标签:表示 ice 标记 odi alt 就是 rap coding external
决策树:
|
决策树算法
|
算法 描述
|
|---|---|
| C4.5算法 | C4.5决策树生成算法相当于ID3算法的重要改进是使用信息增益率来选择节点属性.C4.5算法可疑克服ID3算法存在的不足:ID3算法只适用于离散的描述属性,而C4.5算法即能够处理离散的描述性,也可以处理连续的描述属性 |
| CART算法 | CART决策树是一种十分有效的非参数分类和回归方法,通过构建树,修剪树,评估树来构建一个二叉树.当终结点是连续变量时,该树为回归树,当终结点是分类变量,该树为分类树 |
| ID3算法 | 其核心的是在决策树的各级节点上,使用信息增益方法作为属性的选择标准,来帮助确定生成每个节点是所应采用的合适属性 |
ID3算法简介及基本原理
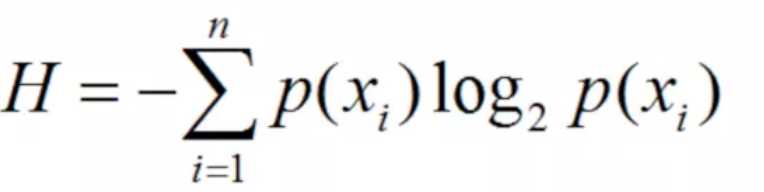
序号,天气,是否周末,是否促销,销量 1,坏,是,是,高 2,坏,是,是,高 3,坏,是,是,高 4,坏,否,是,高 5,坏,否,是,高 6,好,否,否,低 7,好,是,否,低 8,好,是,是,高 9,好,是,是,高 10,好,否,是,高 11,坏,是,是,低 12,坏,是,否,低 13,坏,否,否,低 14,好,是,是,高 15,好,是,是,高 16,好,否,是,高 17,好,否,是,高 18,坏,否,是,低 19,坏,否,是,低 20,坏,是,否,低 21,坏,是,否,低 22,好,是,是,高 23,好,否,是,高 24,好,否,是,高 25,好,否,否,低 26,坏,否,否,低 27,坏,是,否,低 28,坏,是,是,高 29,好,是,是,高 30,好,否,否,低 31,好,否,是,低 32,坏,是,是,高 33,坏,是,是,低 34,坏,是,是,低
# -*- coding:utf-8 -*- import sys reload(sys) sys.setdefaultencoding("utf-8") """ 利用ID3决策树算法预测销量高低 """ # 参数初始化 import pandas as pd data = pd.read_csv("./practice_data.csv", header=None, sep=",", names=["number", "tianqi", "weekend", "pt", "count"]) print data["tianqi"] # 数据是类别标签,要将她转换成数据 # 用1来表示"好", "是", "高"这三个属性,用-1来表示"坏","否","低" data[data["tianqi"] == u"好"] = 1 data[data["tianqi"] == u"坏"] = -1 print data["tianqi"] data[data["weekend"] == u"是"] = 1 data[data["weekend"] == u"否"] = -1 print data["weekend"] data[data["pt"] == u"是"] = 1 data[data["pt"] == u"否"] = -1 data[data["count"] == u"高"] = 1 data[data["count"] == u"低"] = -1 print data # print data x = data.iloc[:,:3].as_matrix().astype(int) y = data.iloc[:,3].as_matrix().astype(int) from sklearn.tree import DecisionTreeClassifier as DTC dtc = DTC(criterion="entropy") # 建立决策树模型, 基于信息熵 dtc.fit(x, y) # 训练模型 # 导入相关函数,可视化决策树 # 导出的结果是一个dot文件, 需要安装Graphviz才能将它转化为pdf或png等格式 from sklearn.tree import export_graphviz from sklearn.externals.six import StringIO with open("tree.dot", "w") as f: f = export_graphviz(dtc, feature_names=x.columns, out_file=f)
标签:表示 ice 标记 odi alt 就是 rap coding external
原文地址:https://www.cnblogs.com/ljc-0923/p/11755308.html