(‘^[1-9]\d{14}(\d{2}[0-9x])?$‘,110105199812067023)
print(res.group())
print(res.group(1)) # 获取正则表达式括号阔起来分组的内容
print(res.group(2)) # search与match均支持获取分组内容的操作 跟正则无关是python机制
# 而针对findall它没有group取值的方法,所以它默认就是分组优先获取的结果
ret = re.findall(‘www.(baidu|oldboy).com‘, ‘www.oldboy.com‘)
print(ret) # [‘oldboy‘] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可
ret = re.findall(‘www.(?:baidu|oldboy).com‘, ‘www.oldboy.com‘) # ?:取消分组优先
print(ret) # [‘www.oldboy.com‘]
import re
ret = re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>")
#还可以在分组中利用?<name>的形式给分组起名字
#获取的匹配结果可以直接用group(‘名字‘)拿到对应的值
print(ret.group(‘tag_name‘)) #结果 :h1
print(ret.group()) #结果 :<h1>hello</h1>
"""
注意?P=tag_name相当于引用之前正则表达式,并且匹配到的值必须和前面的正则表达式一模一样
"""
# 匹配整数
ret=re.findall(r"\d+","1-2*(60+(-40.35/5)-(-4*3))")
print(ret) #[‘1‘, ‘2‘, ‘60‘, ‘40‘, ‘35‘, ‘5‘, ‘4‘, ‘3‘]
ret=re.findall(r"\d+\.\d*|(\d+)","1-2*(60+(-40.35/5)-(-4*3))")
print(ret) #[‘1‘, ‘2‘, ‘60‘, ‘‘, ‘5‘, ‘4‘, ‘3‘]
ret.remove("")
print(ret) #[‘1‘, ‘2‘, ‘60‘, ‘5‘, ‘4‘, ‘3‘]
标签:正则表达 ret 迭代器 结果 筛选 ali 多少 abc object
原文地址:https://www.cnblogs.com/buzaiyicheng/p/11202472.html