标签:parent records 0 rows 数据 values extend eva 创建索引 手机
索引好比书的目录。通过索引能快速的定位到一条数据。
在MySQL中除了B+树索引之外,还有一些其他的索引类型。比如:全文索引、(DB和DD索引叫R树索引)。在MySQL cluster中是P树索引,memory引擎中用的是哈希索引。Oracle中的位图索引在MySQL中是没有的。
百分之九十五的时间在跟B+树索引打交道。用的最多的就是B+树索引。
指向下一层的指针就叫做扇出(fanout)
B+树索引在物理上不一定是有序的例如:插入了28,有可能就会排在30的后面。
在逻辑上是有序的,是通过指针来保证逻辑上有序的,页内数据是有序的,页与页之间也是有序的。
show index from orders\G
**********************1.row************************
Table: orders
Non_unique: 0 -- 表示是唯一的
Key_name: PRIMARY -- key的name是primary
Sql_in_index: 1
Column_name: o_orderkey
Collation: A
Cardinality: 1417233 -- 基数,这个列上不重复值的数值
Sbu_part: NULL
Packed: NULL
Null:
Index_type: BTREE -- 索引类型是BTree
Comment:
Index_comment:
**********************2.row************************
Table: orders
Non_unique: 1 -- 表示不是唯一的
Key_name: i_o_orderdate
Sql_in_index: 1
Column_name: o_orderDATE
Collation: A
Cardinality: 2047 -- 基数,这个列上不重复值的数值
Sbu_part: NULL
Packed: NULL
Null: YES
Index_type: BTREE -- 索引类型是BTree
Comment:
Index_comment:
Cardinality表示该索引列上有多少不同的记录,这个是一直预估的值,是采样得到的(由INNODB触发,随机采样20个页,进行预估,有参数可以设置采样多少个页),该值越大越好,即当Cardinality / RowNumber 越接近1越好。表示该列是高选择性的。
--在 information_schema库中的STATISTICS表中记录了Cardinality相关的信息
高选择性: 身份证、手机号码、姓名、订单号等
低选择性: 性别、年龄等
mysql> create table test_index_2(a int,b int,c int);
Query OK, 0 rows affected (0.10 sec)
mysql> alter table test_index_2 add index idx_mul_ab(a,b);
Query OK, 0 rows affected (0.50 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> insert into test_index_2 values
-> (1,1,10),
-> (1,2,9),
-> (2,1,8),
-> (2,4,15),
-> (3,1,6),
-> (3,2,17);
Query OK, 6 rows affected (0.00 sec)
Records: 6 Duplicates: 0 Warnings: 0
mysql> explain select * from test_index_2 where a=1 and b=2\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test_index_2
partitions: NULL
type: ref --此时走了索引
possible_keys: idx_mul_ab
key: idx_mul_ab
key_len: 10
ref: const,const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
mysql> explain select * from test_index_2 where b=2\G -- 只查询b
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test_index_2
partitions: NULL
type: ALL -- 没有使用索引
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 6
filtered: 16.67
Extra: Using where
1 row in set, 1 warning (0.00 sec)
mysql> explain select * from test_index_2 where a=1 or b=2\G -- 使用or,要求结果集是并集
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test_index_2
partitions: NULL
type: ALL --没有使用索引,因为b没有索引,所以b是走全表扫描,既然走全表扫描,a的值也可以一起过滤就没有必要再去查一次a的索引了。
possible_keys: idx_mul_ab
key: NULL
key_len: NULL
ref: NULL
rows: 6
filtered: 30.56
Extra: Using where
1 row in set, 1 warning (0.00 sec)
----特别的例子
----还是只使用b列去做范围查询,发现是走索引了
----注意查询的是 count(*)
mysql> explain select count(*) from test_index_2 where b > 1 and b<3 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test_index_2
partitions: NULL
type: index ----走了索引
possible_keys: NULL
key: idx_mul_ab
key_len: 10
ref: NULL
rows: 6
filtered: 16.67
Extra: Using where; Using index ---- 覆盖索引
1 row in set, 1 warning (0.01 sec)
----因为要求的是count(*),要求所有的记录的和。
----那索引a是包含了全部的记录的,即扫描(a,b)的索引也是可以得到count(*)的
mysql> explain select * from test_index_2 where b>1 and b<3\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test_index_2
partitions: NULL
type: ALL ----查询 * 就没法使用(a,b)索引了,需要全表扫描b列的值。
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 6
filtered: 16.67
Extra: Using where
1 row in set, 1 warning (0.00 sec)
mysql> explain select * from test_index_2 where a=1 and c=10\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test_index_2
partitions: NULL
type: ref ----也是走索引的,先用走a的索引得到结果集,再用c=10去过滤
possible_keys: idx_mul_ab
key: idx_mul_ab
key_len: 5
ref: const
rows: 2
filtered: 16.67
Extra: Using where
1 row in set, 1 warning (0.01 sec)
INFORMATION_SCHEMA
---- information_schema 数据库相当于一个数据字典。保存了表的元信息。
mysql> select * from key_column_usage limit 3\G --显示了哪个索引使用了哪个列
*************************** 1. row ***************************
CONSTRAINT_CATALOG: def
CONSTRAINT_SCHEMA: employees
CONSTRAINT_NAME: PRIMARY
TABLE_CATALOG: def
TABLE_SCHEMA: employees
TABLE_NAME: departments -- 表名
COLUMN_NAME: dept_no -- 索引的名称
ORDINAL_POSITION: 1
POSITION_IN_UNIQUE_CONSTRAINT: NULL
REFERENCED_TABLE_SCHEMA: NULL
REFERENCED_TABLE_NAME: NULL
REFERENCED_COLUMN_NAME: NULL
*************************** 2. row ***************************
CONSTRAINT_CATALOG: def
CONSTRAINT_SCHEMA: employees
CONSTRAINT_NAME: dept_name
TABLE_CATALOG: def
TABLE_SCHEMA: employees
TABLE_NAME: departments
COLUMN_NAME: dept_name
ORDINAL_POSITION: 1
POSITION_IN_UNIQUE_CONSTRAINT: NULL
REFERENCED_TABLE_SCHEMA: NULL
REFERENCED_TABLE_NAME: NULL
REFERENCED_COLUMN_NAME: NULL
*************************** 3. row ***************************
CONSTRAINT_CATALOG: def
CONSTRAINT_SCHEMA: employees
CONSTRAINT_NAME: PRIMARY
TABLE_CATALOG: def
TABLE_SCHEMA: employees
TABLE_NAME: dept_emp
COLUMN_NAME: emp_no
ORDINAL_POSITION: 1
POSITION_IN_UNIQUE_CONSTRAINT: NULL
REFERENCED_TABLE_SCHEMA: NULL
REFERENCED_TABLE_NAME: NULL
REFERENCED_COLUMN_NAME: NULL
3 rows in set (0.66 sec)
EXPLAIN
explain是解释SQL语句的执行计划,即显示该SQL语句怎么执行的。使用explain的时候,也可以使用desc。
5.6版本支持DML语句进行explain解释
5.6版本开始支持JSON格式的输出
注意: EXPLAIN查看的是执行计划,做SQL解析,不会去真的执行;且到5.7以后子查询也不会去执行。
参数extended
mysql> explain extended select * from test_index_2 where b > 1 and b < 3\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test_index_2
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 6
filtered: 16.67
Extra: Using where
1 row in set, 2 warnings (0.00 sec) 有 warnings,这里相当于提供一个信息返回
mysql> show warnings\G
*************************** 1. row ***************************
Level: Warning
Code: 1681
Message: ‘EXTENDED‘ is deprecated and will be removed in a future release. -- 即将被启用
*************************** 2. row *************************** -- 显示真正的执行语句。
Level: Note
Code: 1003
Message: /* select#1 */ select `school`.`test_index_2`.`a` AS `a`,`school`.`test_index_2`.`b` AS `b`,`school`.`test_index_2`.`c` AS `c` from `school`.`test_index_2` where ((`school`.`test_index_2`.`b` > 1) and (`school`.`test_index_2`.`b` < 3))
2 rows in set (0.00 sec)
参数FORMAT
使用 FORMAT=JSON 不仅仅是为了格式化输出效果,还有其他有用的显示信息。
且当5.6版本后,使用MySQL workbench,可以使用visual Explain方式显示详细的图示信息。
mysql> explain format=json select * from test_index_2 where b > 1 and b<3\G
*************************** 1. row ***************************
EXPLAIN: {
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "2.20" -- 总成本
},
"table": {
"table_name": "test_index_2",
"access_type": "ALL",
"rows_examined_per_scan": 6,
"rows_produced_per_join": 1,
"filtered": "16.67",
"cost_info": {
"read_cost": "2.00",
"eval_cost": "0.20",
"prefix_cost": "2.20",
"data_read_per_join": "16"
},
"used_columns": [
"a",
"b",
"c"
],
"attached_condition": "((`school`.`test_index_2`.`b` > 1) and (`school`.`test_index_2`.`b` < 3))"
}
}
}
1 row in set, 1 warning (0.00 sec)
MySQL5.6默认没有安装sys库,也可以安装sys库,但是表的数据量是88个。5.7的sys库是101个表。这是因为5.7中performance_schema加了几张新表,5.6是没有的。
sys库里的表类似于Oracle中的性能视图。他是基于performance_schema表创建的视图。
mysql> use information_schema
mysql> show create table STATISTICS\G
*************************** 1. row ***************************
Table: STATISTICS
Create Table: CREATE TEMPORARY TABLE `STATISTICS` (
`TABLE_CATALOG` varchar(512) NOT NULL DEFAULT ‘‘,
`TABLE_SCHEMA` varchar(64) NOT NULL DEFAULT ‘‘, -- 表所在的库
`TABLE_NAME` varchar(64) NOT NULL DEFAULT ‘‘, -- 表名
`NON_UNIQUE` bigint(1) NOT NULL DEFAULT ‘0‘,
`INDEX_SCHEMA` varchar(64) NOT NULL DEFAULT ‘‘,
`INDEX_NAME` varchar(64) NOT NULL DEFAULT ‘‘, -- 索引名
`SEQ_IN_INDEX` bigint(2) NOT NULL DEFAULT ‘0‘, -- 索引的序号
`COLUMN_NAME` varchar(64) NOT NULL DEFAULT ‘‘,
`COLLATION` varchar(1) DEFAULT NULL,
`CARDINALITY` bigint(21) DEFAULT NULL, -- 这里我们找到了Cardinality
`SUB_PART` bigint(3) DEFAULT NULL,
`PACKED` varchar(10) DEFAULT NULL,
`NULLABLE` varchar(3) NOT NULL DEFAULT ‘‘,
`INDEX_TYPE` varchar(16) NOT NULL DEFAULT ‘‘,
`COMMENT` varchar(16) DEFAULT NULL,
`INDEX_COMMENT` varchar(1024) NOT NULL DEFAULT ‘‘
) ENGINE=MEMORY DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
---- 之前我们可以通过 show index from table_name的方式查看索引
mysql> show index from salaries\G
*************************** 1. row ***************************
Table: salaries
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1 ---- 索引序号为1
Column_name: emp_no
Collation: A
Cardinality: 258047 ---- Cardinality值
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
*************************** 2. row ***************************
Table: salaries
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 2 ---- 索引序号为2
Column_name: from_date
Collation: A
Cardinality: 2494090 ---- Cardinality值
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
---- 现在可以通过INFORMATION_SCHEMA库中的STATISTICS表查看某张表的信息
mysql> select * from STATISTICS where table_name=‘salaries‘\G
*************************** 1. row ***************************
TABLE_CATALOG: def
TABLE_SCHEMA: employees
TABLE_NAME: salaries
NON_UNIQUE: 0
INDEX_SCHEMA: employees
INDEX_NAME: PRIMARY
SEQ_IN_INDEX: 1 -- 索引序号为1
COLUMN_NAME: emp_no
COLLATION: A
CARDINALITY: 258047 -- Cardinality值
SUB_PART: NULL
PACKED: NULL
NULLABLE:
INDEX_TYPE: BTREE
COMMENT:
INDEX_COMMENT:
*************************** 2. row ***************************
TABLE_CATALOG: def
TABLE_SCHEMA: employees
TABLE_NAME: salaries
NON_UNIQUE: 0
INDEX_SCHEMA: employees
INDEX_NAME: PRIMARY
SEQ_IN_INDEX: 2 -- 索引序号为2
COLUMN_NAME: from_date
COLLATION: A
CARDINALITY: 2494090 -- Cardinality值
SUB_PART: NULL
PACKED: NULL
NULLABLE:
INDEX_TYPE: BTREE
COMMENT:
INDEX_COMMENT:
------ 可以看出,上面两个方法得到的Cardinality的值是相等
------ 结论就是information_schema.STATISTICS这张表记录了Cardinality信息。
1.表的信息如table_schema, table_name ,table_rows等在information_schema.TABLES中。
mysql> show create table TABLES\G
*************************** 1. row ***************************
Table: TABLES
Create Table: CREATE TEMPORARY TABLE `TABLES` (
`TABLE_CATALOG` varchar(512) NOT NULL DEFAULT ‘‘,
`TABLE_SCHEMA` varchar(64) NOT NULL DEFAULT ‘‘, -- 表所在的库
`TABLE_NAME` varchar(64) NOT NULL DEFAULT ‘‘, -- 表名
`TABLE_TYPE` varchar(64) NOT NULL DEFAULT ‘‘,
`ENGINE` varchar(64) DEFAULT NULL,
`VERSION` bigint(21) unsigned DEFAULT NULL,
`ROW_FORMAT` varchar(10) DEFAULT NULL,
`TABLE_ROWS` bigint(21) unsigned DEFAULT NULL, -- 表的记录数
`AVG_ROW_LENGTH` bigint(21) unsigned DEFAULT NULL,
`DATA_LENGTH` bigint(21) unsigned DEFAULT NULL,
`MAX_DATA_LENGTH` bigint(21) unsigned DEFAULT NULL,
`INDEX_LENGTH` bigint(21) unsigned DEFAULT NULL,
`DATA_FREE` bigint(21) unsigned DEFAULT NULL,
`AUTO_INCREMENT` bigint(21) unsigned DEFAULT NULL,
`CREATE_TIME` datetime DEFAULT NULL,
`UPDATE_TIME` datetime DEFAULT NULL,
`CHECK_TIME` datetime DEFAULT NULL,
`TABLE_COLLATION` varchar(32) DEFAULT NULL,
`CHECKSUM` bigint(21) unsigned DEFAULT NULL,
`CREATE_OPTIONS` varchar(255) DEFAULT NULL,
`TABLE_COMMENT` varchar(2048) NOT NULL DEFAULT ‘‘
) ENGINE=MEMORY DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
2.information.STATISTICS中存在 table_schema 和table_name 信息
3.将 TABLES 和 STATISTICS 表中的table_schema和table_name相关联通过Cardinality和table_rows 计算,即可得到对应索引名的选择性
3.1 因为存在复合索引,所以我们要取出复合索引中seq最大的那个值 这样取出的Cardinality值才是最大的
*************************** 98. row ***************************
table_schema: school
table_name: test_index_2
index_name: idx_mul_ab -- 这个是上次测试复合索引建立的index
max(seq_in_index): 2 -- 取出了最大的seq
3.2 得到了最大的seq,从而可以取出对应的cardinality
*************************** 91. row ***************************
table_schema: school
table_name: child
index_name: par_ind
cardinality: 0
*************************** 92. row ***************************
table_schema: school
table_name: customer
index_name: PRIMARY
cardinality: 0
*************************** 93. row ***************************
table_schema: school
table_name: parent
index_name: PRIMARY
cardinality: 1
*************************** 94. row ***************************
table_schema: school
table_name: product
index_name: PRIMARY
cardinality: 0
3.3最后通过table_schema和table_name 让上述的信息和TABLES表进行关联
mysql> select
-> t.TABLE_SCHEMA,t.TABLE_NAME,INDEX_NAME,CARDINALITY,TABLE_ROWS,
-> CARDINALITY/TABLE_ROWS AS SELECTIVITY -- 得到选择性
-> FROM
-> TABLES t,
-> (
-> select
-> table_schema,
-> table_name,
-> index_name,
-> cardinality
-> from STATISTICS
-> where (table_schema,table_name,index_name,seq_in_index) IN (
-> select table_schema,
-> table_name,
-> index_name,
-> MAX(seq_in_index)
-> from
-> STATISTICS
-> group by table_schema,table_name,index_name)
-> ) s -- 查询的表二,就是上面3.2的查询结果
-> where t.table_schema = s.table_schema -- 通过库关联
-> and t.table_name = s.table_name -- 在通过表变量
-> and t.table_schema = ‘employees‘ -- 指定某一个库名
-> order by SELECTIVITY;
+--------------+--------------+------------+-------------+------------+-------------+
| TABLE_SCHEMA | TABLE_NAME | index_name | cardinality | TABLE_ROWS | SELECTIVITY |
+--------------+--------------+------------+-------------+------------+-------------+
| employees | dept_emp | dept_no | 8 | 330400 | 0.0000 |
| employees | salaries | emp_no | 274911 | 2494090 | 0.1102 |
| employees | dept_manager | dept_no | 9 | 24 | 0.3750 |
| employees | titles | emp_no | 298025 | 441607 | 0.6749 |
| employees | dept_emp | emp_no | 299687 | 330400 | 0.9070 |
| employees | titles | PRIMARY | 441607 | 441607 | 1.0000 |
| employees | dept_manager | emp_no | 24 | 24 | 1.0000 |
| employees | departments | dept_name | 9 | 9 | 1.0000 |
| employees | salaries | PRIMARY | 2494090 | 2494090 | 1.0000 |
| employees | dept_emp | PRIMARY | 330400 | 330400 | 1.0000 |
| employees | dept_manager | PRIMARY | 24 | 24 | 1.0000 |
| employees | departments | PRIMARY | 9 | 9 | 1.0000 |
| employees | employees | PRIMARY | 298303 | 298303 | 1.0000 |
+--------------+--------------+------------+-------------+------------+-------------+
13 rows in set (0.58 sec)
---- 通过最后一列的SELECTIVITY是否接近1,判断该索引创建是否合理
注意:
Cardinality和table_rows的值,都是通过随机采样,预估得到的
当analyze前后,Cardinality值相差较多,说明该索引是不应该被创建的(页上的记录数值分布不平均)
推荐SELECTIVITY 15%以上是适合的
索引是要排序的,建立索引越多,排序以及维护成本会很大,插入数据的速度会很慢,所以索引建立的多,不仅仅的浪费空间,还会降低性能,增加磁盘IO。
注意: MySQL5.6的版本STATISTICS数据存在问题,截止5.6.28仍然存在,官方定性为BUG
MySQL5.6安装sys库
shell > git clone https://github.com/mysql/mysql-sys.git
shell > ls | grep sys_56.sql
sys_56.sql # 这个就是我们要安装的到mysql5.6的sys
shell > mysql -uroot -S /tmp/mysql.sock_56 < sys_56.sql #直接导入即可
Explain(二)
1.Explain输出介绍
id 执行计划的id标志
select_type SELECT的类型
table 输出记录的表
partitions 符合的分区,[PARTITIONS]
type JOIN的类型
possible_keys 优化器可能使用到的索引
key 优化器实际选择的索引
key_len 使用索引的字节长度
ref 进行比较的索引列
rows 优化器预估的记录数量
filtered 根据条件过滤得到的记录的百分比[EXTENDED]
extra 额外的显示选项
(1).id
从上往下理解,不一定id序号大的先执行
(2).select_type
SIMPLE 简单SELECT(不使用UNION或子查询等)
PRIMARY 最外层的SELECT
UNION UNION中的第二个或后面的select语句
DEPENDENT UNION UNION中的第二个或后面的select语句,依赖于外面的查询
UNION RESULT UNION的结果
SUBQUERY 子查询中的第一个SELECT
DEPENDENT SUBQUERY 子查询中的第一个SELECT,依赖于外面的查询
DERIVED 派生表的SELECT(FROM子句的子查询)
MATERIALIZED 物化子查询
UNCACHEABLE SUBQUERY 不会被缓存的并且对于外部查询的每行都要重新计算的子查询
UNCACHEABLE UNION 属于不能被缓存的UNION中的第二个或后面的SELECT语句
MATERIALIZED
产生中间临时表(实体)
临时表自动创建索引并和其他表进行关联,提高性能
和子查询的区别是,优化器将可以进行MATERIALIZED的语句自动改写成JOIN,并自动创建索引
(3).table
通常是用户操作的用户表
<unionM,N> UNION得到的结果表
排生表,由id=N的语句产生
由子查询物化产生的表,由id=N的语句产生
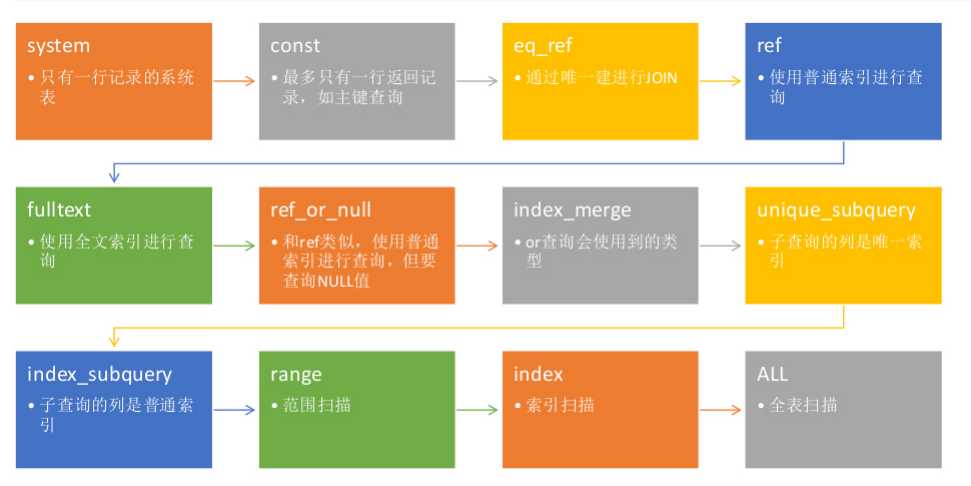
(4).type
(5).extra
Using filesort 需要使用额外的排序得到结果
Using index 优化器只需要使用索引就能得到结果
Using index condition 优化器使用Index Condition Pushdown优化
Using index for group by 优化器只需要使用索引就能处理group by或distinct语句
Using join buffer 优化器需要使用join buffer, join_buffer_size
Using MRR 优化器使用MRR优化
Using temporary 优化器需要使用临时表
Using where 优化器使用where过滤
① Using filesort : 可以使用复合索引将filesort进行优化,提高性能。
② Using index : 比如使用覆盖索引
③ Using where : 使用where过滤条件
Extra的信息是可以作为优化的提示,但是更多的是优化器优化的一种说明
标签:parent records 0 rows 数据 values extend eva 创建索引 手机
原文地址:https://www.cnblogs.com/green-frog-2019/p/11391743.html