标签:测试 支持 也有 元组 存在 介绍 工具 href 取值
正则表达式
这里介绍的只是正则的一点点皮毛,如果要详细了解可以看书《正则指引》
1.re模块与正则表达式之间的关系
(1)正则表达式不是python独有的,它是一门独立的技术
(2)所有的编程语言都可以使用正则
(3)但是如果你想在python中使用,你就必须依赖于re模块
2.正则的作用
正则就是用来筛选字符串中的特定的内容的
3.正则的应用场景
(1)爬虫
(2)数据分析
只要是reg...一般情况下都是跟正则有关
4.正则表达式在线测试工具:http://tool.chinaz.com/regex/
5.如果想匹配具体的内容
那么可以直接写完整的内容,不需要写正则
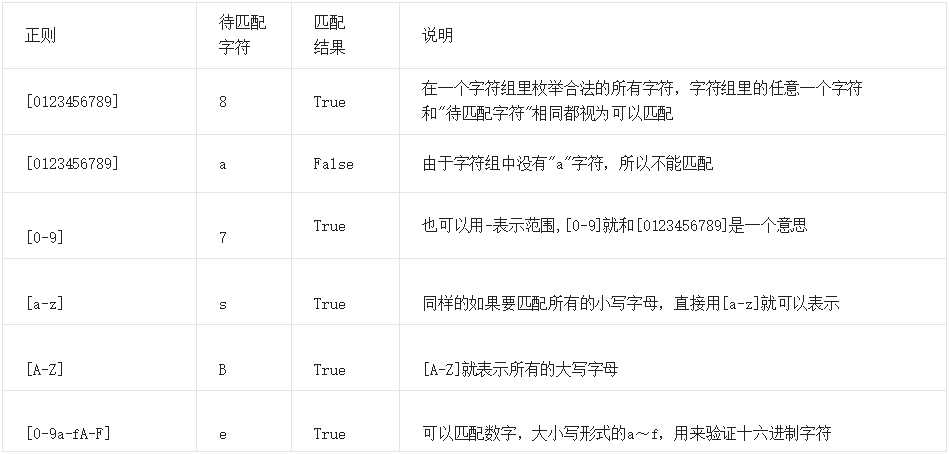
6.字符组:[ ]
在同一个位置可能出现的各种字符组成了一个字符组,在正则表达式中用[ ]表示,字符分为很多类,比如数字、字母、标点等等,一个字符组里面的表达式都是或的关系
如果我们现在要求一个位置只能出现一个数字,那么这个位置上的字符只能是0、1、2...9这10个数中的一个,那怎么用正则表达式写呢
7.字符
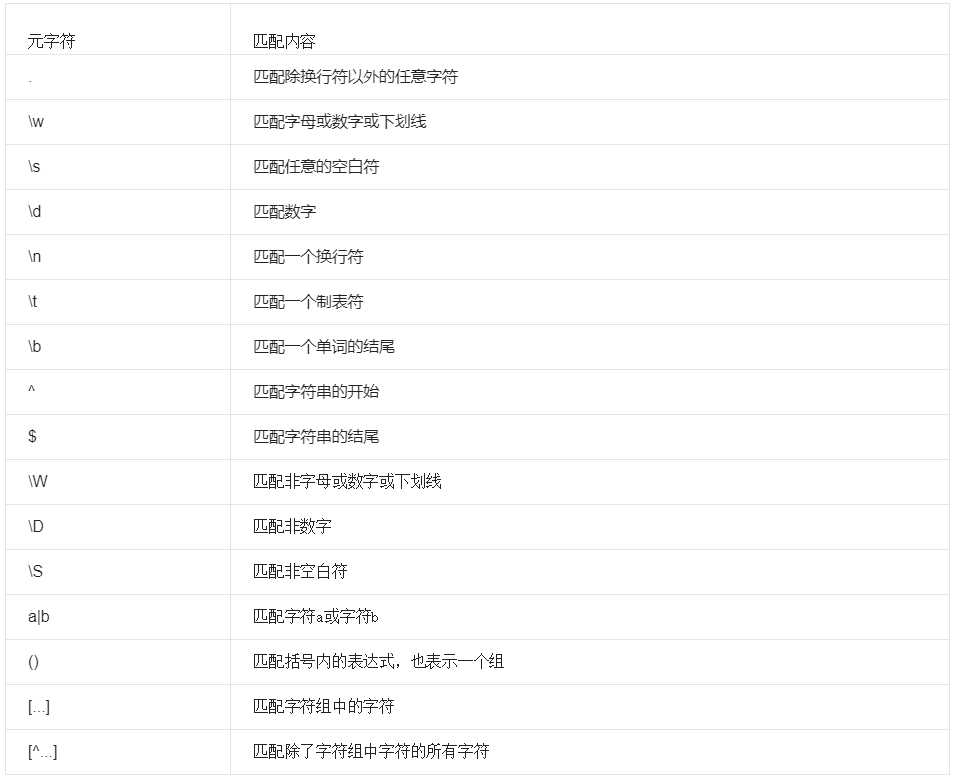
以上每个正则字符只针对单个字符
(1)^与$符连用的情况
例如:^francis$
会精准限制匹配的内容,两者中间写什么,匹配的字符串就必须是什么,多一个也不行少一个也不行
(2)abc|ab的情况
一定要将长的放在前面,匹配规则是如果|前面的匹配上了,|后面的就被舍弃了,所以一定要将长的放在前面
(3)\w,\s,\d与\W,\S,\D相反的匹配关系(对应的两者结合就是匹配全局)
[\w\W]、[\s\S]、[\d\D]
(4)\b匹配一个单词的结尾
n\b:要写上单词以什么结尾(此处表示单词以n结尾),否则无法匹配
(5)^a、[^a]、[^a-z]
^a:如果^直接写在外面,是限制字符串的开头,判断以什么开头
[^a]:如果写在里面,表示除了[ ]内写的字符,其他都要(取反)
(6)分组
当多个正则符号需要重复多次的时候,或者当做一个整体进行其他操作,那么可以写成分组的形式,分组在正则的语法中就是()
([a-z][0-9])*
8.量词

(1)正则在匹配的时候默认都是贪婪匹配(尽量匹配多的)
你可以通过在量词后面加上一个?,就可以将贪婪匹配变成非贪婪匹配(惰性匹配)
\d*、\d+、\d?默认是贪婪匹配的
\d*?、\d+?、\d??修改为多惰性匹配
(2){n}:明确指定个数
\d{2}
(3)量词必须跟在正则符号的后面
量词只能够限制紧挨着它的那一个正则符号
\s\d* 这里的量词*只对\d有效
9.转义符
(1)在正则表达式中,有很多有特殊意义的是元字符,比如\n和\s等,如果要在正则中匹配正常的"\n"而不是"换行符"就需要对"\"进行转义,变成"\\"
(2)在python中,无论是正则表达式,还是待匹配的内容,都是以字符串的形式出现的,在字符串中\也有特殊的含义,本身还需要转义
(3)简便操作,利用r可以让整个字符串都不再转义(了解:r其实就是real的意思,真实不转义)

10.贪婪匹配与非贪婪匹配
(1)<.*>:先拿着里面的.*去匹配所有的内容,然后再根据>往回退着找,遇到>即停止
(2)<.*?>:先拿着?后面的>去匹配符合条件的最少的内容,然后把匹配的结果返回
举例:.*?x
就是取前面任意长度的字符,直到第一个x出现
re模块
1.三个必须掌握的方法
(1)findall
import re ret = re.findall(‘a‘, ‘eva egon yuan‘) # 第一个参数是正则表达式,第二个参数是待匹配的文本内容 print(ret) # 返回所有满足匹配条件的结果,并且返回的是一个列表,列表中的元素就是正则匹配到的结果
(2)search
import re ret = re.search(‘a‘, ‘eva egon yuan‘) print(ret) # search不会给你直接返回匹配到的结果,而是给你返回一个对象 print(ret.group()) # 必须调用group才能看到匹配到的结果 # 如果字符串没有匹配,则返回None,并且需要注意的是如果ret是None,再调用.group()会直接报错 if ret: # 可以通过if判断来进行筛选 print(ret.group())
注意:
search只会依据正则查一次,只要查到了结果,就不会再往后查找
当查找的结果不存在的情况下,调用group直接报错
(3)match
import re ret = re.match(‘a‘, ‘abc‘) # 同search,不过仅在字符串开始处进行匹配 print(ret) # match不会给你直接返回匹配到的结果,而是给你返回一个对象 print(ret.group()) # 必须调用group才能看到匹配到的结果 # match是从头开始匹配,如果正则规则从头开始可以匹配上,就返回一个对象,需要用group才能显示 if ret: # 如果没匹配上就返回None,调用group()就会报错,可以通过if判断来进行筛选 print(ret.group())
注意:
match只会匹配字符串的开头部分
当字符串的开头不符合匹配规则的情况下,返回的也是None,调用group也会报错
2.其他方法
(1)split
import re ret = re.split(‘[ab]‘, ‘abcd‘) # 先按‘a‘分割得到‘‘和‘bcd‘,在对‘‘和‘bcd‘分别按‘b‘分割 print(ret) # [‘‘, ‘‘, ‘cd‘] 返回的还是列表
(2)sub
import re ret = re.sub(‘\d‘, ‘H‘, ‘eva3egon4yuan4‘,1) # 将数字替换成‘H‘,参数1表示只替换1个,不写默认全替换 # sub(‘正则表达式‘,‘新的内容‘,‘待替换的字符串‘,n) # 先按照正则表达式查找所有符合该表达式的内容,统一替换成‘新的内容‘,还可以通过传参来控制替换的个数 print(ret) # evaHegon4yuan4
(3)subn
import re ret = re.subn(‘\d‘, ‘H‘, ‘eva3egon4yuan4‘) # 将数字替换成‘H‘,返回元组(替换的结果,替换了多少次) ret1 = re.subn(‘\d‘, ‘H‘, ‘eva3egon4yuan4‘,1) # 将数字替换成‘H‘,还可以通过传参来控制替换的个数,返回元组(替换的结果,替换了多少次) print(ret) # 返回的是一个元组 元组的第二个元素代表的是替换的个数
(4)compile
import re obj = re.compile(‘\d{3}‘) # 将正则表达式编译成为一个正则表达式对象,规则要匹配的是3个数字 ret = obj.search(‘abc123eeee‘) # 正则表达式对象调用search,参数为待匹配的字符串 res1 = obj.findall(‘347982734729349827384‘) print(ret.group()) # 结果 : 123 print(res1) # 结果 : [‘347‘, ‘982‘, ‘734‘, ‘729‘, ‘349‘, ‘827‘, ‘384‘]
(5)finditer
import re ret = re.finditer(‘\d‘, ‘ds3sy4784a‘) # finditer返回一个存放匹配结果的迭代器 print(ret) # <callable_iterator object at 0x10195f940> print(next(ret).group()) # 查看第一个结果,等价于ret.__next__().group() print(next(ret).group()) # 查看第二个结果,等价于ret.__next__().group() print([i.group() for i in ret]) # 查看剩余的匹配结果
3.findall的优先级查询:分组优先机制
import re res = re.search(‘^[1-9](\d{14})(\d{2}[0-9x])?$‘,‘110105199812067023‘) print(res.group()) print(res.group(1)) # 获取正则表达式括号阔起来分组的内容 print(res.group(2)) # search与match均支持获取分组内容的操作,这个功能跟正则无关是python的机制 # 而针对findall它没有group取值的方法,所以它默认就是分组优先获取的结果 ret = re.findall(‘www.(baidu|oldboy).com‘, ‘www.oldboy.com‘) print(ret) # 结果:[‘oldboy‘] # 这是因为findall会优先把匹配结果组里的内容返回,如果想要匹配结果,取消权限即可 ret = re.findall(‘www.(?:baidu|oldboy).com‘, ‘www.oldboy.com‘) # ?:取消分组优先 print(ret) # [‘www.oldboy.com‘]
4.给某一个正则表达式起别名:?<name>
import re ret = re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>") # 还可以在分组中利用?<name>的形式给分组起名字 # 获取的匹配结果可以直接用group(‘名字‘)拿到对应的值 print(ret.group(‘tag_name‘)) # 获取的匹配结果可以直接用group(‘名字‘)拿到对应的值,结果:h1 print(ret.group()) # 结果:<h1>hello</h1>
注意:
?P=tag_name相当于引用之前正则表达式,并且匹配到的值必须和前面的正则表达式一模一样
5.split的优先级查询:分组优先机制
import re ret=re.split("\d+","eva3egon4yuan") print(ret) #结果 : [‘eva‘, ‘egon‘, ‘yuan‘] ret1=re.split("(\d+)","eva3egon4yuan") print(ret1) #结果 : [‘eva‘, ‘3‘, ‘egon‘, ‘4‘, ‘yuan‘] # 会把切除的内容保存下来
标签:测试 支持 也有 元组 存在 介绍 工具 href 取值
原文地址:https://www.cnblogs.com/francis1/p/11203877.html