标签:ras numpy dex 技术 iat and asi scribe nan
Pandas是一个基于NumPy的库,为python提供了易用的数据结构和数据分析工具。
import pandas as pd一维的有标签的数组,可以容纳任何类型的数据。

s = pd.Series([3,-5,7,4],index=['a','b','c','d'])二维的有标签的数据结构,每一列都可能有不同的类型
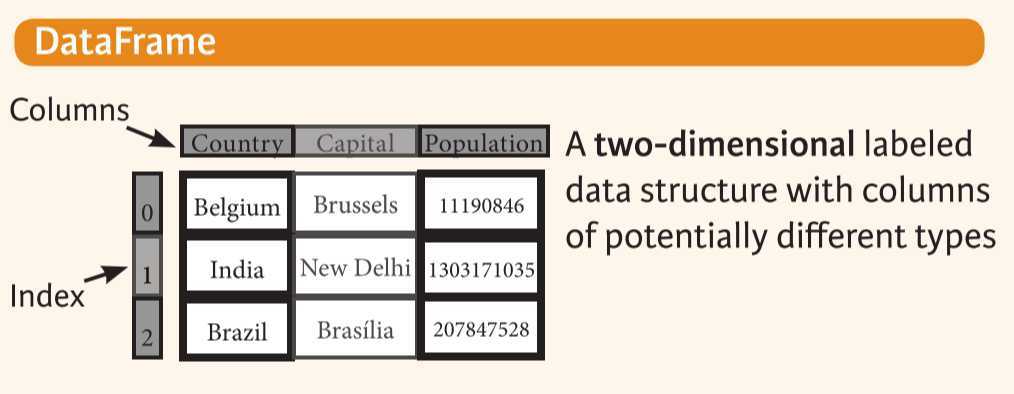
data = {'Country':['Belgium','India','Brazil'],
'Capital':['Brussels','New Delhi','Brasilia'],
'Population':[11190846,1303171035,207847528]}
df = pd.DataFrame(data,columns=['Country','Capital','Population'])# 获取Series一个元素
s['b']
# 获取DataFrame的一个子集
df[1:]
# 通过行列号获取单个数据
df.iloc[[0],[0]]
df.iat([0],[0])
# 通过行号和标签获取单个数据
df.loc[[0],['Country']]
df.at([0],['Country'])
# 通过行号和标签获取若干数据
# 获取第二行的数据和标签
df.ix[2]
# 获取某一列
df.ix[:,'Capital']
# 获取某个元素
df.ix[1,'Capital']
# 通过布尔变量索引
# 获取Series中不大于1的数据
s[~(s>1)]]
# 获取Series中小于-1或大于2的数据
s[(s<-1)|(s>2)]
# 获取人数大于12000的数据
df[df['Population']>12000] # 根据label丢弃Series中的数据
s.drop(['a','c'])
# 丢弃一列的数据
df.drop('Country',axis=1)
# 根据索引排序
df.sort_index()
# 根据某列排序
df.sort_values(by='Country')
# 将所有数据转化为序数数据
df.rank()# (行,列)
df.shape
# 显示index的范围和步长
df.index
# 显示每列的信息
df.columns
# 显示DataFrame的整体信息
df.info()
# 统计每列非零元素的个数
df.count()# 求和
df.sum()
# 累加
df.cumsum()
# 极值
df.min()/df.max()
以上操作都是在所有列上分别进行
以下操作只在数值列进行
# 显示统计量
df.describe()
# 显示均值
df.mean()
# 显示中位数
df.median()f = lambda x:x*2
# 作用在dataframe的一行或一列上
df.apply(f)
# 作用在dataframe的每个元素上
df.applymap(f)缺失列默认用NaN补齐
可以用fill_value参数指定补齐数据标签:ras numpy dex 技术 iat and asi scribe nan
原文地址:https://www.cnblogs.com/JasonBUPT/p/11610032.html