标签:int eof 无法 info const 除法 而且 pre 优化
众所周知,OI中其实就是算法竞赛,所以时间复杂度非常重要,一个是否优秀的算法或许就决定了人生,而在大多数情况下,我们想出的算法或许并不那么尽如人意,所以这时候就需要一中神奇的的东西,就是底层优化;
其实底层优化比较简单,比如我们经常使用的 register还有快读,这些都可以进行优化。还有fread,但是fread在一些情况(尤其是在重要的的比赛时)但是还是给出下面的优化
const int L=1<<20|1; char buffer[L],*S,*T; #define getchar() ((S==T&&(T=(S=buffer)+fread(buffer,1,L,stdin),S==T))?EOF:*S++) #define debug(x) cerr<<(x)<<" x"<<endl; #define re register inline LL read() { re LL a=1,b=0;char t; do{t=getchar();if(t==‘-‘)a=-1;}while(t>‘9‘||t<‘0‘); do{b=b*10-‘0‘+t;t=getchar();}while(t>=‘0‘&&t<=‘9‘); return a*b; }
还有的话就是一些位运算优化来卡常:那么我们经常使用的运算其实是非常慢的,他的时钟周期如下:
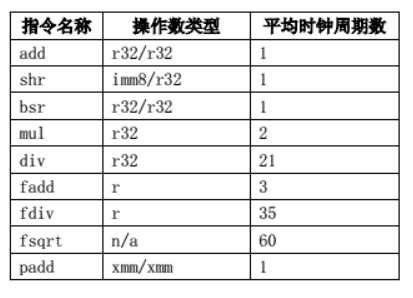
那么我们就可以想象到平时我们写程序的时候其实是常数巨大的
优化就是自己打函数,不调用库函数,由于stl的封装,导致调用函数的时候都是很慢的
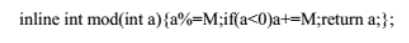
介绍一下inline函数,这个可以让函数强制在线,其实可以把他当成当你使用它的时候,他可以将你写的函数相当于复制粘贴一般的直接插入代码,减少了部分访问函数的时间;
但是这并不是所谓的强制的,他只是建议在线,并且递归函数不能调用,其实编译器并不会报错,因为加了inline编译器也不会在线,因为编译器无法预测递归的层数;

这个其实是减少浮点除法的优化方法;
由于他麻烦,所以笔者在考试和刷题过程中并没有使用过,感兴趣的神犇可以尝试一下,我先说好,如果没有十足的把握,不要在考试的时候使用,一切后果自负;

我在网上看见了神犇的重新定义了log函数,据说比调用stl中的函数快了1.4倍,但是蒟蒻表示看不懂,据说这是指令集的汇编语言(本蒟蒻瞎比比的)
其实重载一些运算其实真的挺有用的,他可能有时候真的可以卡常,还有这个关于指令集,之前学长来给我们讲课的时候说过一句,说是wc2015(好像是)里面介绍了指令集n方过百万的方法;
但是笔者还未达到那种水平,所以在这里就不做介绍了,至于他的可使用性,经过学长的证实,他确实使用指令集n方过了十万,其实已经非常强了


这是一些常用的位运算来优化常数(其实在平时并用不大,或许只有丧心病狂的人才痴迷于这个)
然后其实就没有什么了,还有就是可以将循环展开,因为从一个循环跳转到下一个循环的时候会调用很多时钟周期,这样很耗时,循环展开很好使,但是循环展开代码复杂度很大,稍有不慎就会车毁人亡;

这是常用的函数重载

位运算优化
这里我就想说一点,笔者其实并不喜欢关于卡常这方面的东西,但是笔者身边总有一些人不再算法上改正,光企图使用卡常的手段通过一些数据很水的题,其结果并没有达到训练的目的,而且我很欣赏一句话: 在实现之前的任何优化都是罪恶之源
所以这篇博客只是希望我和大家可以学到一些技巧,并不希望大家和我痴迷于此;
endl;
标签:int eof 无法 info const 除法 而且 pre 优化
原文地址:https://www.cnblogs.com/hzoi-lsc/p/11214064.html