标签:环境 info shuf 效率 put 任务 流程 写入文件 分区
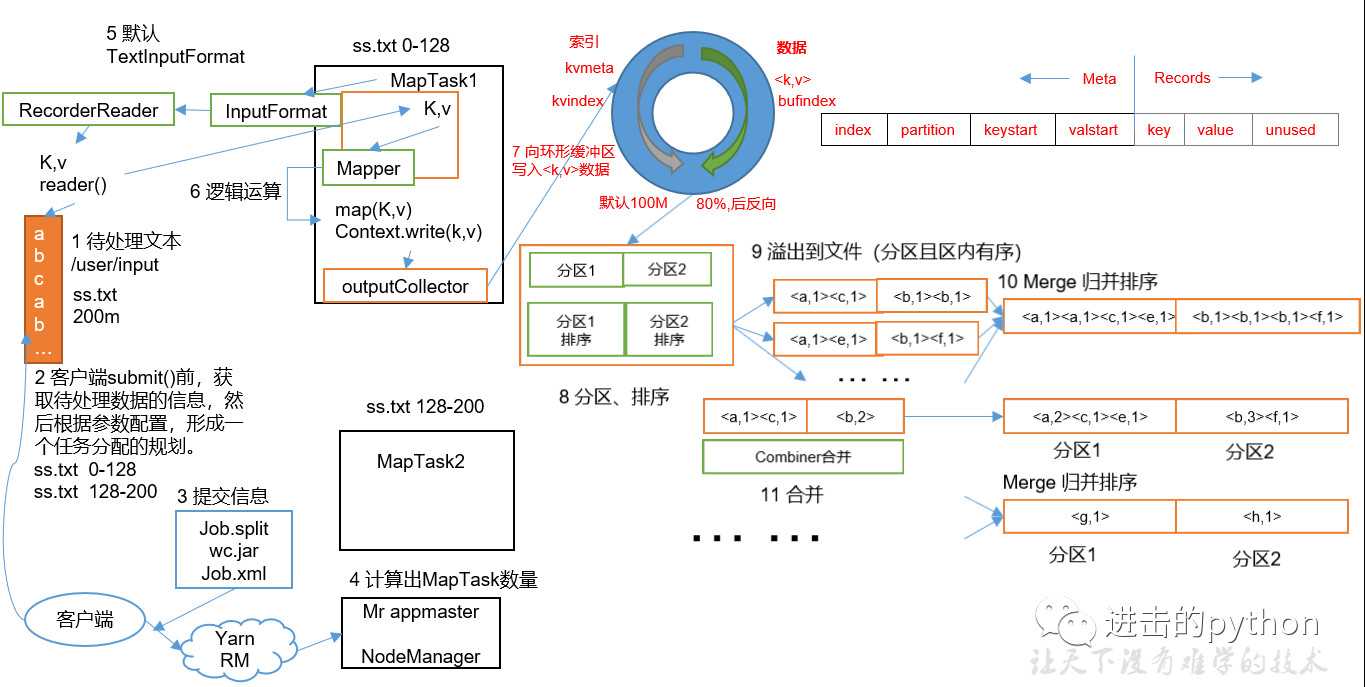
如上图所示
整个MapTask分为Read阶段,Map阶段,Collect阶段,溢写(spill)阶段和combine阶段
- Read阶段:MapTask通过用户编写的RecordReader,从输入InputSplit中解析出一个个key/value
- Map阶段:该节点主要是将解析出的key/value交给用户编写map()函数处理,并产生一系列新的key/value
- Collect收集阶段:在用户编写map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的key/value分区(调用Partitioner),并写入一个环形内存缓冲区中
- Spill阶段:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作
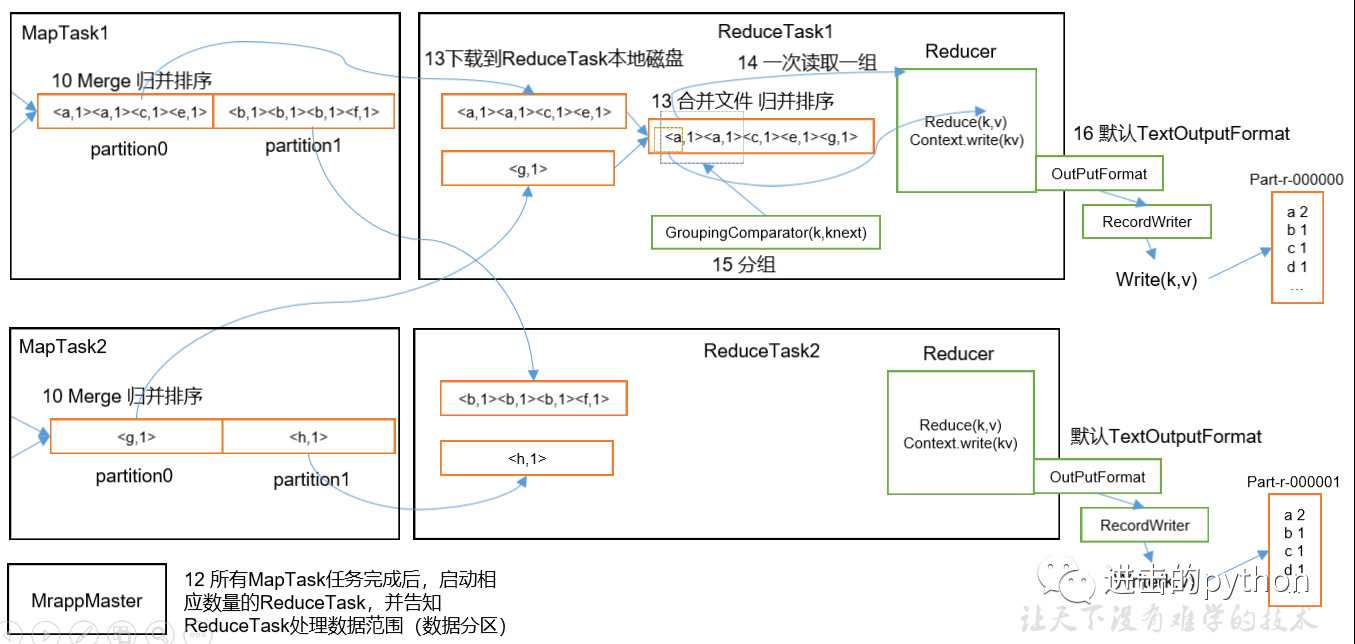
如上图所示
整个ReduceTask分为Copy阶段,Merge阶段,Sort阶段(Merge和Sort可以合并为一个),Reduce阶段。
- Copy阶段:ReduceTask从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中
- Merge阶段:在远程拷贝数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多
- Sort阶段:按照MapReduce语义,用户编写reduce()函数输入数据是按key进行聚集的一组数据。为了将key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现对自己的处理结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可
- Reduce阶段:reduce()函数将计算结果写到HDFS上
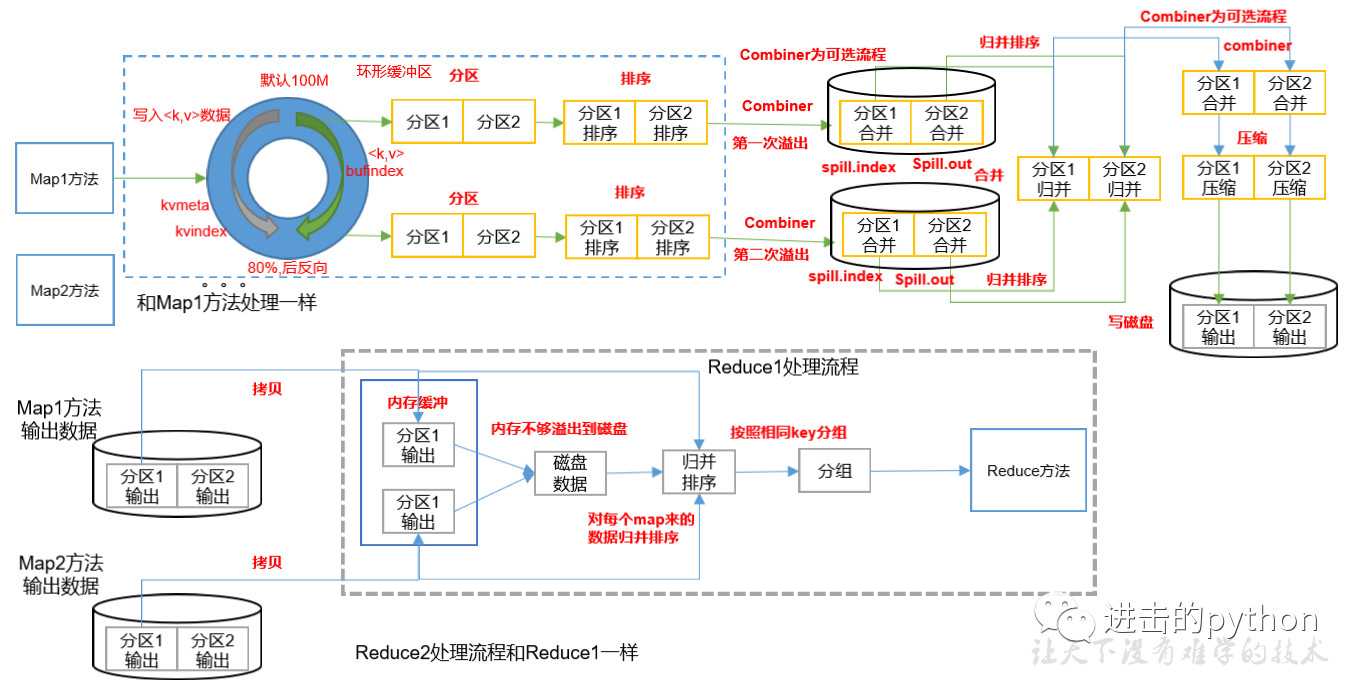
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。shuffle流程详解如下:
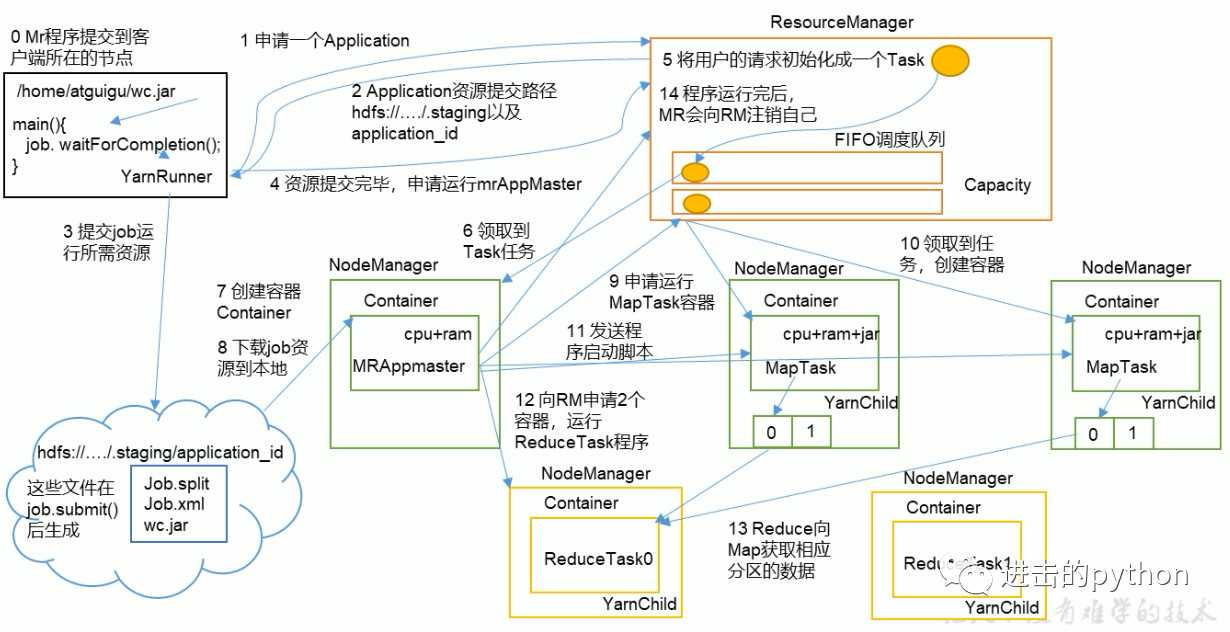
job提交全过程
进度和状态更新:
YARN中的任务将其进度和状态(包括counter)返回给应用管理器, 客户端每秒(通过mapreduce.client.progressmonitor.pollinterval设置)向应用管理器请求进度更新, 展示给用户
作业完成:
除了向应用管理器请求作业进度外, 客户端每5秒都会通过调用waitForCompletion()来检查作业是否完成。时间间隔可以通过mapreduce.client.completion.pollinterval来设置。作业完成之后, 应用管理器和Container会清理工作状态。作业的信息会被作业历史服务器存储以备之后用户核查
欢迎关注下方公众号,获取更多文章信息

标签:环境 info shuf 效率 put 任务 流程 写入文件 分区
原文地址:https://www.cnblogs.com/kocdaniel/p/11637888.html