标签:缓冲区 http shuff red 好的 mamicode 偏移量 内存 主机
Map Reduce是一个计算框架。Map函数发送到所有含有涉及数据的节点上运行,而Reduce之运行在多台主机上用作收集map结果用,reduce数量取决于reduce收集函数分了几个组,只在几个几个节点上运行。
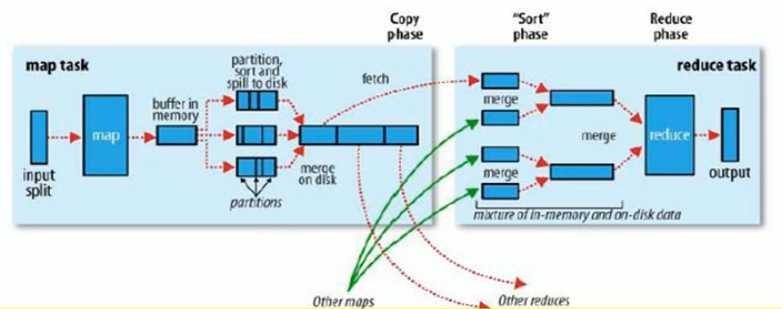
shuffle机制:分组排序
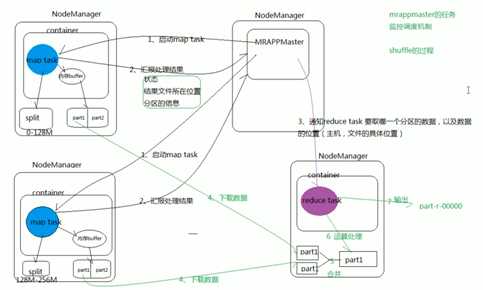
MapReduce执行过程
shuffle机制
标签:缓冲区 http shuff red 好的 mamicode 偏移量 内存 主机
原文地址:https://www.cnblogs.com/fusiji/p/11409919.html