标签:调用 观察 自己 ng-class 命名方式 记录 -o 不用 五个
什么是集成学习,以前我们都是使用一个算法来进行预测,难免会有"独断专行"的感觉。集成学习是将多个算法集成在一块,然后多个算法对同一个问题进行预测,然后少数服从多数,这便是集成学习。
我们生活中有很多集成学习的例子,比如买东西的时候看推荐,如果10个人推荐你买A产品,但是只有1个人推荐你买B产品,我们会更将倾向于买B产品。
我们看看sklearn是如何为我们提供集成学习的接口的。
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.ensemble import VotingClassifier # ensemble,与集成学习有关的模块
X, y = make_moons(n_samples=500, noise=0.3, random_state=666)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
# 传入一系列分类器,和Pipeline有点像
voting_clf = VotingClassifier([
("log_clf", LogisticRegression()),
("svm_clf", SVC()),
("dt_clf", DecisionTreeClassifier())
], voting="hard") # voting="hard"表示少数服从多数
voting_clf.fit(X_train, y_train)
print(voting_clf.score(X_test, y_test)) # 0.888SoftVoting Classifier是什么呢?我们之前说的集成学习使用投票的方式,通过少数服从多数进行选择。但有些时候少数服从多数并不是合理的吗,也就是可能会出现所谓的"民主暴政"。因此更加合理的方式应该是,对于不同的算法来说,所投的票应该是权值的。
比如经济政策,那么经济学家的建议应该被充分的考虑,或者投的票的权值要大一些。而普通民众,哪怕他是个伟大的航天学家,但与经济无关,所以他的票则不应该被分配较大的权值,这是无可厚非的。
我们实际举例一下

我们看到五个模型进行预测,三个模型预测为B的可能性更大一些,所以2vs3,那么最终结果为B。但是我们仔细观察一下,就能发现端倪,预测为A的模型,它们的把握都是非常高的,而预测为B的模型,相对来说把握就不那么高了。所以这样投票是不公平的,你想到了什么,对,最一开始的K近邻,我们也是使用单纯的个数投票,但是没有把距离给考虑进去。集成学习也是一样,如果一个算法特别的有把握,那么它的票的权值理应被分配的大一些。
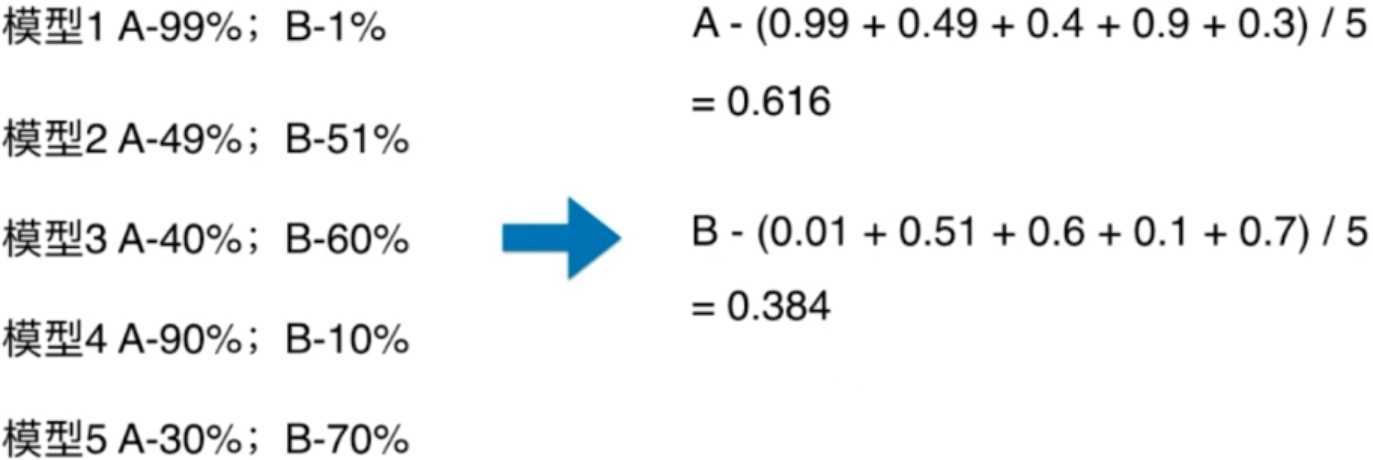
如果是Soft Voting的话,那么使用概率的平均值进行考虑,使用五个模型的预测为A的概率相加取平均值,得到0.616,而B时候0.384,因此我们认为分类的结果为A。
因此使用Softing Voting的话,那么就要求集合中的每一个模型都能估计概率。在逻辑回归中,本身就是基于概率模型进行预测的,有一个predict_proba。而knn显然也是可以的,k取3的话,有两个数据是红色,1个是蓝色,那么是红色的概率就是2/3。决策树也是一样的,走到一个叶子节点,根据训练得到的数据集求出相应的概率。SVM也是可以的,只是会很麻烦,不过sklearn为我们提供好了,只是会牺牲一些计算资源。
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.ensemble import VotingClassifier # ensemble,与集成学习有关的模块
X, y = make_moons(n_samples=500, noise=0.3, random_state=666)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
# 传入一系列分类器,和Pipeline有点像
voting_clf = VotingClassifier([
("log_clf", LogisticRegression()),
("svm_clf", SVC(probability=True)), # 默认SVM是不支持预测概率的,如果需要的话,要加上这个参数
("dt_clf", DecisionTreeClassifier())
], voting="soft") # voting="soft"表示不是少数服从多数,而是有权值
voting_clf.fit(X_train, y_train)
print(voting_clf.score(X_test, y_test)) # 0.896虽然有很多机器学习的方法,但是从投票的角度看,仍然不够多。因此我们要创建更多的子模型,集成更多的子模型的意见。并且注意,子模型之间不能一致,要求差异性。
那么如何创建差异性呢?一种办法是每个子模型只看一部分数据,例如有500个样本数据,每个子模型只看100个样本数据,这样即便算法一样,但是由于样本不同,也是会有差异性的。但是这样的话,子模型的预测的准确率不就变低了吗?事实上也是如此,虽然一个子模型的准确率比较低,但是多个子模型组合在一起准确率就变得高了,这也是集成学习的威力。
那么每个子模型只看样本数据的一部分,那怎么怎么看样本数据的一部分呢?这里也就有了差异,我们有两种方式。
Bagging:放回取样Pasting:不放回取样Bagging更常用,而且避免了随机所带来的问题,因为每一次都放回取样。
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
X, y = make_moons(n_samples=500, noise=0.3, random_state=222)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=222)
bagging_clf = BaggingClassifier(
DecisionTreeClassifier(), # 传入一个分类器,一般我们都会选择决策树
n_estimators=500, # 要创建多少个子模型
max_samples=100, # 每一个子模型看多少个样本
bootstrap=True # 表示是否放回取样,True表示放回,所以在sklearn中只用一个Bagging,通过控制bootstrap来表示是否放回
)
bagging_clf.fit(X_train, y_train)
print(bagging_clf.score(X_test, y_test)) # 0.944我们通过有放回的取样的话,那么由于每一次都是从全部的样本中选出一部分样本,那么是有可能有一部分样本是取不到的,经过严格的数学证明,大概是有37%的样本取不到。这37%的样本就叫做out-of-bag,意思是从来没有被取出来。
既然如此,那么天生就不需要使用train_test_split了,因为有37%的数据是没有见过的,我们直接使用者37%的数据进行测试即可。sklearn也为我们封装一个oob_score_,可以让我们直接查看分数。
from sklearn.datasets import make_moons
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
X, y = make_moons(n_samples=500, noise=0.3, random_state=222)
bagging_clf = BaggingClassifier(
DecisionTreeClassifier(),
n_estimators=500,
max_samples=100,
bootstrap=True,
oob_score=True # 加上这个参数表示我们要记录哪些样本被取了,这样后续才能使用那些没有被使用的样本
)
# 直接传入所有数据进行训练
bagging_clf.fit(X, y)
# 这个命名方式也不用说了,表示不是由用户传来的,而是中途生成的,可以调用查看的属性
print(bagging_clf.oob_score_) # 0.902并且Bagging极易使用并行化处理,可以使用n_jobs参数
我们除了对样本进行采样,每次只看一部分样本,还可以对特征进行采样,即每次只看一部分特征。对于那些特征非常多的样本,比如像素识别,我们就可以使用特征随机采样,通过bootstrap_features=True指定。除此之外,我们既可以针对样本随机采样,也可以针对特征随机采样。
我们之前使用集成学习用的模型都是决策树,这些树都是随机的,并且树的数量多了,就变成了什么呢?对,所以有一个更形象的说法,叫随机森林。
并且sklearn已经为我们封装了随机森林这个算法
from sklearn.datasets import make_moons
from sklearn.ensemble import RandomForestClassifier
X, y = make_moons(n_samples=500, noise=0.3, random_state=666)
rf_clf = RandomForestClassifier(n_estimators=500, # 多少颗决策树
random_state=666, # 树是随机的
oob_score=True,
n_jobs=-1
)
# 直接传入所有数据进行训练
rf_clf.fit(X, y)
# 这个命名方式也不用说了,表示不是由用户传来的,而是中途生成的,可以调用查看的属性
print(rf_clf.oob_score_) # 0.892除了随机森林,还有一个Extra-Trees,意思是极其随机数,数是复数,表示有很多数。在决策树的节点划分上,使用了随机的特征和随机的阈值。提供了额外的随机性,抑制过拟合,但增大了bias。
from sklearn.datasets import make_moons
from sklearn.ensemble import ExtraTreesClassifier
X, y = make_moons(n_samples=500, noise=0.3, random_state=666)
rf_clf = ExtraTreesClassifier(n_estimators=500, # 多少颗决策树
random_state=666, # 树是随机的
oob_score=True,
bootstrap=True,
n_jobs=-1
)
rf_clf.fit(X, y)
print(rf_clf.oob_score_) # 0.892当然除了分类问题,也可以解决回归问题。
Boosting,继承多个模型,每个模型都在尝试增强(Boosting)整体的效果。举个栗子
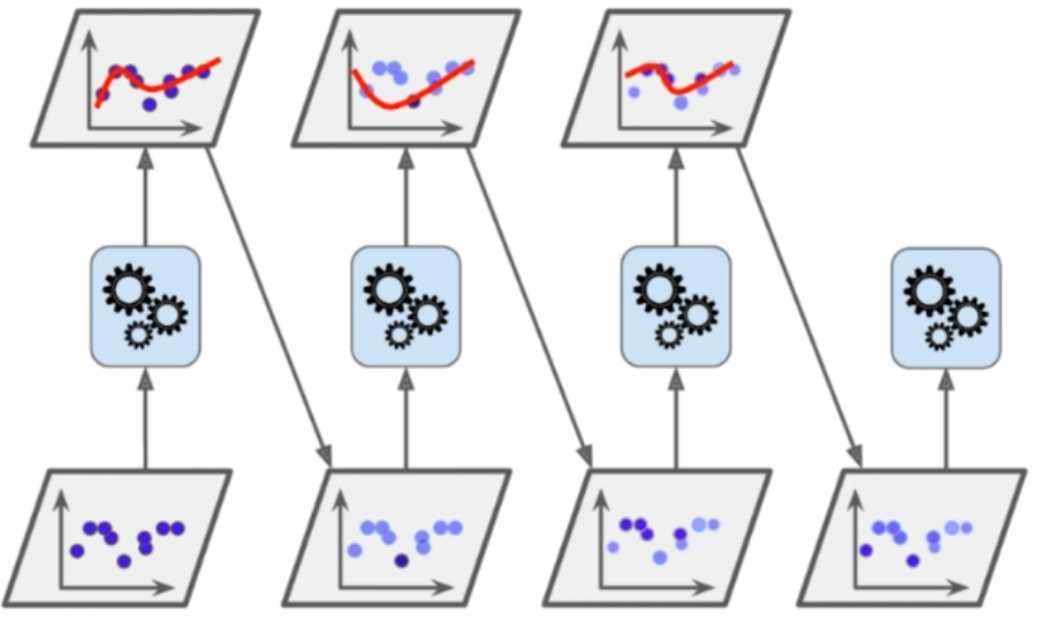
这是一个Ada Boosting,首先我们进行预测,必然会有犯错误的点,那么将没有很好预测的点做标记,变成的新的数据,所以看到蓝色的点加深了的,表示上一个模型没有很好预测的数据,然后新的模型会继续预测,对于上一个模型没有预测好的数据,相应的权值会增加。那么既然是预测,就总会犯错误,然后后续的继续重复相同的动作。因此每一个模型都在不断增强整体的效果,这就是Ada? Boosting
我们看看sklearn中的Ada Boosting
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
X, y = make_moons(n_samples=500, noise=0.3, random_state=666)
ada_clf = AdaBoostClassifier(DecisionTreeClassifier(max_depth=2),
n_estimators=500
)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
ada_clf.fit(X_train, y_train)
print(ada_clf.score(X_test, y_test)) # 0.864Gradient Boosting的原理是,训练一个模型,产生错误e1,针对e1进行训练,产生错误e2,针对e2训练,产生错误e3,最终预测结果:m1+m2+m3+······,所以说每次训练都是对前一次失误进行补偿。
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier
X, y = make_moons(n_samples=500, noise=0.3, random_state=666)
gb_clf = GradientBoostingClassifier(max_depth=2, # 这里不需要指定分类器,默认是以决策树作为基础的
n_estimators=500
)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
gb_clf.fit(X_train, y_train)
print(gb_clf.score(X_test, y_test)) # 0.896这些集成算法都可以解决回归问题
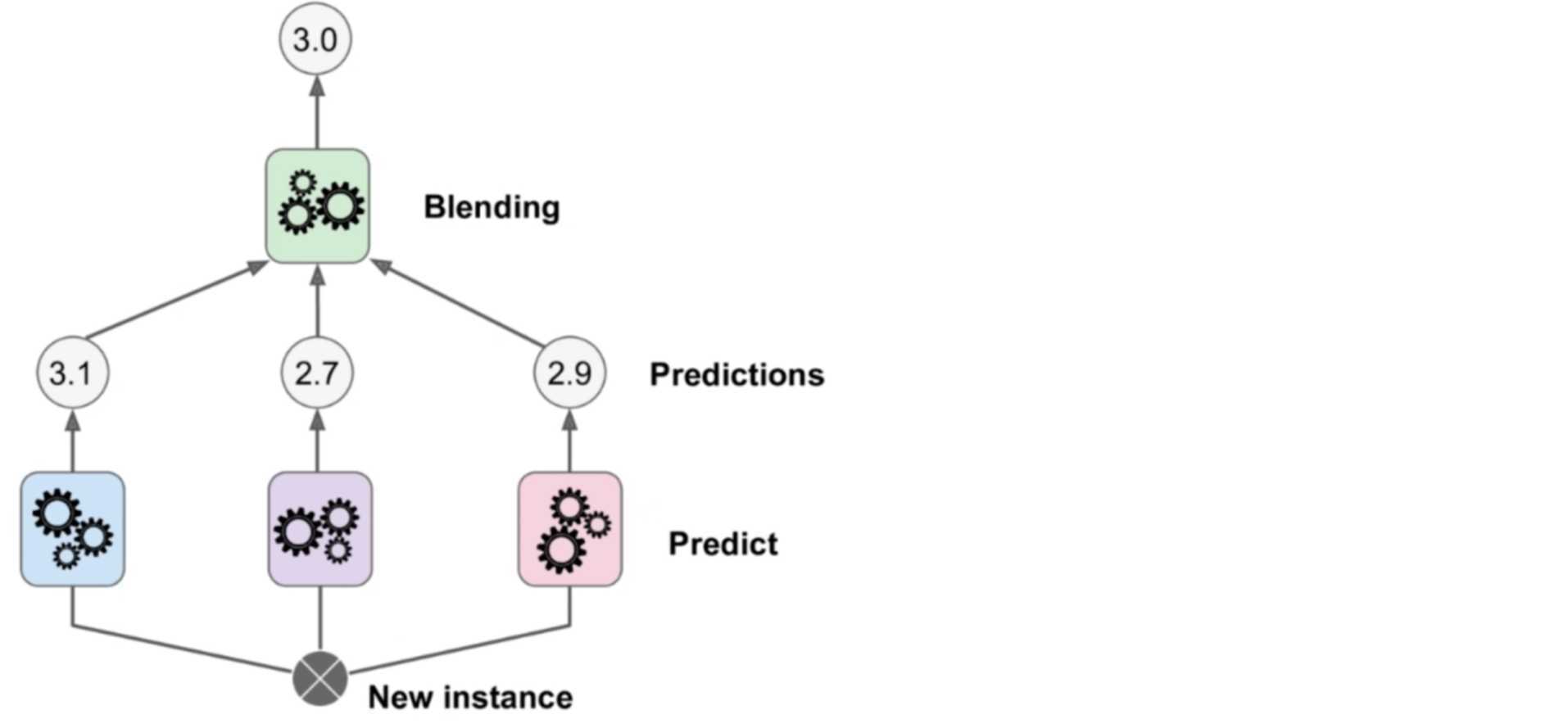
还记得之前的Voting Classifier吗?多个算法进行预测,预测出多个结果,然后对这三个结果进行综合得到结果。但是Stacking不一样,它没有直接对三个结果进行综合,而是用这个三个结果作为输入,再添加一层,预测出结果,这便是Stacking。同样Stacking既可以解决分类问题,也可以解决回归问题。
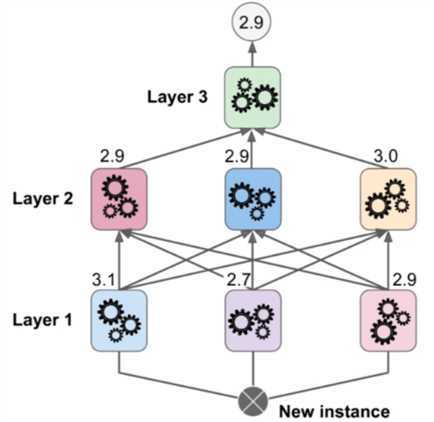
如果再复杂一些的话,我们可以分为三层。这就意味着我们需要把数据集分成三份,第一份训练第一层,第二份训练第二层,第三份训练第三层。其实看到这里就有点像是神经网络了,关于Stacking,sklearn没有提供相应的模型让我们使用,有兴趣的话可以自己实现一下。
标签:调用 观察 自己 ng-class 命名方式 记录 -o 不用 五个
原文地址:https://www.cnblogs.com/traditional/p/11524945.html