标签:分析 包括 参与 节点 十六 流程 NPU 数据保存 溢出
Redis 的复制功能分为同步( sync )和命令传播( command propagate )两个步骤:
Redis 使用 psync 命令完成主从数据同步,同步过程分为:全量复制和部分复制。
全量复制:一般用于初次复制场景,它会把主节点全部数据一次性发送给从节点发送给从节点,当数据量较大时,会对主从节点和网络造成很大的开销。
部分复制:用于处理在主从复制中因网络闪断等原因造成的网络丢失场景,当从节点再次连接上主节点后,如果条件允许,主节点会补发丢失数据给从节点。因为补发的数据远远小于全量数据,可以有效避免全量复制的过高开销。
psync 命令运行需要以下组件支持:
参与复制的从节点都会维护自身复制偏移量。主节点在处理完写命令后,会把命令的字节长度做累加记录,统计在 info replication 中的 masterreploffset 指标中。 从节点在接收到主节点发送的命令后,也会累加记录自身的偏移量,并且会每秒钟上报自身的复制偏移量给主节点。 通过对比主从节点的复制偏移量,可以判断主从节点数据是否一致。
复制积压缓冲区是保存在主节点的一个固定长度的队列,默认大小为 1MB,当主节点有连接的从节点时被创建。主节点响应写命令时,不但会把命令发送给从节点,还会写入复制积压缓冲区中。
复制积压缓冲区大小有限,只能保存最近的复制数据,用于部分复制和复制命令丢失时的数据补救。
每个 Redis 节点启动后都会动态分配一个 40 位的十六进制字符串作为运行 ID。运行 ID 的主要作用是用来唯一标识 Redis 节点,比如说从节点保存主节点的运行 ID 来识别自己正在复制的时哪个主节点。
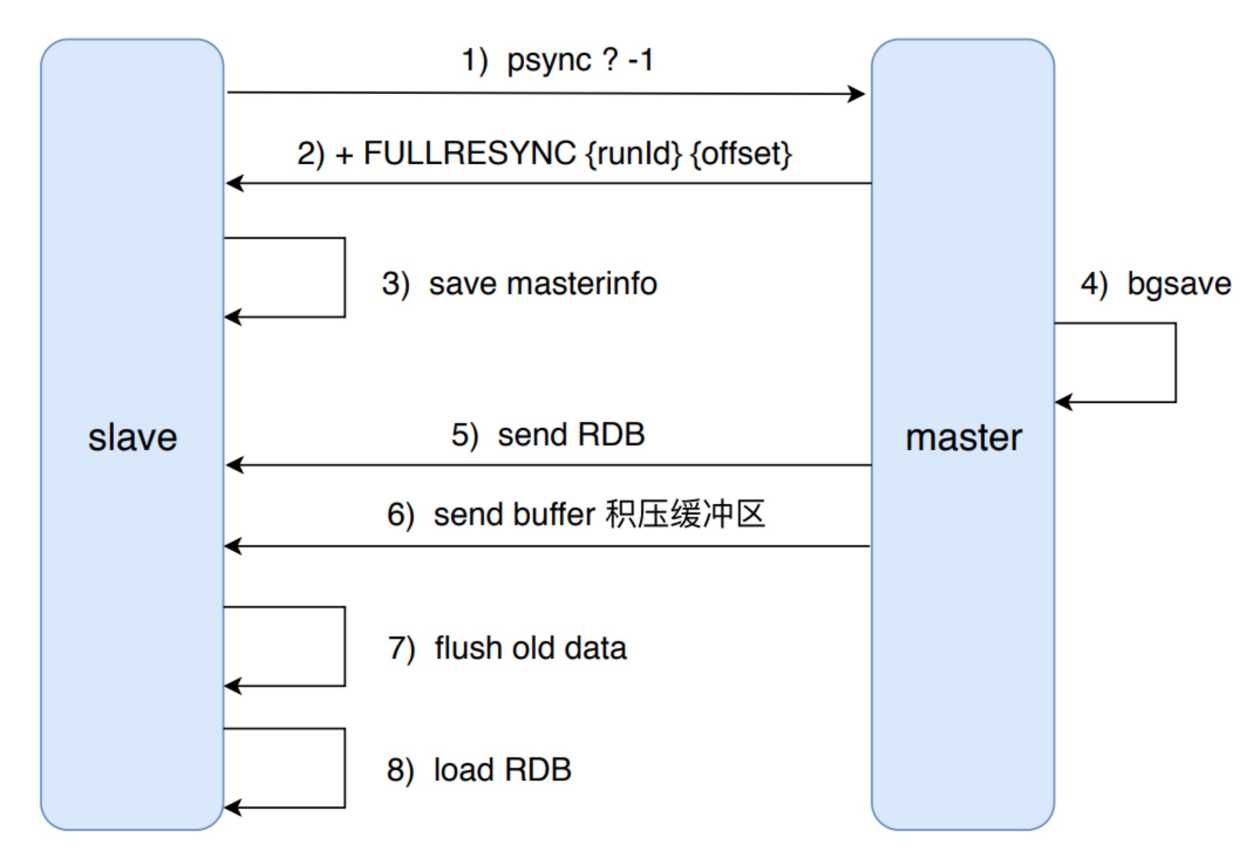
slaveof 命令的执行需要注意,对于数据量较大的主节点,比如生成的 RDB 文件超过 6GB 以上时要格外小心。如果传输 RDB 的时间超过 repl-timeout 所配置的值,从节点将发起接收 RDB 文件并清理已经下载的临时文件,导致全量复制失败。
如果主节点创建和传输 RDB 的时间过长,可能会出现主节点复制客户端缓冲区溢出。默认配置为 client-output-buffer-limit slave 256MB 64MB 60,如果60s内缓冲区消耗持续大于64MB或者直接超过256MB时,主节点将直接关闭复制客户端连接,造成全量同步失败。
通过分析全量复制的所有流程,读者会发现全量复制是一个非常耗时费力的操作。它时间开销主要包括:
全量同步过程中不仅会消耗大量时间,还会进行多次持久化相关操作和网络数据传输,这期间会大量消耗主从节点所在服务器的 CPU、内存和网络资源。所以,除了第一次复制是采用全量同步无法避免,其他场景应该规避全量复制,采取部分同步功能。
部分复制主要是 Redis 针对全量复制的过高开销做出的一种优化措施,使用 psync {runId} {offset} 命令实现。当从节点正在复制主节点时,如果出现网络闪断或者命令丢失等异常情况时,从节点会向主节点要求补发丢失的命令数据,如果主节点的复制积压缓冲区存在这部分数据则直接发送给从节点,这样就保证了主从节点复制的一致性。补发的这部分数据一般远远小于全量数据,所以开销很小。
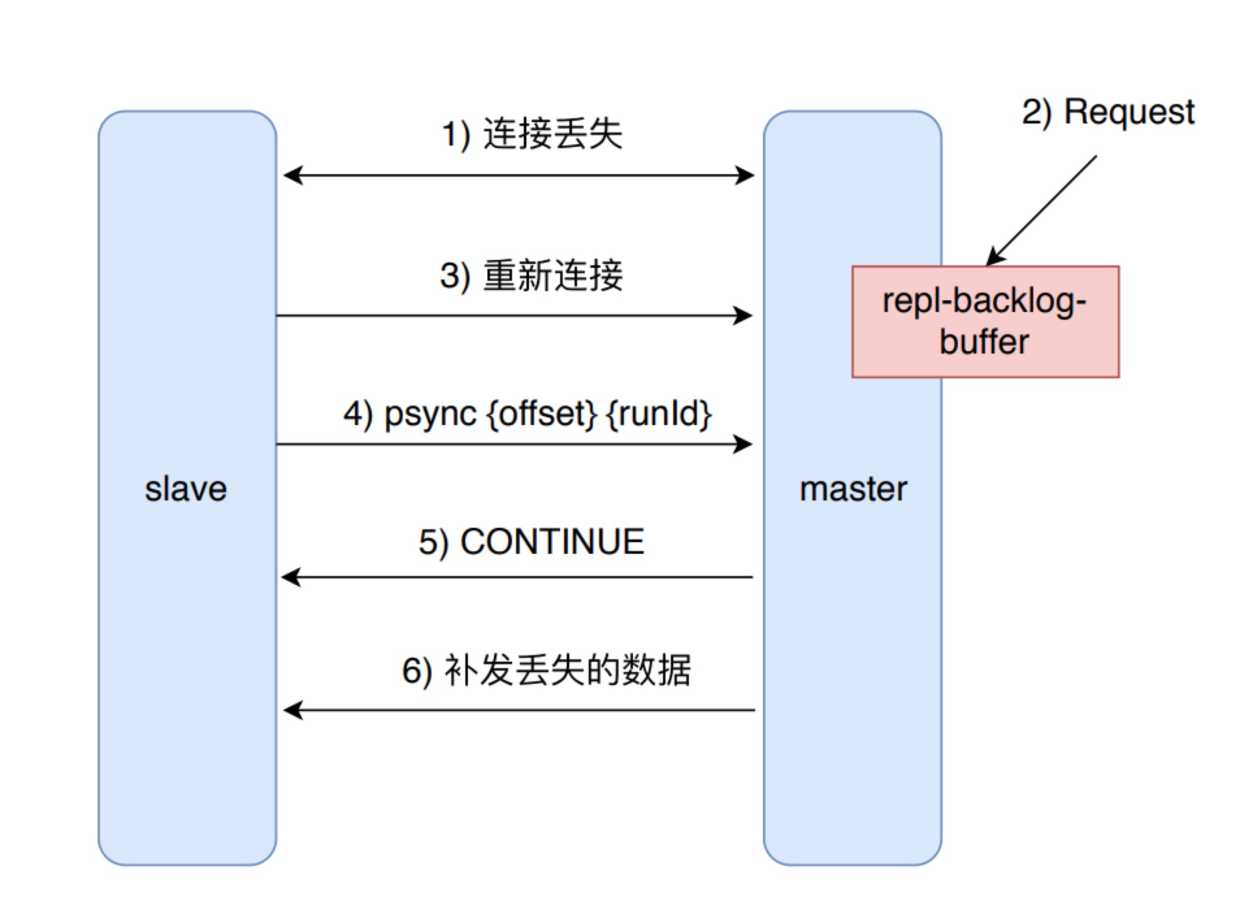
2) 主从连接中断期间主节点依然响应命令,但因复制连接中断命令无法发送给从节点,不过主节点内部存在复制积压缓冲区( repl-backlog-buffer ),依然可以保存最近一段时间的写命令数据,默认最大缓存 1MB。
3) 当主从节点网络恢复后,从节点会再次连上主节点。
4) 当主从连接恢复后,由于从节点之前保存了自身已复制的偏移量和主节点的运行ID。因此会把它们作为 psync 参数发送给主节点,要求进行补发复制操作。
5) 主节点接到 psync 命令后首先核对参数 runId 是否与自身一致,如果一致,说明之前复制的是当前主节点;之后根据参数 offset 在自身复制积压缓冲区查找,如果偏移量之后的数据存在缓冲区中,则对从节点发送 +CONTINUE 响应,表示可以进行部分复制。
6) 主节点根据偏移量把复制积压缓冲区里的数据发送给从节点,保证主从复制进入正常状态。
主从节点在建立复制后,它们之间维护着长连接并彼此发送心跳命令,如下图所示。
主从心跳判断机制如下所示:
replconf 命令不仅能实时监测主从节点网络状态,还能上报从节点复制偏移量。主节点会根据从节点上传的偏移量检查复制数据是否丢失,如果从节点数据丢失,再从主节点的复制缓存区中拉取丢失的数据发送给该从节点。
主节点不但负责数据读写,还负责把写命令同步给从节点。写命令的发送过程是异步完成,也就是说主节点自身处理完写命令后直接返回给客户端,并不等待从节点复制完成。
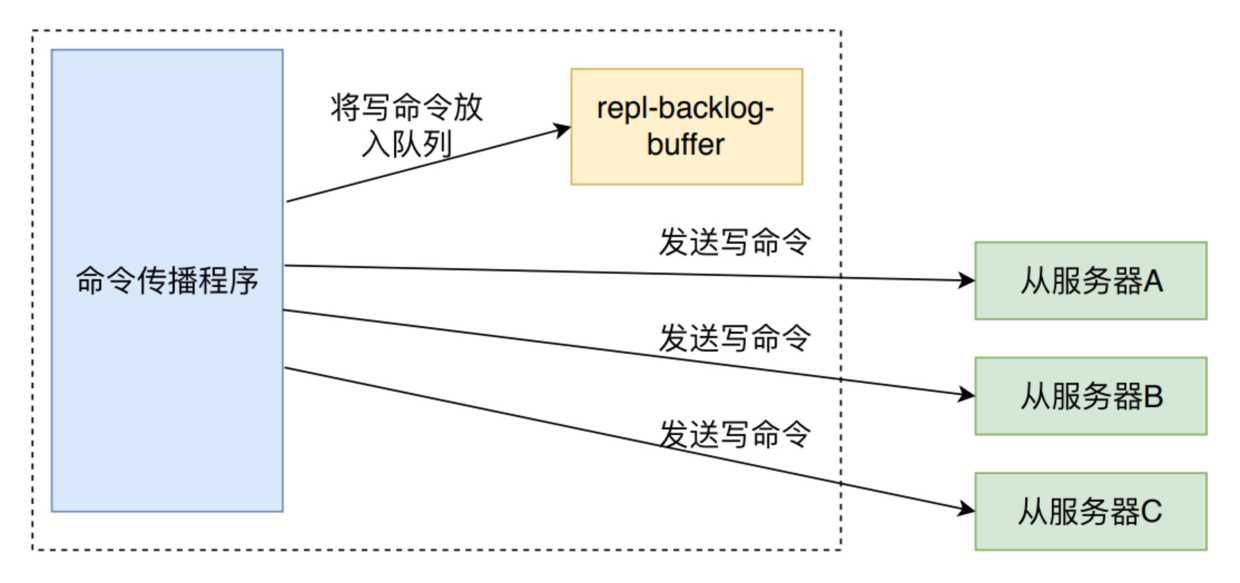
这个异步过程由命令传播来处理,它不仅会将写命令发送给所有从服务器,还会将写命令入队到复制积压缓冲区里边。

标签:分析 包括 参与 节点 十六 流程 NPU 数据保存 溢出
原文地址:https://www.cnblogs.com/remcarpediem/p/11701234.html