标签:shu 唤醒 调用 oid 打开 cluster uuid spring atomic
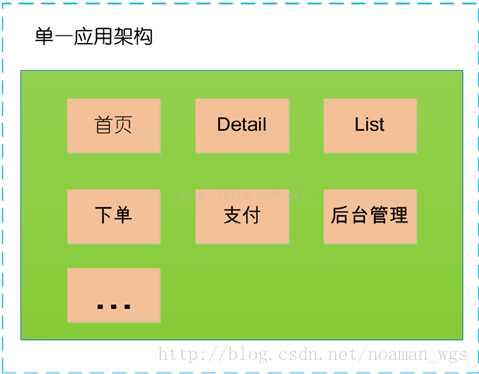
当网站流量很小时,只需一个应用,将所有功能如下单支付等都部署在一起,以减少部署节点和成本。
此时,用于简化增删改查工作量的 数据访问框架(ORM) 是关键。
缺点:单一的系统架构,使得在开发过程中,占用的资源越来越多,而且随着流量的增加越来越难以维护。
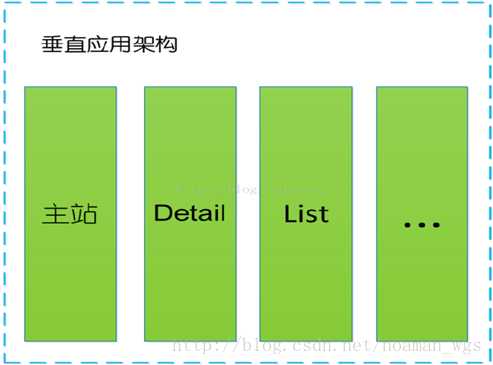
垂直应用架构解决了单一应用架构所面临的扩容问题,流量能够分散到各个子系统当中,且系统的体积可控,一定程度上降低了开发人员之间协同以及维护的成本,提升了开发效率。
此时,用于加速前端页面开发的 Web框架(MVC) 是关键。
缺点:但是在垂直架构中相同逻辑代码需要不断的复制,不能复用。
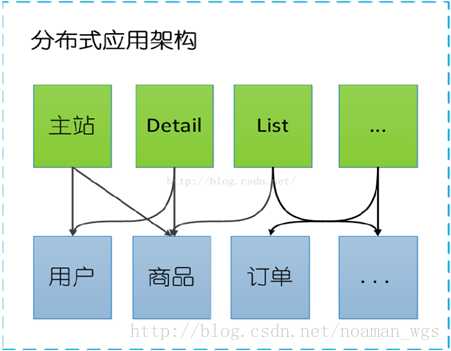
当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心。
此时,用于提高业务复用及整合的 分布式服务框架(RPC) 是关键。
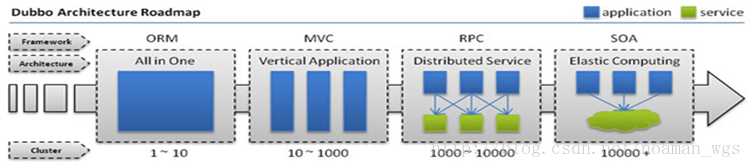
随着服务化的进一步发展,服务越来越多,服务之间的调用和依赖关系也越来越复杂,诞生了面向服务的架构体系(SOA),也因此衍生出了一系列相应的技术,如对服务提供、服务调用、连接处理、通信协议、序列化方式、服务发现、服务路由、日志输出等行为进行封装的服务框架。
当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。
此时,用于提高机器利用率的 资源调度和治理中心(SOA) 是关键。
透明化的远程方法调用,底层封装了 Java NIO 通信框架 Netty、序列化及反序列化框架、以及应用层提供线程池和消息调度,使业务可以快速的实现跨进程的远程通信,就像调用本地服务那样去调用远程服务,而不需要关系底层的通信细节,例如链路的闪断、失败重试等,极大的提高了应用的开发效率。
软负载均衡及容错机制,可以在内网替代 F5 等硬件负载均衡器,降低成本,减少单点。
服务自动注册与发现,基于服务注册中心的订阅发布机制,不再需要写死服务提供方地址,注册中心基于接口名查询服务提供者的ip地址,并且能够平滑添加或删除服务提供者。
服务治理,包括服务注册、服务降级、访问控制、动态配置路由规则、权重调节、负载均衡。
Spring 框架无缝集成、配置化发布服务。
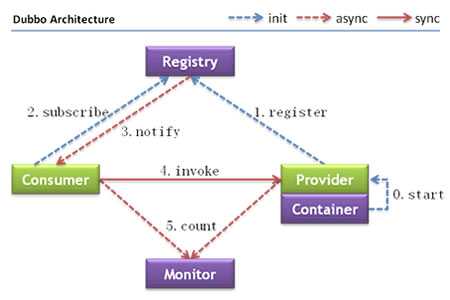
Provider:暴露服务的服务提供方
Consumer:调用远程服务的服务消费方
Registry:服务注册与发现的注册中心
Monitor: 统计服务的调用次数和调用时间的监控中心
Container:服务运行容器
0. 服务容器负责启动,加载,运行服务提供者,通过 main 函数初始化 Spring 上下文,根据服务提供者配置的XML文件将服务按照指定的协议发布,完成服务化的初始化工作。
1. 服务提供者在启动时,根据配置的服务注册中心地址连接服务注册中心,将服务提供者信息发布到注册中心,向注册中心注册自己提供的服务。
2. 服务消费者在启动时,消费者根据服务消费者XML配置文件的服务引用信息,连接到注册中心,向注册中心订阅自己所需的服务。
3. 服务注册中心根据服务订阅的关系,返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送最新的服务地址信息给消费者。
4. 服务消费者调用远程服务时,根据路由策略,从本地缓存的服务提供者地址列表中选择选一台提供者进行,然后根据协议类型建立链路,跨进程调用服务提供者,如果调用失败,再选另一台调用。
5. 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
1. 基于dubbo.jar内的Meta-inf/spring.handlers配置,spring在遇到dubbo名称空间时,会回调DubboNamespaceHandler类。
2. 所有的dubbo标签,都统一用DubboBeanDefinitionParser进行解析,基于一对一属性映射,将XML标签解析为Bean对象。生产者或者消费者初始化的时候,会 将Bean对象转会为url格式,将所有Bean属性转成url的参数。 然后将URL传给Protocol扩展点,基于扩展点的Adaptive机制,根据URL的协议头,进行不同协议的服务暴露和引用。
a、 直接暴露服务端口
在没有使用注册中心的情况,这种情况一般适用在开发环境下,服务的调用这和提供在同一个IP上,只需要打开服务的端口即可。 即,当配置 or ServiceConfig解析出的URL的格式为: Dubbo://service-host/com.xxx.TxxService?version=1.0.0 基于扩展点的Adaptiver机制,通过URL的“dubbo://”协议头识别,直接调用DubboProtocol的export()方法,打开服务端口。
b、向注册中心暴露服务:
和上一种的区别:需要将服务的IP和端口一同暴露给注册中心。 ServiceConfig解析出的url格式为: registry://registry-host/com.alibaba.dubbo.registry.RegistryService?export=URL.encode(“dubbo://service-host/com.xxx.TxxService?version=1.0.0”)
基于扩展点的Adaptive机制,通过URL的“registry://”协议头识别,调用RegistryProtocol的export方法,将export参数中的提供者URL先注册到注册中心,再重新传给Protocol扩展点进行暴露: Dubbo://service-host/com.xxx.TxxService?version=1.0.0
a、直接引用服务:
在没有注册中心的,直连提供者情况下, ReferenceConfig解析出的URL格式为: Dubbo://service-host/com.xxx.TxxService?version=1.0.0
基于扩展点的Adaptive机制,通过url的“dubbo://”协议头识别,直接调用DubboProtocol的refer方法,返回提供者引用。
b、从注册中心发现引用服务:
此时,ReferenceConfig解析出的URL的格式为: ?registry://registry-host/com.alibaba.dubbo.registry.RegistryService?refer=URL.encode(“consumer://consumer-host/com.foo.FooService?version=1.0.0”)
基于扩展点的Apaptive机制,通过URL的“registry://”协议头识别,就会调用RegistryProtocol的refer方法,基于refer参数总的条件,查询提供者URL,如: Dubbo://service-host/com.xxx.TxxService?version=1.0.0
基于扩展点的Adaptive机制,通过提供者URL的“dubbo://”协议头识别,就会调用DubboProtocol的refer()方法,得到提供者引用。 然后RegistryProtocol将多个提供者引用,通过Cluster扩展点,伪装成单个提供这引用返回。
1. client一个线程调用远程接口,生成一个唯一的ID(比如一段随机字符串,UUID等),Dubbo是使用AtomicLong从0开始累计数字的
2. 将打包的方法调用信息(如调用的接口名称,方法名称,参数值列表等),和处理结果的回调对象callback,全部封装在一起,组成一个对象object
3. 向专门存放调用信息的全局ConcurrentHashMap里面put(ID, object)
4. 将ID和打包的方法调用信息封装成一对象connRequest,使用IoSession.write(connRequest)异步发送出去
5. 当前线程再使用callback的get()方法试图获取远程返回的结果,在get()内部,则使用synchronized获取回调对象callback的锁, 再先检测是否已经获取到结果,如果没有,然后调用callback的wait()方法,释放callback上的锁,让当前线程处于等待状态。
6. 服务端接收到请求并处理后,将结果(此结果中包含了前面的ID,即回传)发送给客户端,客户端socket连接上专门监听消息的线程收到消息,分析结果,取到ID,再从前面的ConcurrentHashMap里面get(ID),从而找到callback,将方法调用结果设置到callback对象里。
7. 监听线程接着使用synchronized获取回调对象callback的锁(因为前面调用过wait(),那个线程已释放callback的锁了),再notifyAll(),唤醒前面处于等待状态的线程继续执行(callback的get()方法继续执行就能拿到调用结果了),至此,整个过程结束。
伪代码如下:
public Object get() { synchronized (this) { // 旋锁 while (!isDone) { // 是否有结果了 wait(); //没结果是释放锁,让当前线程处于等待状态 } } } private void setDone(Response res) { this.res = res; isDone = true; synchronized (this) { //获取锁,因为前面wait()已经释放了callback的锁了 notifyAll(); // 唤醒处于等待的线程 } }
先生成一个对象obj,在一个全局map里put(ID,obj)存放起来,再用synchronized获取obj锁,再调用obj.wait()让当前线程处于等待状态,然后另一消息监听线程等到服 务端结果来了后,再map.get(ID)找到obj,再用synchronized获取obj锁,再调用obj.notifyAll()唤醒前面处于等待状态的线程。
标签:shu 唤醒 调用 oid 打开 cluster uuid spring atomic
原文地址:https://www.cnblogs.com/fanguangdexiaoyuer/p/11421413.html