标签:平台 调试 变量 开始 push htm 体会 art 参考
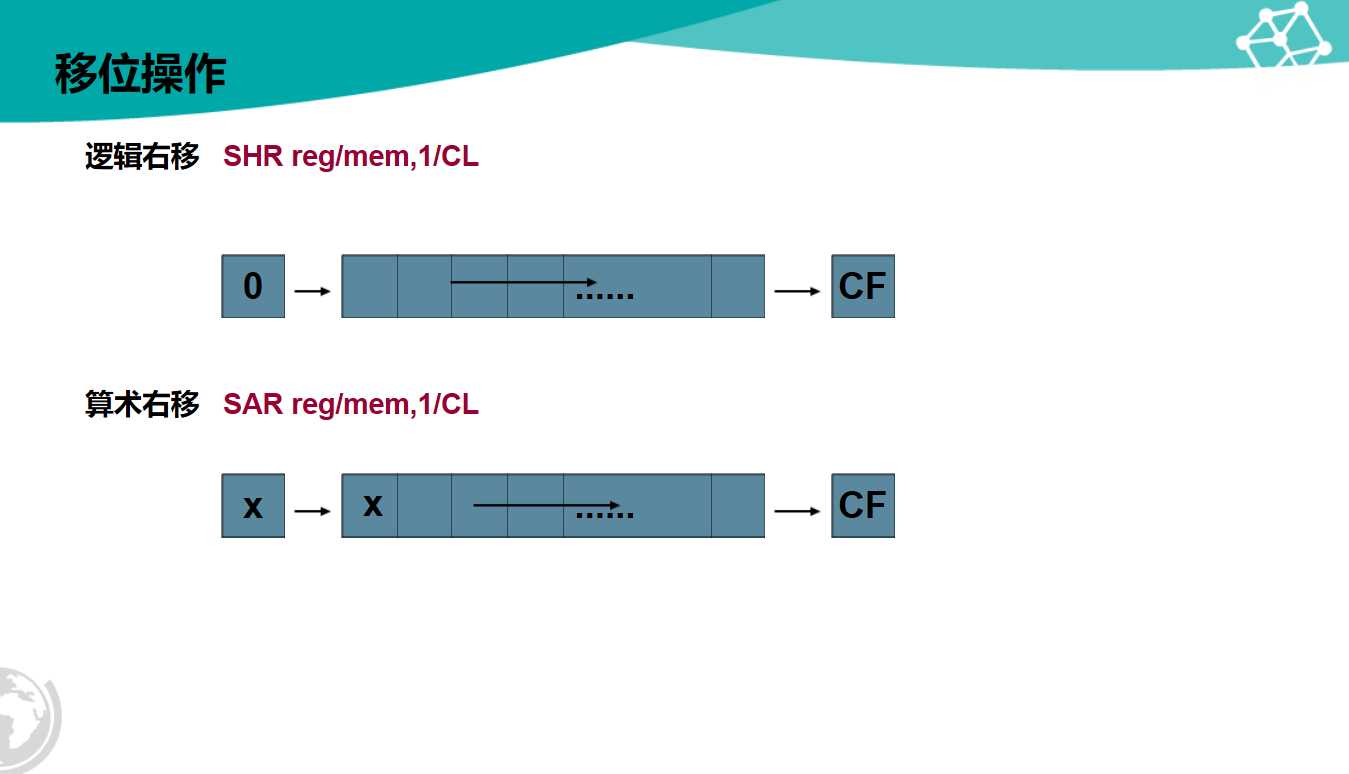
1 DOS时代的平坦模式,不区分用户空间和内核空间,很不安全 2 8086的分段模式 3 IA32的带保护模式的平坦模式
od code.o | more
od code.o > code.txt
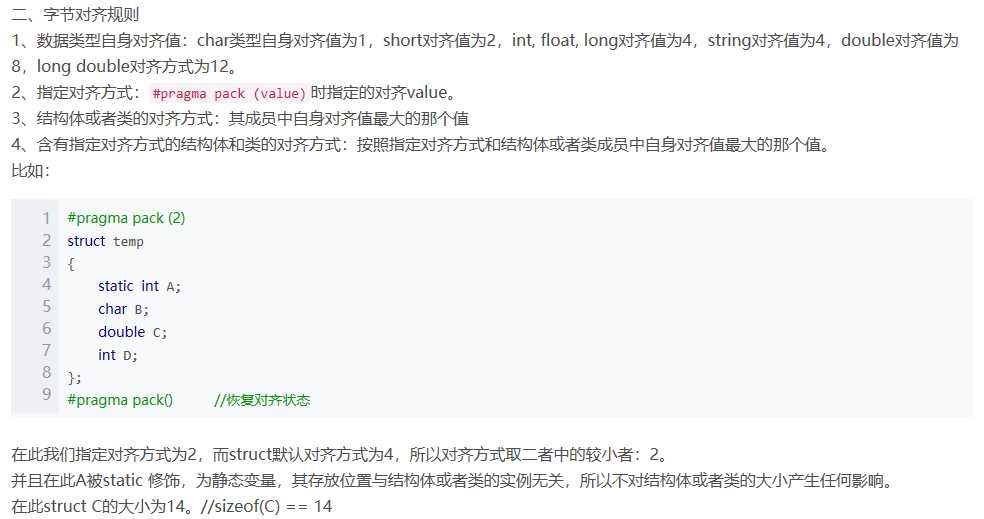
64位机器上想要得到32代码:gcc -m32 -S xxx.c MAC OS中没有objdump, 有个基本等价的命令otool Ubuntu中 gcc -S code.c (不带-O1) 产生的代码更接近教材中代码(删除"."开头的语句)
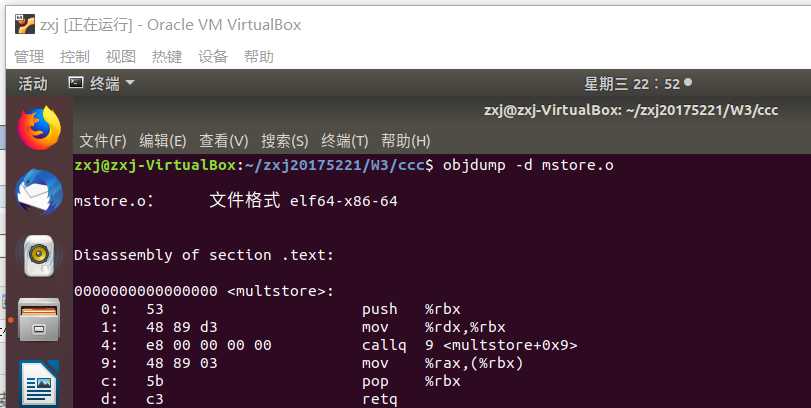
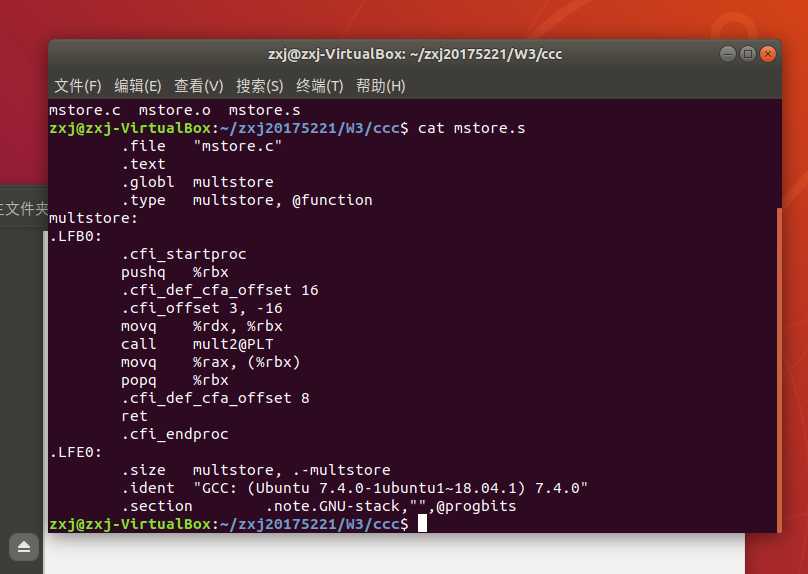
将实验楼的代码简单修改如下
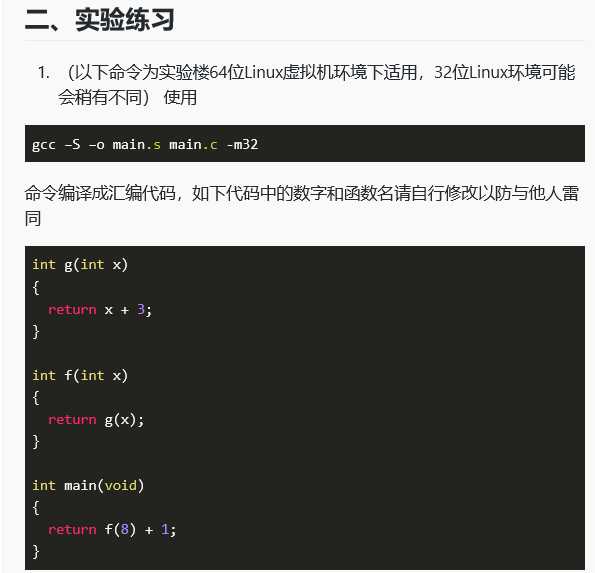
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int step1(int x)
{
return x + 3;
}
int step2(int x)
{
return step1(x);
}
int main(void)
{
printf("%d",step2(8) + 1);
return 0;
}
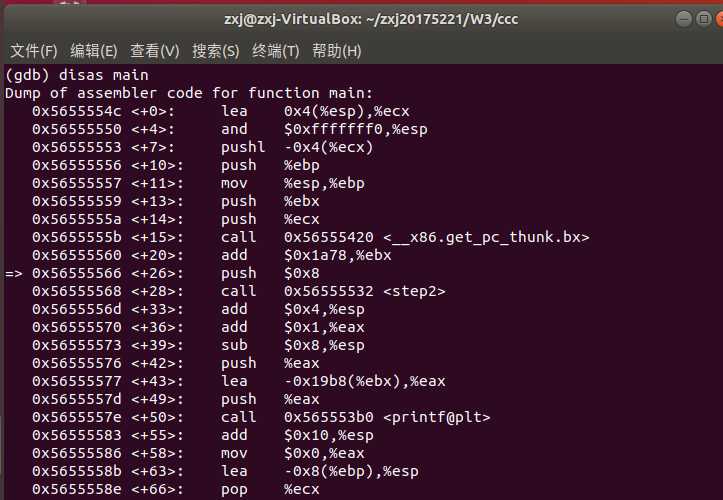
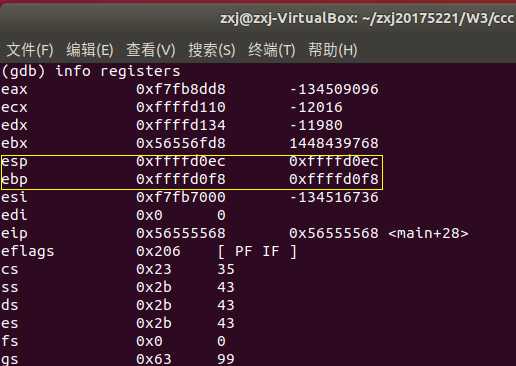
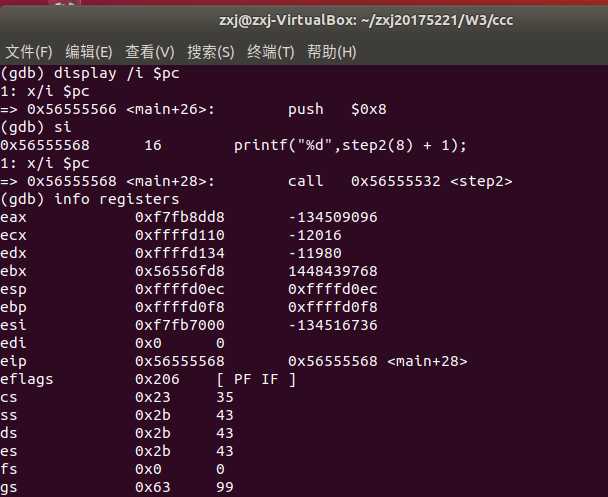
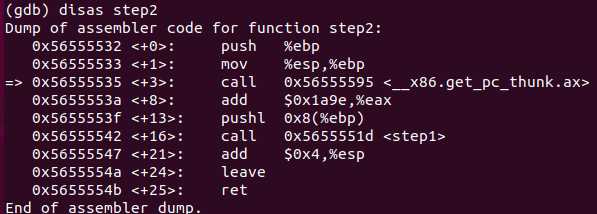
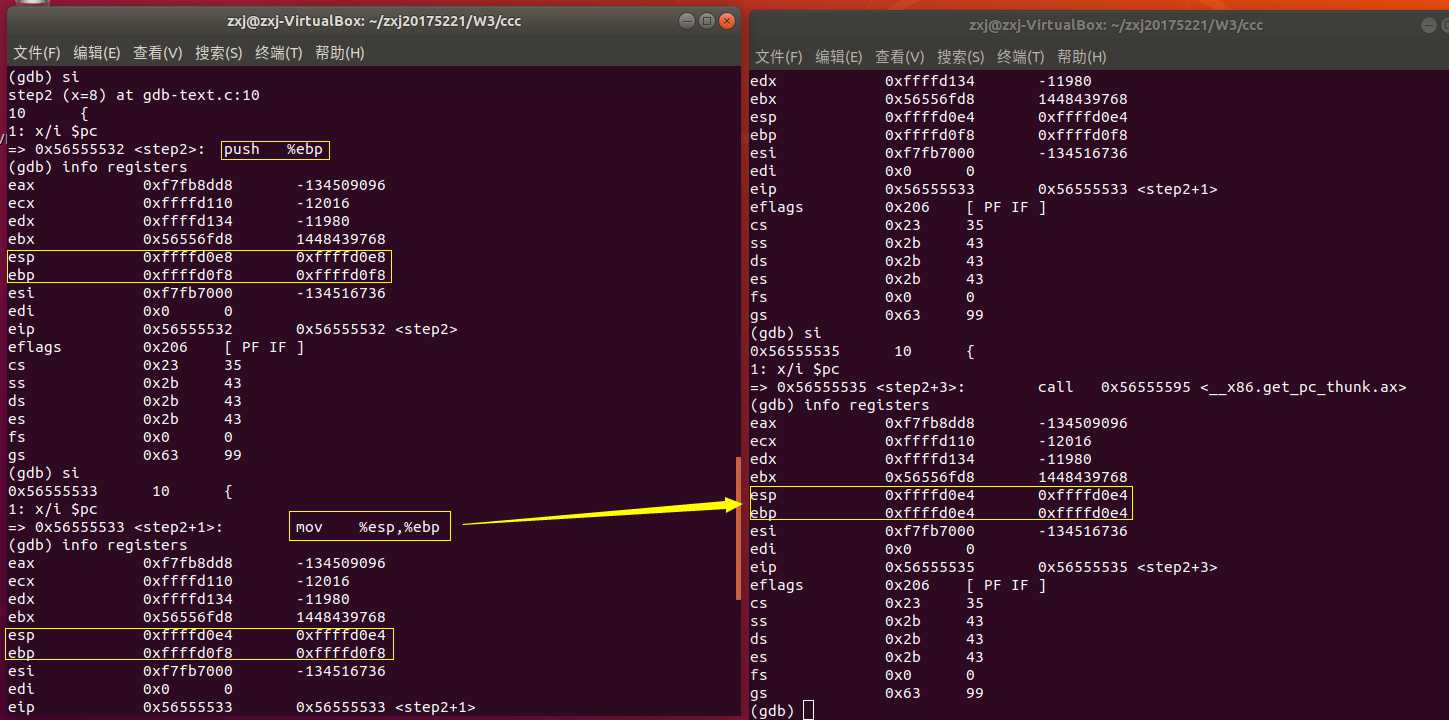
反汇编命令:disas/disass/disassemble,例如:disas main,显示main函数对应的汇编代码
查看相关信息:info,例如:info line/registers/break,查看某个line的相关信息/各寄存器的值/所有断点
开始执行:r
设置断点:b, 格式:b *内存地址
单步步过:ni
单步步入:si
显示某寄存器的值:display 例如:display /x $eax
查看变量值:p 格式: p 变量名
PPT中有gcc -Og -o p p1.c p2.c 命令,且说明 -Og 告诉编码器采用的等级,一般认为第二级优化-O2是较好的选择。那么,①-O2是最高等级的优化了吗?②优化等级是越高越好吗?③这里的-Og怎么理解呢 ?


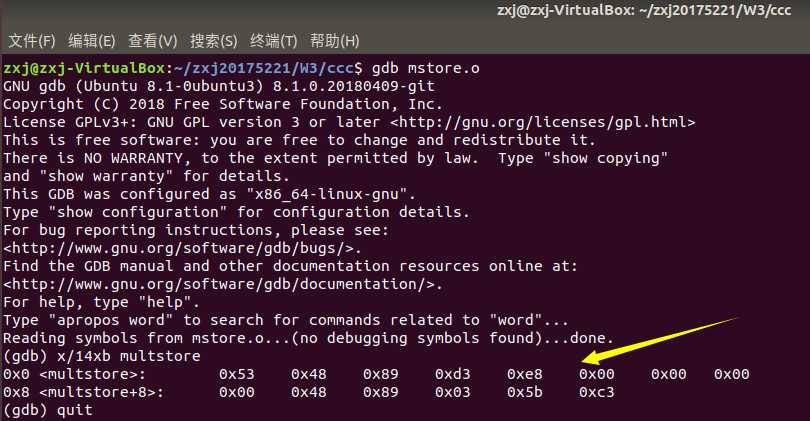
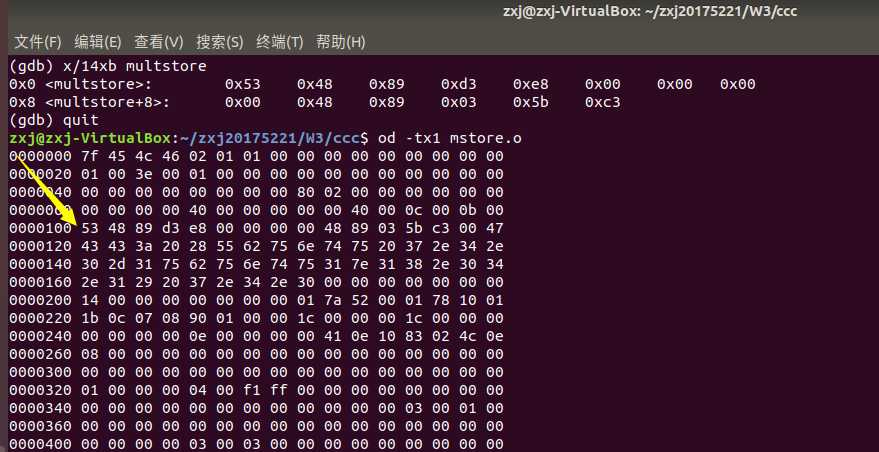
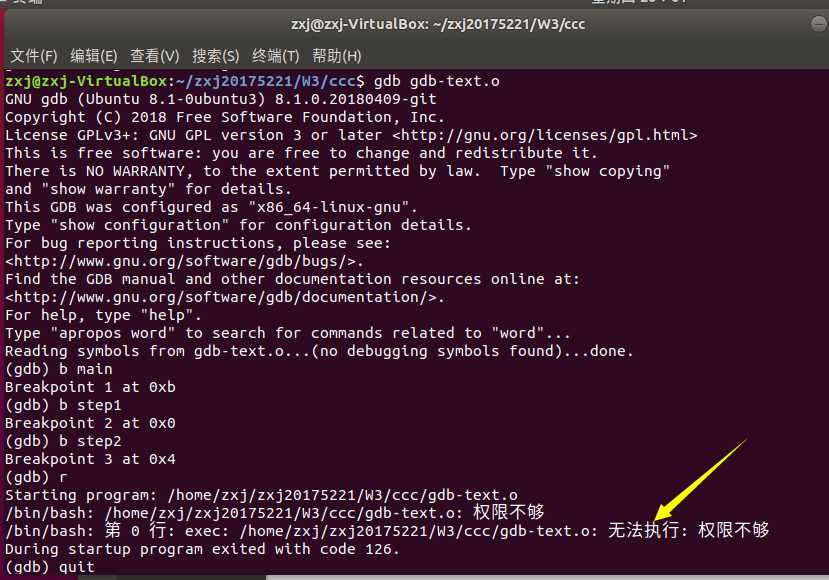
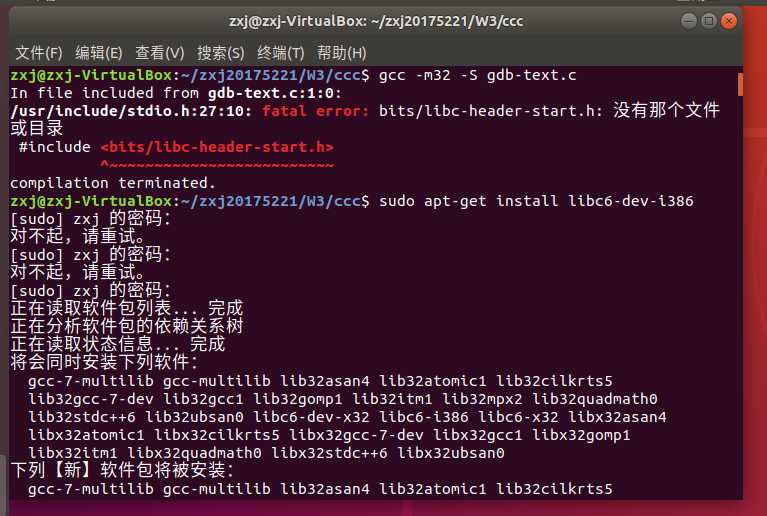
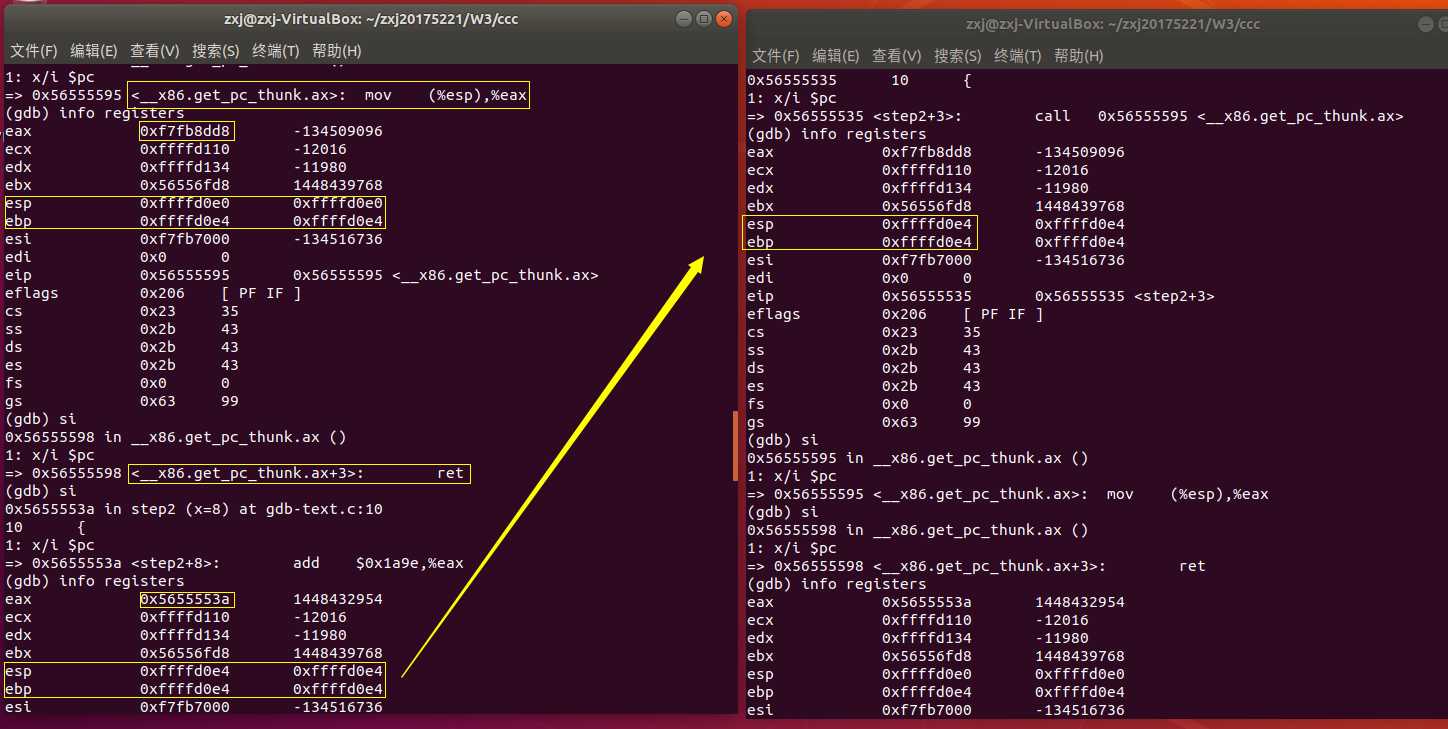
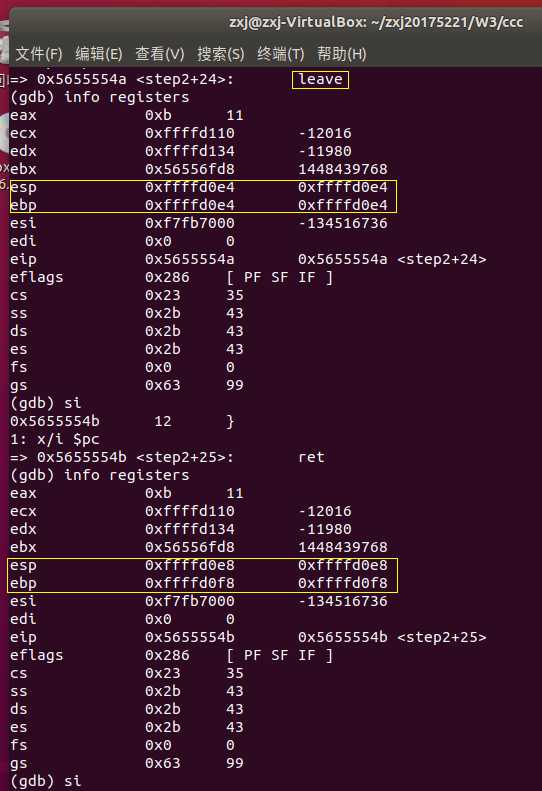
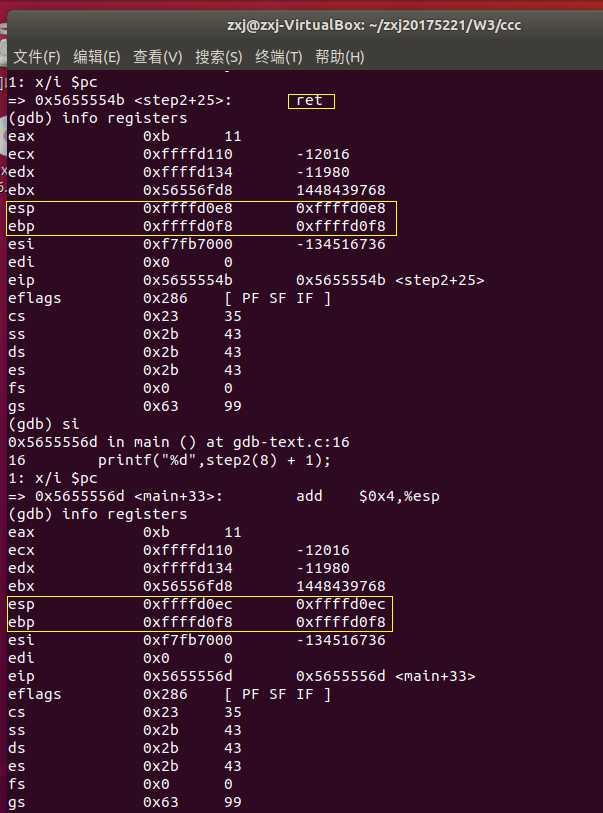
通过这次简单的GDB调试,才知道即使在c中短短的一个赋值语句,一个返回语句,在汇编语言中都可能包含着许多出栈,压栈,传参等操作。只是前人做了许多努力,我们现在才轻松了许多。但不代表我们就可以对汇编语言视若无睹,对汇编语言的学习,重点还是要加强对它的理解,多动手实践应用它
无
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 53/53 | 1/1 | 20/20 | |
| 第二周 | 200/253 | 2/3 | 21/20 | |
| 第三周 | 100/353 | 1/4 | 30/50 |
尝试一下记录「计划学习时间」和「实际学习时间」,到期末看看能不能改进自己的计划能力。这个工作学习中很重要,也很有用。 耗时估计的公式 :Y=X+X/N ,Y=X-X/N,训练次数多了,X、Y就接近了。
计划学习时间:XX小时
实际学习时间:XX小时
改进情况:
(有空多看看现代软件工程 课件 软件工程师能力自我评价表)
标签:平台 调试 变量 开始 push htm 体会 art 参考
原文地址:https://www.cnblogs.com/zxja/p/11614028.html