标签:osi 执行 int 压缩 区别 特征提取 sum sci sort
特征提取与特征选择都是数据降维的技术,不过二者有着本质上的区别;特征选择能够保持数据的原始特征,最终得到的降维数据其实是原数据集的一个子集;而特征提取会通过数据转换或数据映射得到一个新的特征空间,尽管新的特征空间是在原特征基础上得来的,但是凭借人眼观察可能看不出新数据集与原始数据集之间的关联。
这里介绍2种常见的特征提取技术:
1)主成分分析(PCA)
2)线性判别分析(LDA)
一种无监督的数据压缩,数据提取技术,通常用于提高计算效率,帮助降低”维度灾难“,尤其是当模型不适于正则化时。
PCA是一种线性转换技术,其目标是在高纬度数据中找到最大方差的方向,并将数据映射到不大于原始数据的新的子空间上。(所谓数据方差最大的方向即数据沿着该方向的分布最分散)
PCA算法的流程:
1)对原始d维数据集做标准化处理;
2)构造样本的协方差矩阵;
3)计算协方差矩阵的特征值和相应的特征向量;
4)选择前k个最大特征值对应的特征向量,其中$k\leq d$;
5)通过前k个特征向量构建映射矩阵W;
6)通过映射矩阵W将d维的原始数据转换为k维的特征子空间。
标准化处理之前的内容有,这里不再赘述;
公式:
$\sigma_{jk}=\frac{1}{n}\sum_{i=1}^{n}(x_{j}^{(i)}-u_{j})(x_{k}^{(i)}-u_{k})$
n代表数据的总个数,$u_{j}$和$u_{k}$分别代表特征j和k的均值;在标准化后的数据中,样本的均值为0,所以在标准化处理后的数据的协方差又可以表示为:
$\sigma_{jk}=\frac{1}{n}\sum_{i=1}^{n}x_{j}^{(i)}x_{k}^{(i)}$
数学原理不在这里细说,代码实现见下面的小节。
选取那些包含信息最多的的特征向量组成子集,特征值的大小决定了特征向量的重要性,所以选择特征值大小靠前的k个特征值作为选中的特征值,其对应的特征变量作为构建映射矩阵的特征向量。
我们还可以绘制特征值的贡献率:
$\frac{\lambda_{j}}{\sum_{j=1}^{d}\lambda_{j}}$,$\lambda_{j}$表示第j个特征值。
将选中的k个特征向量构成一个(d,k)维的矩阵W。
import pandas as pd import numpy as np from sklearn.preprocessing import StandardScaler df = pd.DataFrame([ [1,2,3,4,5,6], [2,4,6,3,3,4], [3,6,10,4,7,7], [2,4,7,6,5,4], [4,7,13,7,3,2], [1,2,3,3,6,4] ],columns=["A","B","C","D","E","F"]) #1.标准化 sc = StandardScaler() sc.fit(df.values) X_std = sc.transform(df.values) #2.生成协方差矩阵 cov_mat = np.cov(X_std) #3.协方差矩阵的特征值与特征向量 eigen_vals,eigen_vecs = np.linalg.eig(cov_mat) #4.按照重要程度由高往低将特征变量排序 sort_list = np.argsort(eigen_vals)
#取前两个向量组成转换矩阵 w = np.column_stack((eigen_vecs[:,sort_list[0]],eigen_vecs[:,sort_list[1]])) #5.取第一个数据进行转换 x_1= X_std[0].dot(w) print(x_1)
结果如下:
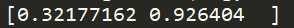
scikit_learn.decomposition模块中的PCA类也可实现此功能,使用方式如下:
from sklearn.decomposition import PCA pca = PCA(n_component=2) X_train_pca = pca(X_train_std)
PCA类中的n_component用于指定需要降到的维数。
LDA的目标是发现可以最优化分类的特征子空间,是一种监督算法。
LDA的执行步骤是:
1)对d维的原数据集进行标准化处理;
2)对于每一类别,计算d维的均值向量;
3)构造类间的散布矩阵$S_{B}$以及类内的散布矩阵$S_{W}$;
4)计算$S_{W}^{-1}S_{B}$的特征值及对应的特征向量;
5)选取前k个特征值所对应的特征向量,构造一个$d\timesk$维的转换矩阵W,其中特征向量以列的形式排列;
6)使用转换矩阵W将样本映射到新的特征子空间上。
大致上与PCA很相似,这里只介绍与PCA中不同的部分。
首先计算均值向量$m_{i}$,$m_{i}$储存了类别i中样本的特征均值$u_{m}$,$m_{i}$不是一个值,而是一个向量,包含了每一个特征的均值。
$m_{i}=\frac{1}{n_{i}}\sum_{x\in D_{i}}^{c}x_{m}$;
import pandas as pd import numpy as np df = pd.DataFrame([ [1,2,3,4,5,"ONE"], [2,4,6,3,3,"TWO"], [2,4,7,6,5,"ONE"], [4,7,13,7,3,"TWO"], ],columns=["A","B","C","D","E","class_label"]) #类别列表 label_list = np.unique(df["class_label"].values) mean_by_label = {} #通过类别的数值作为key保存该类别对应的数据的均值 for label in label_list: mean_by_label[label] = np.mean(df[df["class_label"]==label].values[:,:-1],axis=0) for key,value in mean_by_label.items(): print(key,value)
结果如下:

每个类别i的散布矩阵$S_{i}$的表达式,Ni表示类别i内的样本数量,这个和协方差的表达式是相同的。
$S_{i}=\frac{1}{N_i}\sum_{x\in D_{i}}^{c}(x-m_{i})(x-m_{i})^{T}N_i$
最终的类内散布矩阵$S_{W}$是由各个类别的散布矩阵累加得来的:
$S_{W}=\sum_{i=1}^{c}S_{i}$
$S_{B}=\sum_{i=1}^{c}N_{i}(m_{i}-m)(m_{i}-m)^{T}$
其中c代表类别总数量,Ni表示类别i的样本数量,mi是类别i的均值,m是所有数据的均值
PCA是对协方差举证求特征值和特征向量,而LDA是对$S_{W}^{-1}S_{B}$矩阵求解广义特征值和特征向量,剩下的与PCA相同。
同样scikit-learn库中也实现了LDA类
from sklearn.lda import LDA lda = LDA(n_componets=2)
标签:osi 执行 int 压缩 区别 特征提取 sum sci sort
原文地址:https://www.cnblogs.com/sienbo/p/11432505.html