标签:垃圾回收 获取 永久代 种类型 就是 垃圾收集器 tps 变量 能力
目录
? 程序在运行过程中是不断申请内存,释放内存,如果程序只是申请没有释放就会引起内存泄漏内存不足等问题。在C语言、C++中,程序员需要手动的释放内存,如果程序员粗心忘记回收,就会导致程序bug,在Java中,JVM提供自动回收内存机制GC(内存回收器),减少程序员的工作量和减低由于人为导致内存问题。
? 将内存中不再被使用的对象进行回收,GC中用于回收的方法称为收集器,由于GC需要消耗一些资源和时间,Java在对对象的生命周期特征进行分析后,按照新生代、旧生代的方式来对对象进行收集,以尽可能的缩短GC对应用造成的暂停。
? GC回收中的内存分为新生代和老年代, 新生代与老年代的比例的值为 1:2 ( 该值可以通过参数 –XX:NewRatio 来指定 ) 。
新生代
新生代是刚刚被释放的内存存放的地方,分为 Eden、From Survivor、To Survivor三个区(8:1:1) ,一般情况,from Survior和to Survivor有一个空闲(复制算法决定的)。
老年代
? 主要存放程序中年龄较大和需要占用大量连续内存空间的对象。
? GC根据回收的内存分为两种类型:新生代 GC(Minor GC)和老年代 GC(Major GC / Full GC)
新生代 GC(Minor GC):指发生在新生代的垃圾收集动作,因为 Java 对象大多都具
备朝生夕灭的特性,所以 Minor GC 非常频繁,一般回收速度也比较快。
老年代 GC(Major GC / Full GC):指发生在老年代的 GC,出现了 Major GC,经常
会伴随至少一次的 Minor GC(但非绝对的,在 ParallelScavenge 收集器的收集策略里
就有直接进行 Major GC 的策略选择过程) 。MajorGC 的速度一般会比 Minor GC 慢 10
倍以上。
Minor GC触发机制:
当年轻代满时就会触发Minor GC,这里的年轻代满指的是Eden代满,Survivor满不会引发GC
Full GC触发机制:
当年老代满时会引发Full GC,Full GC将会同时回收年轻代、年老代,
当永久代满时也会引发Full GC,会导致Class、Method元信息的卸载
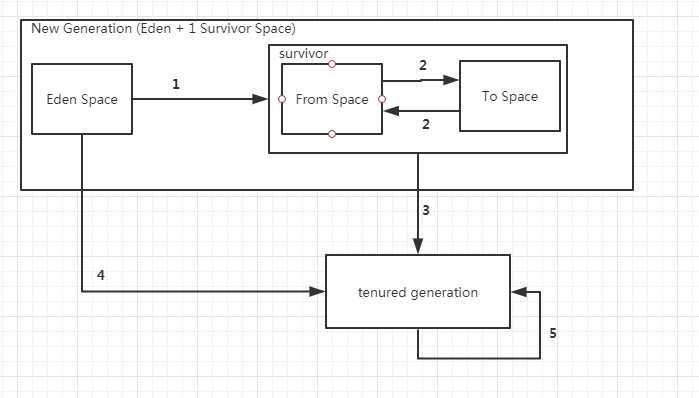
当Minor GC被触发的时候,new Generation被进行,可能触发1、2、3、4四种情况。
1)经过minorGC后,eden区的数据如果还存活,执行1或者4。当eden的对象比较大或者survicor已经满了,执行4,直接永久代;否则操作1,进入则标记回收次数,数据进入survior区,进入from还是to,由survicor决定;
2)survicor区的回收一般是使用标记复制算法,存活的数据从from进入to,或者to进入from,同时GC回收标记次数会jia1,当标记次数达到一定次数,触发3,对象进入老年代;
当full GC时,会触发所有的GC操作,老年代的自我回收是5。
? 这个算法的基本思想是通过一系列称为“GC Roots”的对象作为起始点,从这些节点向下搜索,搜索所走过的路径称为引用链,当一个对象到GC Roots没有任何引用链(即GC Roots到对象不可达)时,则证明此对象是不可用的。 也叫可达性分析算法(找到一个可以作为入口的对象,顺藤摸瓜标记).
目前Java中可以作为GC ROOT的对象有:
虚拟机栈中引用的对象(本地变量表)
方法区中静态属性引用的对象
方法区中常量引用的对象
本地方法栈中引用的对象(Native对象)
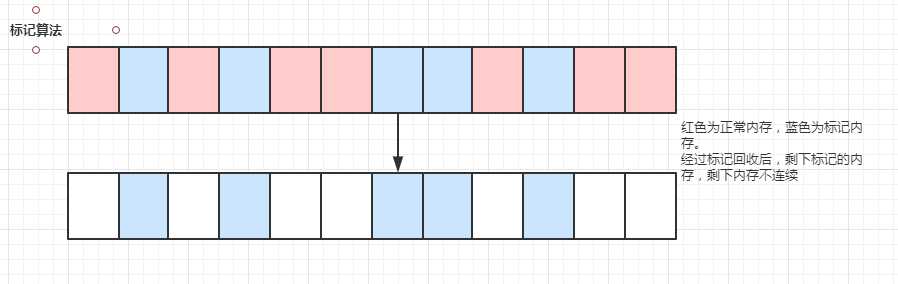
? 该算法是基于根搜索算法上实现的,搜索到的对象添加标记,回收没有标记的对象。
? 会导致内存碎片问题。
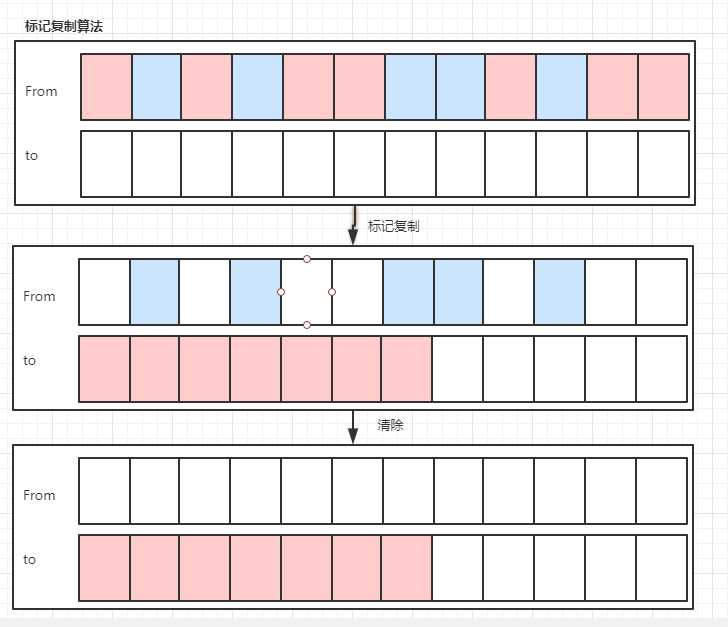
? 根据根搜索标记内存,把标记的内存复制到另一块空白的区域,标记完了清除没有移动的内存碎片,保证了剩下的内存是连续的,缺点需要的内存空间比较大(一倍),空间浪费;适合用在新生代的回收,由于新生代的GC回收比较频繁,内存的使用时间还是比较多的,这样做也提高效率。
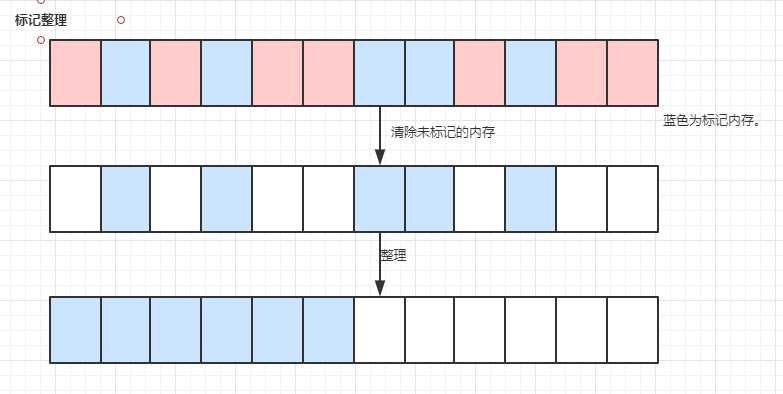
在2的基础上,对内存碎片进行整理,整理成一个连续的内存,缺点是没有标记复制算法效率高,优点没有占用多余内存。适合老年代GC次数低的GC收集器。
什么是引用计数算法:
那为什么主流的Java虚拟机里面都没有选用这种算法呢?
其中最主要的原因是它很难解决对象之间相互循环引用的问题。
引用计数法和根搜索算法可以参考下面文章
参考https://www.jianshu.com/p/fcc09b2eb006
不管是什么算法,都会根据引用的不同类型进行不同的操作,java的引用类型中分为四种:
强引用:
通常我们通过new来创建一个新对象时返回的引用就是一个强引用,若一个对象通过一系列强引用可到达,它就是强可达的(strongly reachable),那么它就不被回收;
String s = new String();弱引用:内存不足回收
弱引用简单来说就是将对象留在内存的能力不是那么强的引用。使用Weak Reference,垃圾回收器会帮你来决定引用的对象何时回收并且将对象从内存移除。
被下一个GC周期直接回收
WeakReference<Zoo> weakZoo = new WeakReference<Zoo>(zoo);
weakZoo.get();软引用(缓存场景)SoftReference:
SoftReference<Zoo> weakZoo = new SoftReference<Zoo>(zoo);? 软引用和弱引用的区别在于,若一个对象是弱引用可达,无论当前内存是否充足它都会被回收,而软引用可达的对象在内存不充足时才会被回收,因此软引用要比弱引用“强”一些;
内存不足时被回收
虚引用PhantomReference:
PhantomReference<Zoo> weakZoo = new PhantomReference<Zoo>(zoo);? 虚引用是Java中最弱的引用,那么它弱到什么程度呢?它是如此脆弱以至于我们通过虚引用甚至无法获取到被引用的对象,虚引用存在的唯一作用就是当它指向的对象被回收后,虚引用本身会被加入到引用队列中,用作记录它指向的对象已被回收。
根据引用类型,对可达性的级别也进行划分。
Serial (-XX:+UseSerialGC)
? Serial收集器是一款年轻代的垃圾收集器,使用标记-复制垃圾收集算法,是一种串行收集器。它是一款发展历史最悠久的垃圾收集器。Serial收集器只能使用一条线程进行垃圾收集工作,并且在进行垃圾收集的时候,所有的工作线程都需要停止工作,等待垃圾收集线程完成以后,其他线程才可以继续工作。
ParNew(-XX:+UseParNewGC)
? ParNew垃圾收集器是Serial收集器的多线程版本,使用标记-复制垃圾收集算法,,是一种并行收集器。为了利用CPU多核多线程的优势,ParNew收集器可以运行多个收集线程来进行垃圾收集工作。这样可以提高垃圾收集过程的效率。
ParallelScavenge(-XX:+UseParallelGC)
? Parallel Scavenge收集器是是一款年轻代的收集器,它使用标记-复制垃圾收集算法。和ParNew一样,它也会一款多线程的垃圾收集器,但是它又和ParNew有很大的不同点。
Parallel Scavenge收集器和其他收集器的关注点不同。其他收集器,比如ParNew和CMS这些收集器,它们主要关注的是如何缩短垃圾收集的时间。而Parallel Scavenge收集器关注的是如何控制系统运行的吞吐量。这里说的吞吐量,指的是CPU用于运行应用程序的时间和CPU总时间的占比,吞吐量 = 代码运行时间 / (代码运行时间 + 垃圾收集时间)。如果虚拟机运行的总的CPU时间是100分钟,而用于执行垃圾收集的时间为1分钟,那么吞吐量就是99%。
SerialOld(-XX:+UseSerialOldGC)
? Serial Old收集器是Serial收集器的老年代版本,它也是一款使用"标记-整理"算法的单线程的垃圾收集器。这款收集器主要用于客户端应用程序中作为老年代的垃圾收集器,也可以作为服务端应用程序的垃圾收集器,当它用于服务端应用系统中的时候,主要是在JDK1.5版本之前和Parallel Scavenge年轻代收集器配合使用,或者作为CMS收集器的后备收集器。
ParallelOld(-XX:+UseParallelOldGC)
? Parallel Old收集器是Parallel Scavenge收集器的老年代版本,使用"标记-整理"算法,多核,自适应调整。这个收集器是在JDK1.6版本中出现的,所以在JDK1.6之前,新生代的Parallel Scavenge只能和Serial Old这款单线程的老年代收集器配合使用。Parallel Old垃圾收集器和Parallel Scavenge收集器一样,也是一款关注吞吐量的垃圾收集器,和Parallel Scavenge收集器一起配合,可以实现对Java堆内存的吞吐量优先的垃圾收集策略。
CMS(-XX:+UseConcMarkSweepGC) 并发收集器(标记清除)
? CMS收集器是目前老年代收集器中比较优秀的垃圾收集器。CMS是Concurrent Mark Sweep,从名字可以看出,这是一款使用"标记-清除"算法的并发收集器。CMS垃圾收集器是一款以获取最短停顿时间为目标的收集器。由于现代互联网中的应用,比较重视服务的响应速度和系统的停顿时间,所以CMS收集器非常适合在这种场景下使用。
G1 收集器 ( -XX:+UseG1GC )
? G1是一款面向服务端应用的垃圾收集器,是从JDK1.7开始支持的,是一款并发收集器,目标是替换其他收集器。这款收集器是使用标记复制算法,取消了新生代和老年代的物理划分,同时还有个和CMS一样的优点:可预测停顿。
标签:垃圾回收 获取 永久代 种类型 就是 垃圾收集器 tps 变量 能力
原文地址:https://www.cnblogs.com/yz-yang/p/11751845.html