标签:work limit 应对 问题 abs general ssi 分辨率 提前
目录
Zhiqiang Shen, Zhuang Liu, Jianguo Li, Yu-Gang Jiang, Yurong Chen, Xiangyang Xue. DSOD: Learning Deeply Supervised Object Detectors from Scratch. ICCV 2017.
https://arxiv.org/abs/1708.01241
本来打算看DSSD, 结果一字之差先看了DSOD, 本文有一些独特思想, 但本文可能因为是完全中国人著, 至少本文没有此前文章那么容易上手, 配图和各种语法让我读的心力憔悴.
另外我自身的原因除了可能理解能力较差还有一方面是我对本文创作背景有一定断代, 因此读完本文我近期内将会读一读本文涉及的一些背景文章.
在本文以前的所有文章几乎都严重依赖于预训练网络, 其解决问题的一个主要思路是使用预训练网络其后fine-tune, 此做法有诸多缺陷, 我会在正文介绍. 作者主要贡献就是提出了一个从头开始手动训练的网络, 因在原生网络上优化, 因此作者用了更少的参数实现了更好地结果.
当时大多数网络一般是在ImageNet预训练, 其后对其fine-tune, 作者提到fine-tune可视为transfer learning, 我认为这个说法很有意思. fine-tune主要有两个优点:
然而作者认为这样有几个缺点:
本文简单来说就是根据两个猜想而产生组织的:
那么本文就是应对以上两个问题提出了解决方案DSOD.
本问所提出的模型有几个重要的特点, 如deep supervision, feature map融合和复用, 压缩参数等.
DSOD是受SSD启发, 利用其multi-scale和proposal-free的特点, 主要可以分为两部分: 一个是产生feature map的backbone, 另一个是利用multi-scale的prediction网络.
backbone是一个DenseNets的变体, 该网络最大的特点就是deep supervision, 我们以后会介绍此网络, 简单来说就是浅层与深层有连接, 其关键成分dense block和网络结构如下图所示:
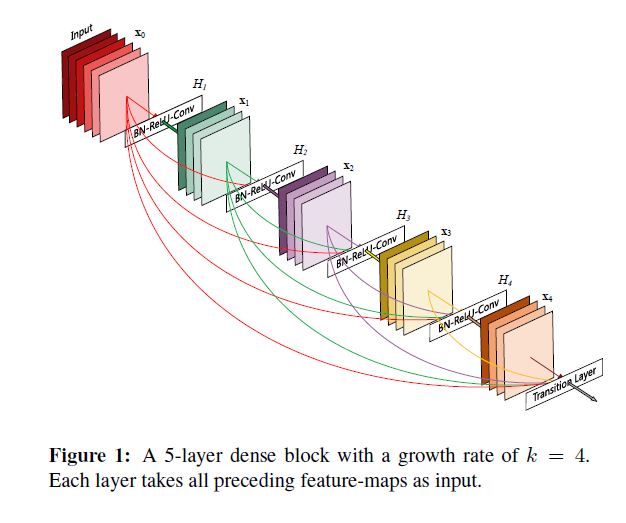
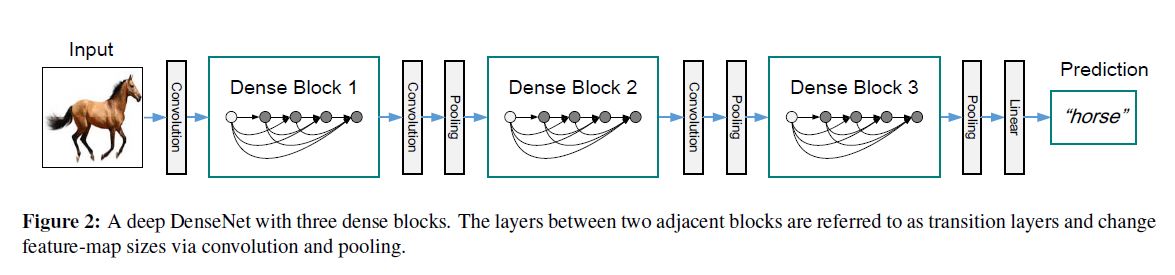
本文中的网络结构和具体细节如下二图所示:
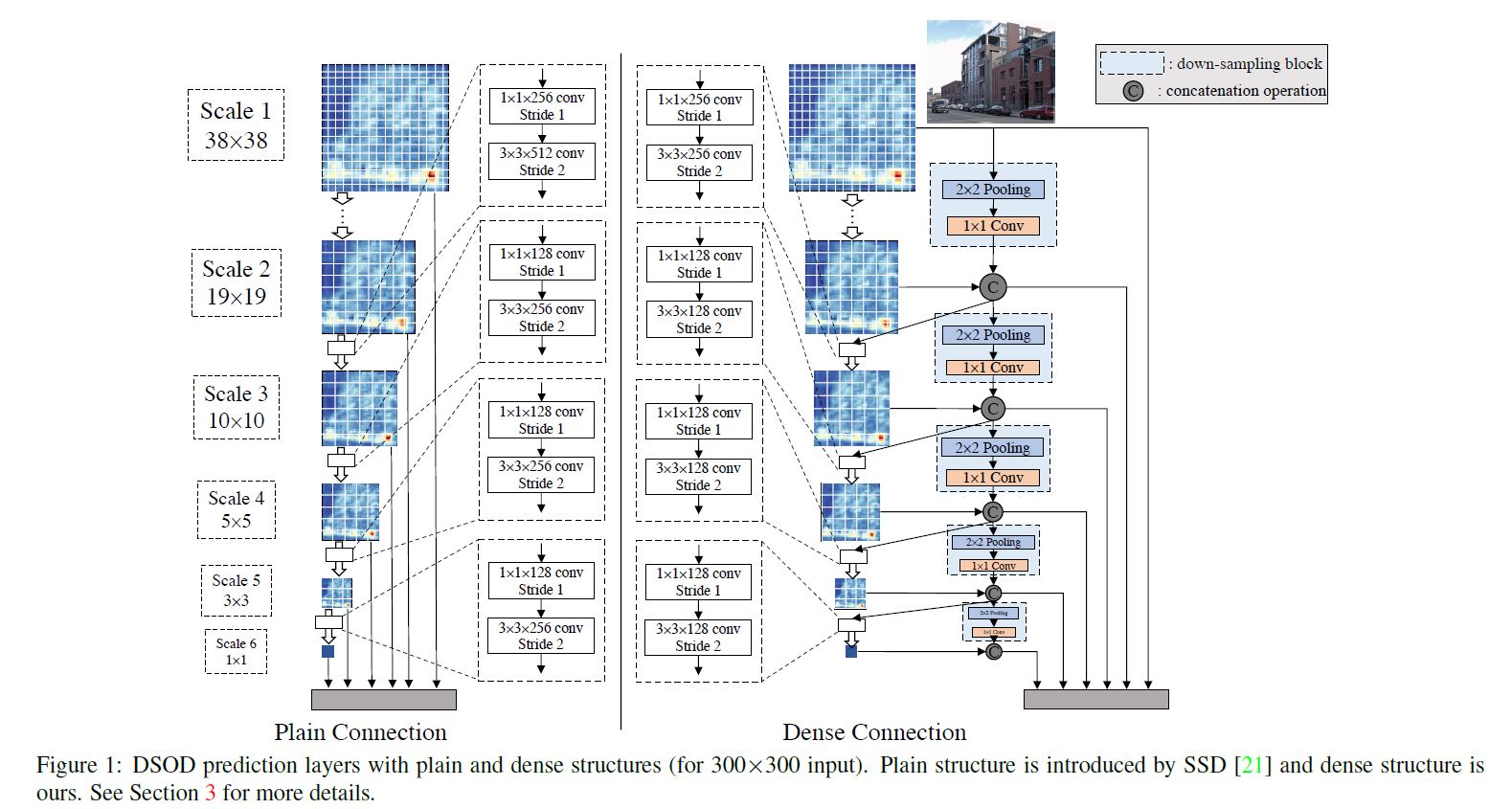
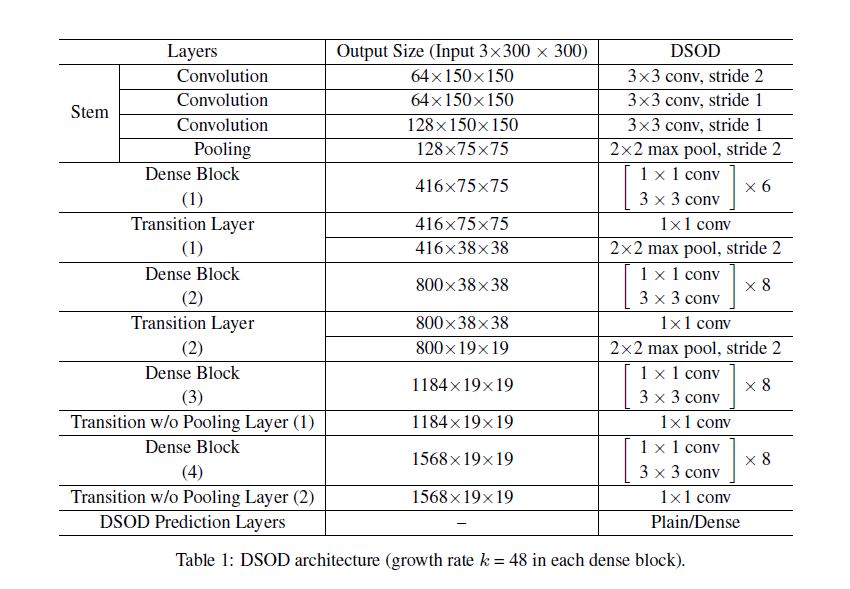
这里我们要重复说一下当时主流方法:
作者通过实验发现只有第三种能收敛, 作者提出一种猜想可能是因为前两种方法都使用RoI pooling, 这样可能会导致反向传播时隐藏梯度(我认为或是说使梯度模糊). 而套用预训练模型后取得较好的结果可能因为参数在RoI pooling之前就已经初始化较好了, 最终我们的结论就是只有第三种方法适合从头训练.
他的优点就是DenseNet的优点.
Deep Supervision结构如图所示,
此结构的主要思想就是提前将信息整合到较浅的位置而不是等到最后等到输出层才进行此操作, 可以说是一个ResNet的升级版. 那么它应对梯度消失效果也是只好不差的.
深层都会和所有的浅层相连因此浅层在反向传播时会受到skip connection的额外监督, 虽然看起来是单个loss反向传播, 但实际浅层受了无障碍的监督.
作者利用此结构既增加了dense block的数量又不降输出的分辨率, 原结构中如果希望输出分辨率固定, 则必须使dense block数量是固定的, 如果想增加网络深度那唯一的解决方法就是增加block的深度, 本文提出的这个结构就是为了解除此限制.
我寻思着不就是个\(1 \times 1\)的卷积结构, 你是想把它吹上天???
就是三个\(3 \times3\)卷积层后接一个\(2 \times 2\)的max pooling层, 能达到提升性能的效果, 作者猜想这样与原始的DenseNet相比这种操作可以减少原始图像的信息损失.
简单来说作者将各个scale的feature map一半是从先前的scale经过卷积层获得, 另一半是从前一层feature map直接down-sample获得.
其中down-sample是一个max pooling后跟\(1 \times 1\)卷积层构成, 其中卷积层是用来减少一半channel.
首先提一点是作者尝试对SSD进行从头训练, 但并没有预训练后fine-tune效果好. 其余实验见图:

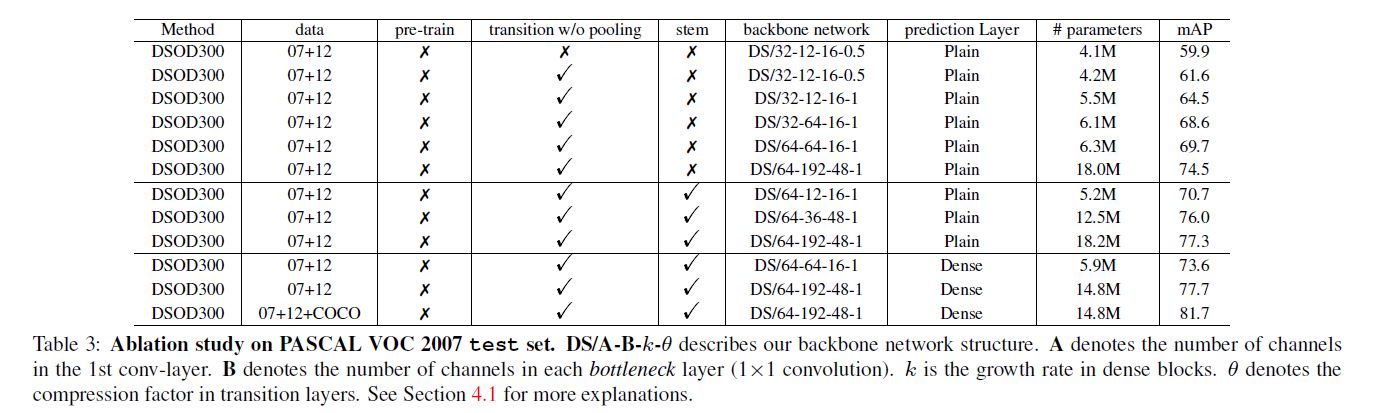
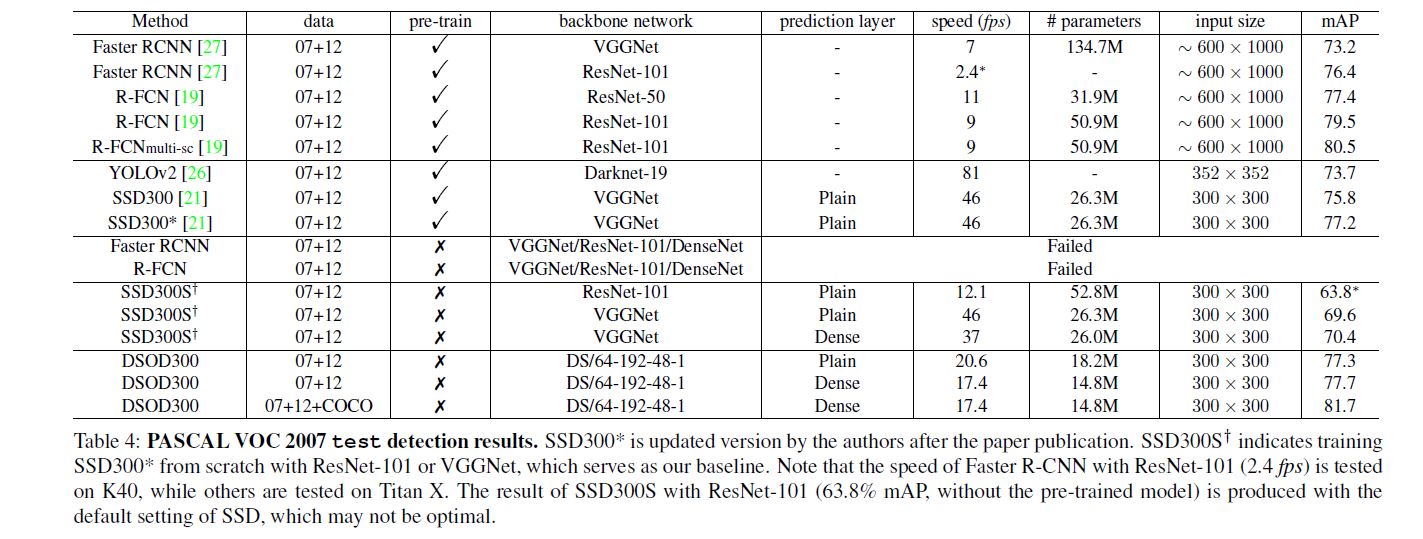
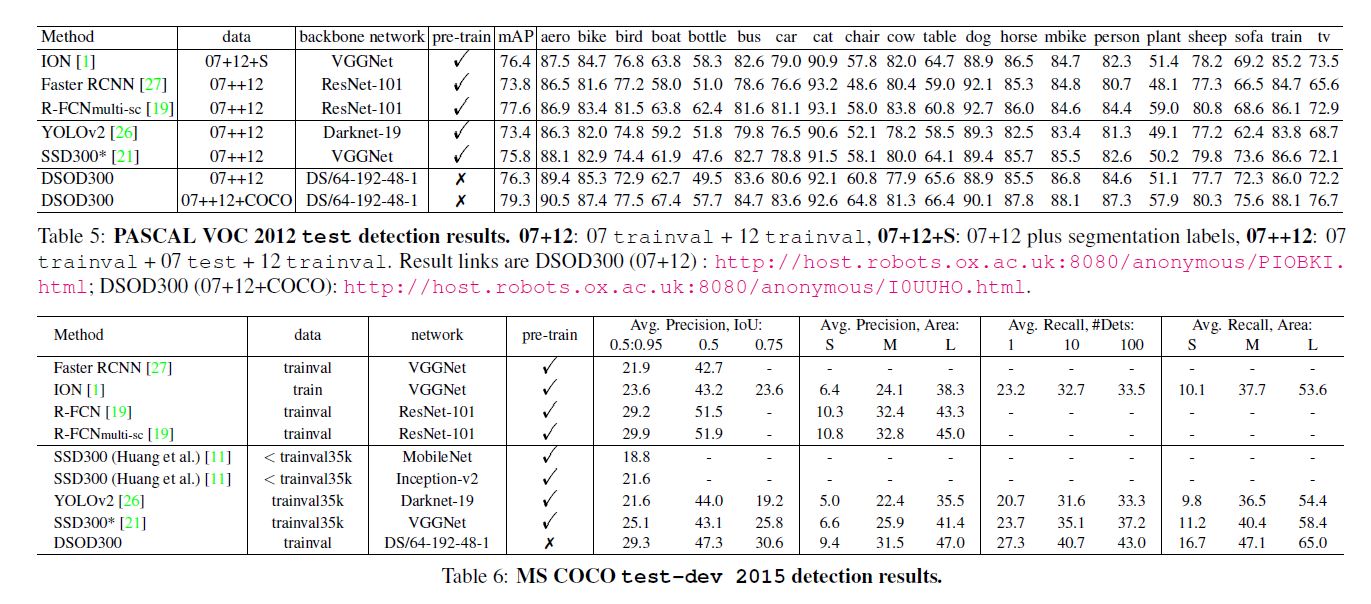
补充几点内容, 作者尝试用ImageNet预训练, 获得66.8%的成绩, 后用"07+12" fine-tune最终得到70.3%的成绩, 效果比从头训练差.
如最后一张图, 作者与R-FCN比较发现IOU调为0.5时表现较差, [0.5:0.95]较好, 说明本文方法定位更精准.
另外本文小物检测表现差, 作者认为分辨率低的缘故. 我觉得就是理论有硬伤, 你觉得高分辨图像能解决你直接套高分图像训练啊!!!
本文主要有以下几点优秀的思想:
我读本文时, 痛苦至极, 连蒙带猜地阅读, 也许是我能力太差了, 问题是我看别人的论文为何没有这种感觉. 对我的理解能力来说配的图片根本没有解释清, 我每看一句话要想半天他想要打算表达什么.
我再也不看你写的论文了.
标签:work limit 应对 问题 abs general ssi 分辨率 提前
原文地址:https://www.cnblogs.com/edbean/p/11331956.html